Scharinger Mathias, Merickel Jennifer, Riley Joshua, Idsardi William J
Department of Linguistics, University of Maryland, College Park, MD 20742-7505, USA.
Brain Lang. 2011 Feb;116(2):71-82. doi: 10.1016/j.bandl.2010.11.002. Epub 2010 Dec 23.
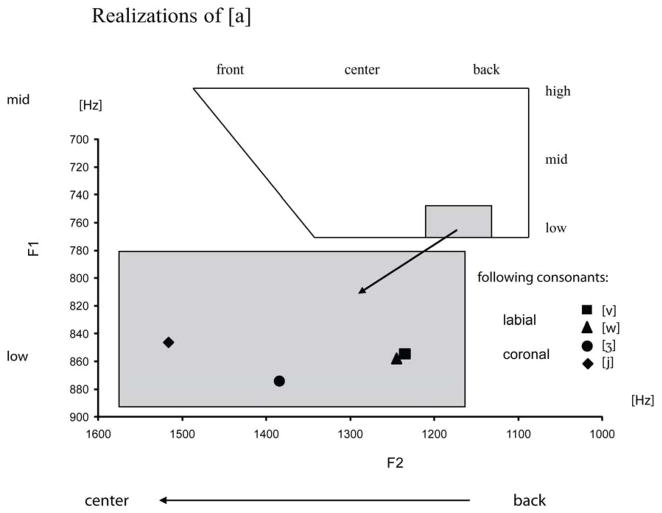
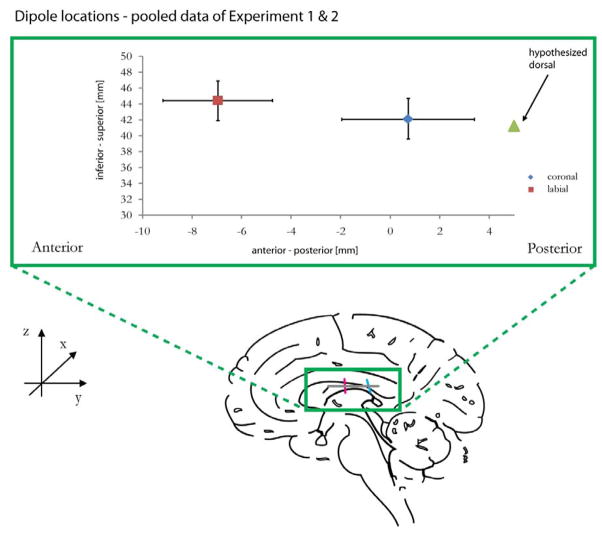
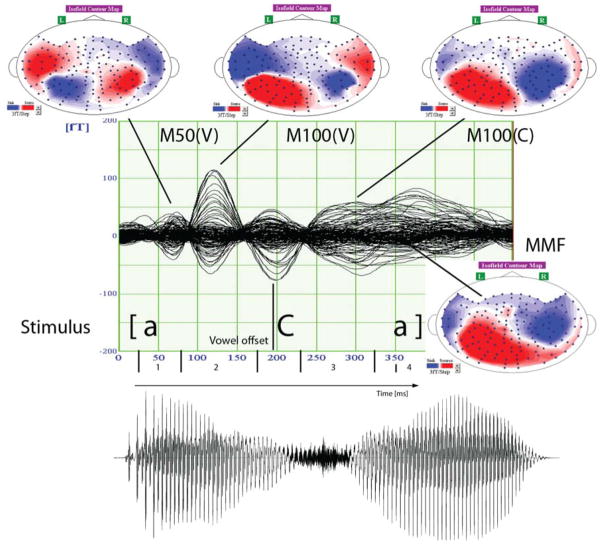
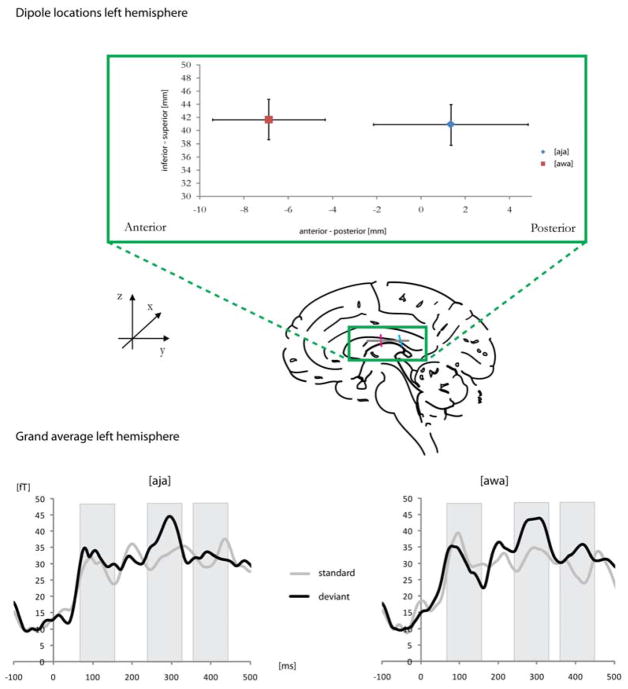
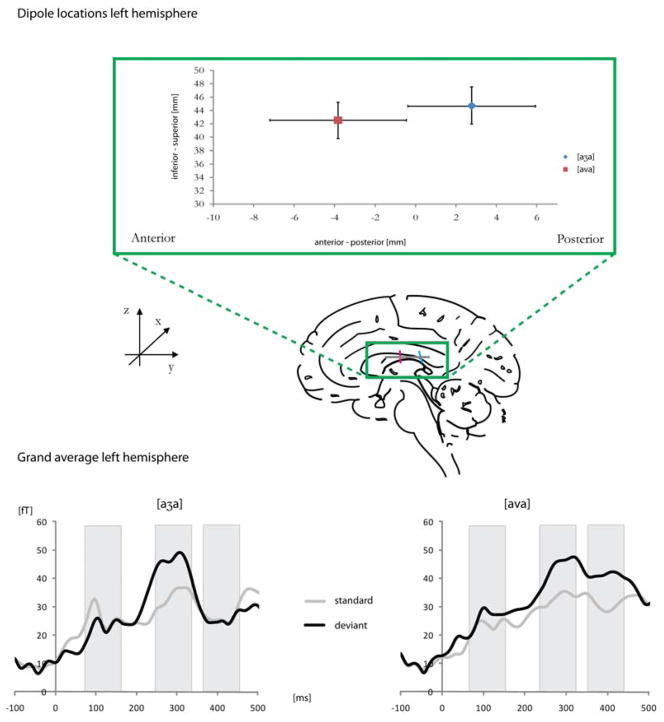
Speech sounds can be classified on the basis of their underlying articulators or on the basis of the acoustic characteristics resulting from particular articulatory positions. Research in speech perception suggests that distinctive features are based on both articulatory and acoustic information. In recent years, neuroelectric and neuromagnetic investigations provided evidence for the brain's early sensitivity to distinctive features and their acoustic consequences, particularly for place of articulation distinctions. Here, we compare English consonants in a Mismatch Field design across two broad and distinct places of articulation - labial and coronal - and provide further evidence that early evoked auditory responses are sensitive to these features. We further add to the findings of asymmetric consonant processing, although we do not find support for coronal underspecification. Labial glides (Experiment 1) and fricatives (Experiment 2) elicited larger Mismatch responses than their coronal counterparts. Interestingly, their M100 dipoles differed along the anterior/posterior dimension in the auditory cortex that has previously been found to spatially reflect place of articulation differences. Our results are discussed with respect to acoustic and articulatory bases of featural speech sound classifications and with respect to a model that maps distinctive phonetic features onto long-term representations of speech sounds.
语音可以根据其潜在的发音器官进行分类,也可以根据特定发音位置产生的声学特征进行分类。语音感知研究表明,区别特征是基于发音和声学信息的。近年来,神经电和神经磁研究为大脑对区别特征及其声学结果的早期敏感性提供了证据,特别是对于发音部位的区别。在这里,我们在失配场设计中比较了英语辅音在两个广泛且不同的发音部位——唇音和齿冠音——之间的差异,并提供了进一步的证据,表明早期诱发的听觉反应对这些特征敏感。我们进一步补充了辅音不对称加工的研究结果,尽管我们没有找到支持齿冠音特征不充分的证据。唇音滑音(实验1)和擦音(实验2)比相应的齿冠音引发了更大的失配反应。有趣的是,它们的M100偶极子在听觉皮层的前后维度上有所不同,此前已发现该维度在空间上反映了发音部位的差异。我们从语音区别特征分类的声学和发音基础以及将独特语音特征映射到语音长期表征的模型方面对我们的结果进行了讨论。