Division of Translational Research, The University of Texas Southwestern Medical Center, 5323 Harry Hines Boulevard, Dallas, TX 75290-9185, USA.
Bioinformatics. 2010 Jun 1;26(11):1453-7. doi: 10.1093/bioinformatics/btq146. Epub 2010 May 13.
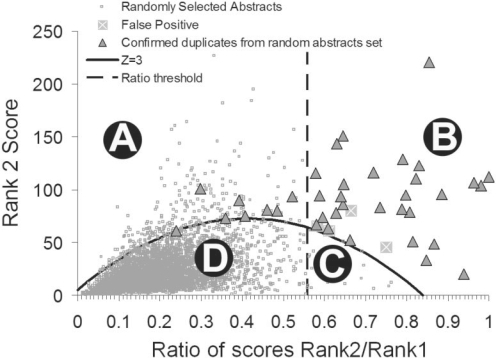
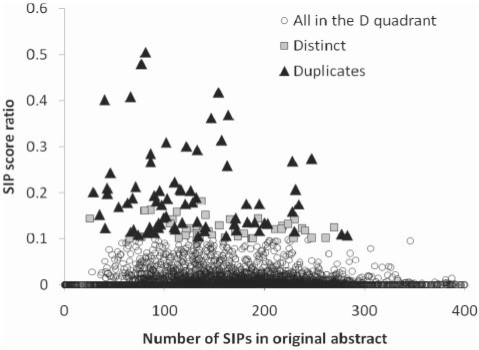
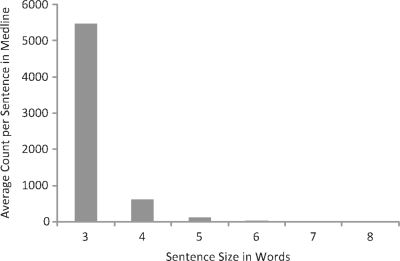
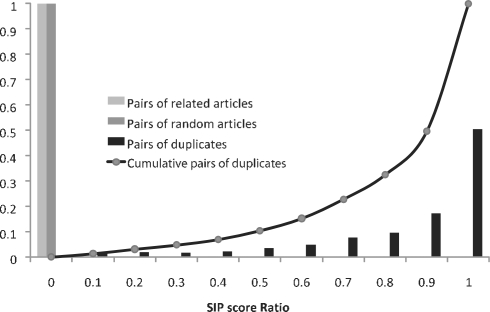
Document similarity metrics such as PubMed's 'Find related articles' feature, which have been primarily used to identify studies with similar topics, can now also be used to detect duplicated or potentially plagiarized papers within literature reference databases. However, the CPU-intensive nature of document comparison has limited MEDLINE text similarity studies to the comparison of abstracts, which constitute only a small fraction of a publication's total text. Extending searches to include text archived by online search engines would drastically increase comparison ability. For large-scale studies, submitting short phrases encased in direct quotes to search engines for exact matches would be optimal for both individual queries and programmatic interfaces. We have derived a method of analyzing statistically improbable phrases (SIPs) for assistance in identifying duplicate content.
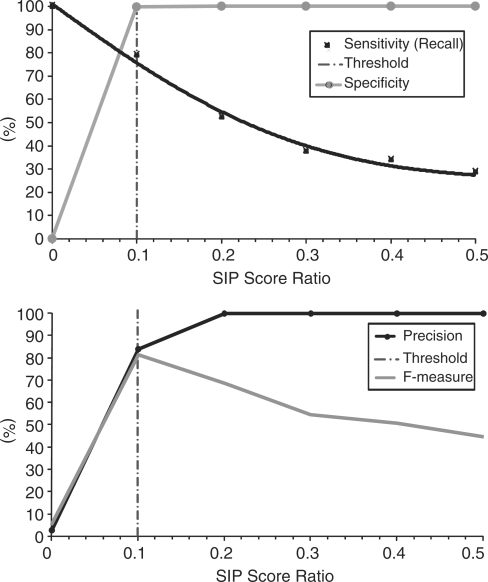
When applied to MEDLINE citations, this method substantially improves upon previous algorithms in the detection of duplication citations, yielding a precision and recall of 78.9% (versus 50.3% for eTBLAST) and 99.6% (versus 99.8% for eTBLAST), respectively.
Similar citations identified by this work are freely accessible in the Déjà vu database, under the SIP discovery method category at http://dejavu.vbi.vt.edu/dejavu/.
文献相似性指标,如 PubMed 的“查找相关文章”功能,主要用于识别具有相似主题的研究,现在也可用于检测文献参考数据库中的重复或潜在抄袭论文。然而,文档比较的 CPU 密集型性质限制了 MEDLINE 文本相似性研究仅限于摘要的比较,而摘要只构成出版物总文本的一小部分。将搜索范围扩大到包括在线搜索引擎存档的文本,将极大地提高比较能力。对于大规模研究,将短的短语用引号括起来提交给搜索引擎进行精确匹配,无论是对于单个查询还是编程接口都是最佳选择。我们已经得出一种分析统计上不可能的短语 (SIP) 的方法,以帮助识别重复内容。
当应用于 MEDLINE 引文时,该方法在检测重复引文方面大大优于以前的算法,其精度和召回率分别为 78.9%(而 eTBLAST 为 50.3%)和 99.6%(而 eTBLAST 为 99.8%)。
这项工作识别的相似引文可在 Déjà vu 数据库中免费访问,位于 http://dejavu.vbi.vt.edu/dejavu/ 下的 SIP 发现方法类别中。