Department of Biostatistics, Boston University School of Public Health, 801 Massachusetts Avenue, Boston MA 02118, USA.
BMC Genet. 2011 Jul 19;12:64. doi: 10.1186/1471-2156-12-64.
There are many ways to perform adjustment for population structure. It remains unclear what the optimal approach is and whether the optimal approach varies by the type of samples and substructure present. The simplest and most straightforward approach is to adjust for the continuous principal components (PCs) that capture ancestry. Through simulation, we explored the issue of which ancestry informative PCs should be adjusted for in an association model to control for the confounding nature of population structure while maintaining maximum power. A thorough examination of selecting PCs for adjustment in a case-control study across the possible structure scenarios that could occur in a genome-wide association study has not been previously reported.
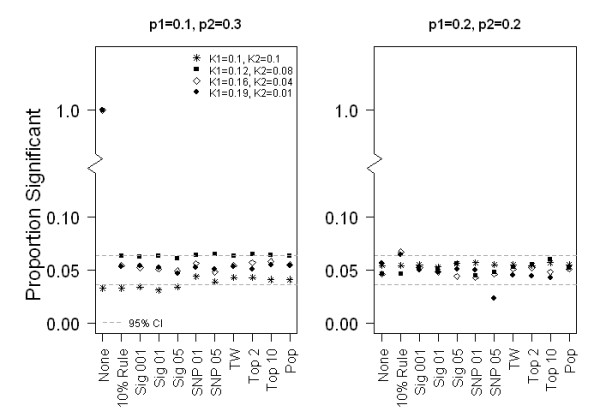
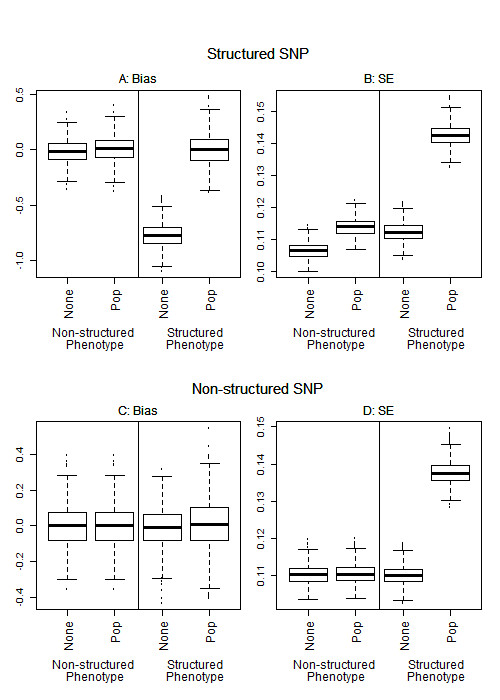
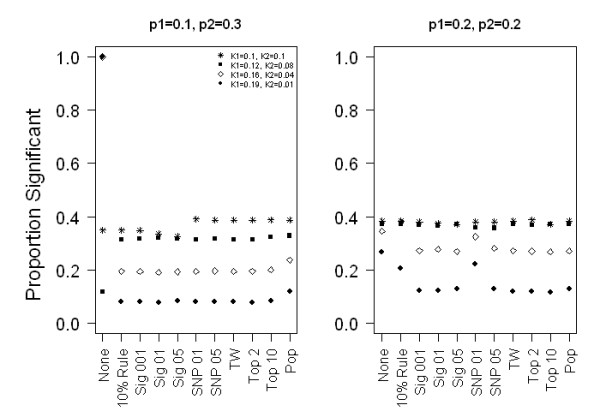
We found that when the SNP and phenotype frequencies do not vary over the sub-populations, all methods of selection provided similar power and appropriate Type I error for association. When the SNP is not structured and the phenotype has large structure, then selection methods that do not select PCs for inclusion as covariates generally provide the most power. When there is a structured SNP and a non-structured phenotype, selection methods that include PCs in the model have greater power. When both the SNP and the phenotype are structured, all methods of selection have similar power.
Standard practice is to include a fixed number of PCs in genome-wide association studies. Based on our findings, we conclude that if power is not a concern, then selecting the same set of top PCs for adjustment for all SNPs in logistic regression is a strategy that achieves appropriate Type I error. However, standard practice is not optimal in all scenarios and to optimize power for structured SNPs in the presence of unstructured phenotypes, PCs that are associated with the tested SNP should be included in the logistic model.
有许多方法可以进行群体结构调整。目前尚不清楚哪种方法是最优的,以及最优方法是否因样本类型和存在的亚结构而异。最简单和最直接的方法是调整捕获祖先的连续主成分(PCs)。通过模拟,我们探讨了在关联模型中应调整哪些与祖先有关的 PC 以控制群体结构的混杂性质,同时保持最大功效的问题。以前没有报道过在全基因组关联研究中可能出现的结构情况下,对病例对照研究中调整 PC 的方法进行全面检查。
我们发现,当 SNP 和表型频率在亚群中不变化时,所有选择方法都提供了相似的功效和适当的关联Ⅰ型错误。当 SNP 没有结构而表型有很大的结构时,不选择 PC 作为协变量的选择方法通常提供最大的功效。当 SNP 是结构的而表型是非结构的时,将 PC 纳入模型的选择方法具有更高的功效。当 SNP 和表型都有结构时,所有选择方法都具有相似的功效。
标准实践是在全基因组关联研究中包含固定数量的 PCs。根据我们的发现,如果功效不是问题,那么在逻辑回归中为所有 SNP 选择相同的一组最佳 PC 进行调整是一种达到适当Ⅰ型错误的策略。然而,在所有情况下,标准实践并不都是最优的,为了优化存在非结构化表型的结构化 SNP 的功效,应将与测试 SNP 相关的 PC 纳入逻辑模型。