The Interdisciplinary Center for Neural Computation, The Hebrew University Jerusalem, Israel.
Front Syst Neurosci. 2011 May 9;5:22. doi: 10.3389/fnsys.2011.00022. eCollection 2011.
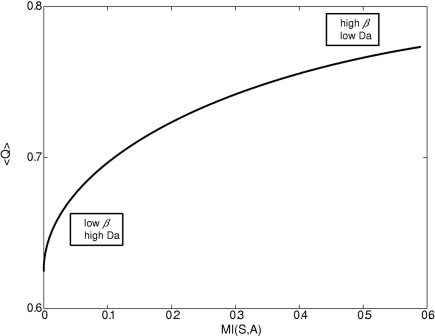
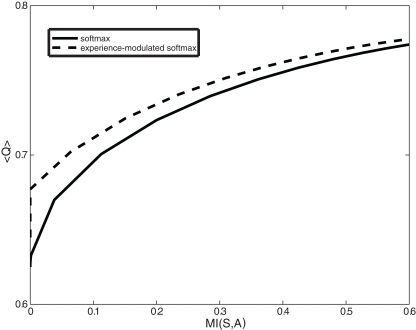
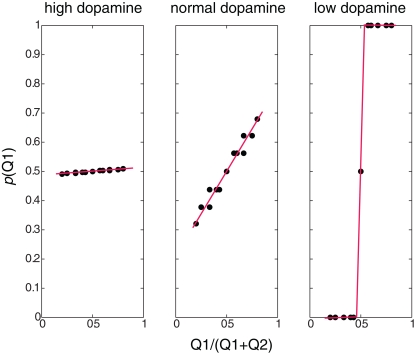
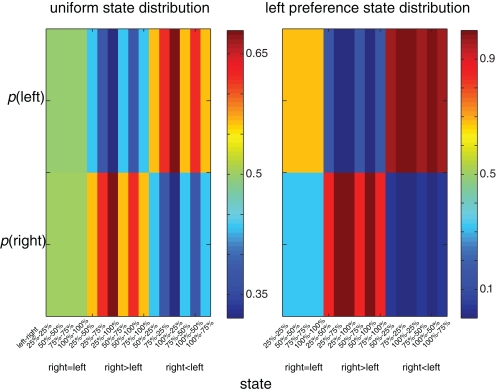
Previous reinforcement-learning models of the basal ganglia network have highlighted the role of dopamine in encoding the mismatch between prediction and reality. Far less attention has been paid to the computational goals and algorithms of the main-axis (actor). Here, we construct a top-down model of the basal ganglia with emphasis on the role of dopamine as both a reinforcement learning signal and as a pseudo-temperature signal controlling the general level of basal ganglia excitability and motor vigilance of the acting agent. We argue that the basal ganglia endow the thalamic-cortical networks with the optimal dynamic tradeoff between two constraints: minimizing the policy complexity (cost) and maximizing the expected future reward (gain). We show that this multi-dimensional optimization processes results in an experience-modulated version of the softmax behavioral policy. Thus, as in classical softmax behavioral policies, probability of actions are selected according to their estimated values and the pseudo-temperature, but in addition also vary according to the frequency of previous choices of these actions. We conclude that the computational goal of the basal ganglia is not to maximize cumulative (positive and negative) reward. Rather, the basal ganglia aim at optimization of independent gain and cost functions. Unlike previously suggested single-variable maximization processes, this multi-dimensional optimization process leads naturally to a softmax-like behavioral policy. We suggest that beyond its role in the modulation of the efficacy of the cortico-striatal synapses, dopamine directly affects striatal excitability and thus provides a pseudo-temperature signal that modulates the tradeoff between gain and cost. The resulting experience and dopamine modulated softmax policy can then serve as a theoretical framework to account for the broad range of behaviors and clinical states governed by the basal ganglia and dopamine systems.
先前关于基底神经节网络的强化学习模型强调了多巴胺在编码预测与现实之间的不匹配方面的作用。但对主要轴突(actor)的计算目标和算法的关注要少得多。在这里,我们构建了一个强调多巴胺作为强化学习信号和作为控制作用代理的基底神经节整体兴奋性和运动警觉性的伪温度信号的基底神经节的自上而下模型。我们认为基底神经节赋予丘脑-皮层网络在两个约束之间进行最佳动态权衡的能力:最小化策略复杂度(成本)和最大化预期未来奖励(收益)。我们表明,这个多维优化过程导致了经验调制的软最大化行为策略。因此,与经典的软最大化行为策略一样,根据估计值和伪温度选择动作的概率,但此外还根据这些动作的先前选择的频率而变化。我们得出结论,基底神经节的计算目标不是最大化累积(正和负)奖励。相反,基底神经节旨在优化独立的收益和成本函数。与之前提出的单变量最大化过程不同,这个多维优化过程自然导致了类似于软最大化的行为策略。我们建议,除了在调制皮质-纹状体突触的效能方面的作用外,多巴胺还直接影响纹状体的兴奋性,并因此提供了一种伪温度信号,调节收益和成本之间的权衡。然后,由此产生的经验和多巴胺调制的软最大化策略可以作为一个理论框架,解释由基底神经节和多巴胺系统控制的广泛的行为和临床状态。