Structural Computational Biology Group, Structural Biology and BioComputing Programme, Spanish National Cancer Research Centre, Calle Melchor Fernndez Almagro, 3, Madrid, Spain.
Computational Intelligence Group, Department of Artificial Intelligence, Universidad Politecnica de Madrid, Calle Ramiro de Maeztu, 7, Madrid, Spain.
J Cheminform. 2015 Jan 19;7(Suppl 1 Text mining for chemistry and the CHEMDNER track):S1. doi: 10.1186/1758-2946-7-S1-S1. eCollection 2015.
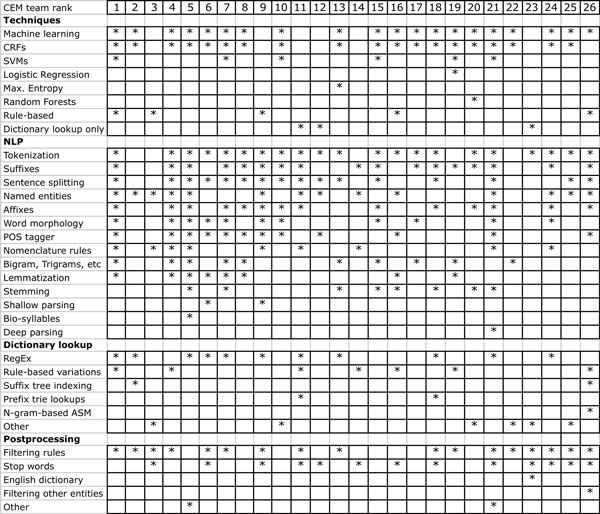
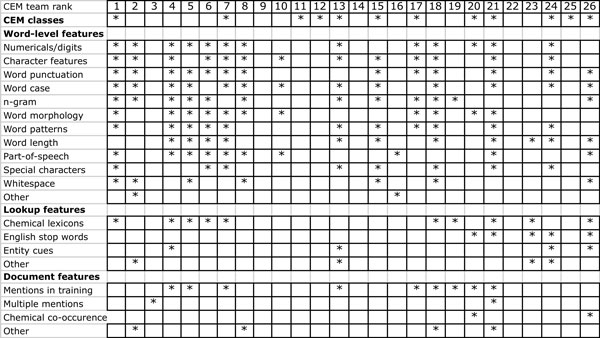
Natural language processing (NLP) and text mining technologies for the chemical domain (ChemNLP or chemical text mining) are key to improve the access and integration of information from unstructured data such as patents or the scientific literature. Therefore, the BioCreative organizers posed the CHEMDNER (chemical compound and drug name recognition) community challenge, which promoted the development of novel, competitive and accessible chemical text mining systems. This task allowed a comparative assessment of the performance of various methodologies using a carefully prepared collection of manually labeled text prepared by specially trained chemists as Gold Standard data. We evaluated two important aspects: one covered the indexing of documents with chemicals (chemical document indexing - CDI task), and the other was concerned with finding the exact mentions of chemicals in text (chemical entity mention recognition - CEM task). 27 teams (23 academic and 4 commercial, a total of 87 researchers) returned results for the CHEMDNER tasks: 26 teams for CEM and 23 for the CDI task. Top scoring teams obtained an F-score of 87.39% for the CEM task and 88.20% for the CDI task, a very promising result when compared to the agreement between human annotators (91%). The strategies used to detect chemicals included machine learning methods (e.g. conditional random fields) using a variety of features, chemistry and drug lexica, and domain-specific rules. We expect that the tools and resources resulting from this effort will have an impact in future developments of chemical text mining applications and will form the basis to find related chemical information for the detected entities, such as toxicological or pharmacogenomic properties.
自然语言处理(NLP)和化学领域的文本挖掘技术(ChemNLP 或化学文本挖掘)是提高对非结构化数据(如专利或科学文献)中信息的访问和集成的关键。因此,BioCreative 组织者提出了 CHEMDNER(化学化合物和药物名称识别)社区挑战,这促进了新型、有竞争力和易于使用的化学文本挖掘系统的发展。该任务允许使用专门训练的化学家精心准备的手工标记文本的集合,通过比较评估各种方法的性能,作为黄金标准数据。我们评估了两个重要方面:一个涵盖了带有化学物质的文档索引(化学文档索引-CDI 任务),另一个关注于在文本中找到化学物质的确切提及(化学实体提及识别-CEM 任务)。27 个团队(23 个学术团队和 4 个商业团队,共有 87 名研究人员)对 CHEMDNER 任务返回了结果:26 个团队用于 CEM 任务,23 个团队用于 CDI 任务。得分最高的团队在 CEM 任务中获得了 87.39%的 F 分数,在 CDI 任务中获得了 88.20%的 F 分数,与人类注释者之间的一致性(91%)相比,这是一个非常有前途的结果。用于检测化学物质的策略包括使用各种特征、化学和药物词典以及特定于领域的规则的机器学习方法(例如条件随机场)。我们预计,这项工作产生的工具和资源将对未来化学文本挖掘应用的发展产生影响,并为检测到的实体找到相关的化学信息,例如毒理学或药物基因组学特性奠定基础。