Department of Computer Science, University of Victoria, Victoria, Canada.
BMC Bioinformatics. 2011 Jun 9;12 Suppl 3(Suppl 3):S1. doi: 10.1186/1471-2105-12-S3-S1.
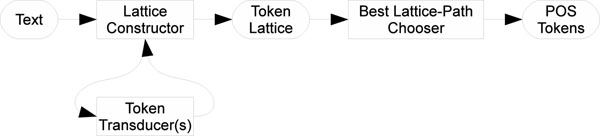
Tokenization is an important component of language processing yet there is no widely accepted tokenization method for English texts, including biomedical texts. Other than rule based techniques, tokenization in the biomedical domain has been regarded as a classification task. Biomedical classifier-based tokenizers either split or join textual objects through classification to form tokens. The idiosyncratic nature of each biomedical tokenizer's output complicates adoption and reuse. Furthermore, biomedical tokenizers generally lack guidance on how to apply an existing tokenizer to a new domain (subdomain). We identify and complete a novel tokenizer design pattern and suggest a systematic approach to tokenizer creation. We implement a tokenizer based on our design pattern that combines regular expressions and machine learning. Our machine learning approach differs from the previous split-join classification approaches. We evaluate our approach against three other tokenizers on the task of tokenizing biomedical text.
Medpost and our adapted Viterbi tokenizer performed best with a 92.9% and 92.4% accuracy respectively.
Our evaluation of our design pattern and guidelines supports our claim that the design pattern and guidelines are a viable approach to tokenizer construction (producing tokenizers matching leading custom-built tokenizers in a particular domain). Our evaluation also demonstrates that ambiguous tokenizations can be disambiguated through POS tagging. In doing so, POS tag sequences and training data have a significant impact on proper text tokenization.
标记化是语言处理的一个重要组成部分,但目前还没有被广泛接受的英语文本(包括生物医学文本)标记化方法。除了基于规则的技术外,生物医学领域的标记化一直被视为分类任务。生物医学分类器的标记器通过分类来分割或合并文本对象以形成标记。每个生物医学标记器输出的特殊性使得采用和重用变得复杂。此外,生物医学标记器通常缺乏关于如何将现有标记器应用于新领域(子领域)的指导。我们确定并完成了一种新的标记器设计模式,并提出了一种创建标记器的系统方法。我们实现了一个基于我们的设计模式的标记器,该标记器结合了正则表达式和机器学习。我们的机器学习方法与以前的分割-合并分类方法不同。我们在生物医学文本标记任务上评估了我们的方法与其他三个标记器的比较。
Medpost 和我们改编的维特比标记器的准确率分别为 92.9%和 92.4%。
我们对设计模式和指南的评估支持我们的主张,即设计模式和指南是构建标记器的可行方法(生成的标记器在特定领域与领先的定制标记器匹配)。我们的评估还表明,通过词性标注可以消除歧义标记。这样,词性标记序列和训练数据对正确的文本标记化有重大影响。