Department of Computer Science, The University of Iowa, Iowa City, IA 52242, USA.
Bioinformatics. 2011 Jul 1;27(13):i120-8. doi: 10.1093/bioinformatics/btr223.
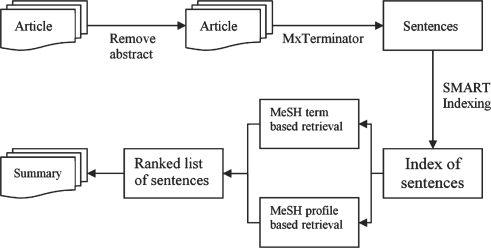
Previous research in the biomedical text-mining domain has historically been limited to titles, abstracts and metadata available in MEDLINE records. Recent research initiatives such as TREC Genomics and BioCreAtIvE strongly point to the merits of moving beyond abstracts and into the realm of full texts. Full texts are, however, more expensive to process not only in terms of resources needed but also in terms of accuracy. Since full texts contain embellishments that elaborate, contextualize, contrast, supplement, etc., there is greater risk for false positives. Motivated by this, we explore an approach that offers a compromise between the extremes of abstracts and full texts. Specifically, we create reduced versions of full text documents that contain only important portions. In the long-term, our goal is to explore the use of such summaries for functions such as document retrieval and information extraction. Here, we focus on designing summarization strategies. In particular, we explore the use of MeSH terms, manually assigned to documents by trained annotators, as clues to select important text segments from the full text documents.
Our experiments confirm the ability of our approach to pick the important text portions. Using the ROUGE measures for evaluation, we were able to achieve maximum ROUGE-1, ROUGE-2 and ROUGE-SU4 F-scores of 0.4150, 0.1435 and 0.1782, respectively, for our MeSH term-based method versus the maximum baseline scores of 0.3815, 0.1353 and 0.1428, respectively. Using a MeSH profile-based strategy, we were able to achieve maximum ROUGE F-scores of 0.4320, 0.1497 and 0.1887, respectively. Human evaluation of the baselines and our proposed strategies further corroborates the ability of our method to select important sentences from the full texts.
sanmitra-bhattacharya@uiowa.edu; padmini-srinivasan@uiowa.edu.
以前的生物医学文本挖掘领域的研究一直局限于 MEDLINE 记录中的标题、摘要和元数据。最近的研究计划,如 TREC 基因组学和 BioCreAtIvE,强烈表明超越摘要进入全文领域的优点。然而,由于需要更多的资源,以及更高的准确性,处理全文更加昂贵。由于全文包含详细说明、上下文化、对比、补充等内容,因此错误率更高。鉴于此,我们探索了一种在摘要和全文之间取得平衡的方法。具体来说,我们创建仅包含重要部分的全文文档的简化版本。从长远来看,我们的目标是探索使用这些摘要来实现文档检索和信息提取等功能。在这里,我们专注于设计摘要策略。特别是,我们探索了使用由训练有素的注释者手动分配给文档的 MeSH 术语作为从全文文档中选择重要文本段的线索。
我们的实验证实了我们的方法选择重要文本部分的能力。使用 ROUGE 度量进行评估,我们的 MeSH 术语方法分别实现了最大 ROUGE-1、ROUGE-2 和 ROUGE-SU4 F 分数 0.4150、0.1435 和 0.1782,而最大基线分数分别为 0.3815、0.1353 和 0.1428。使用 MeSH 配置文件策略,我们能够实现最大 ROUGE F 分数分别为 0.4320、0.1497 和 0.1887。对基线和我们提出的策略的人工评估进一步证实了我们的方法从全文中选择重要句子的能力。
sanmitra-bhattacharya@uiowa.edu;padmini-srinivasan@uiowa.edu。