Lorenzi Hernan A, Hoover Jeff, Inman Jason, Safford Todd, Murphy Sean, Kagan Leonid, Williamson Shannon J
Stand Genomic Sci. 2011 Jul 1;4(3):418-29. doi: 10.4056/sigs.1694706. Epub 2011 Jun 30.
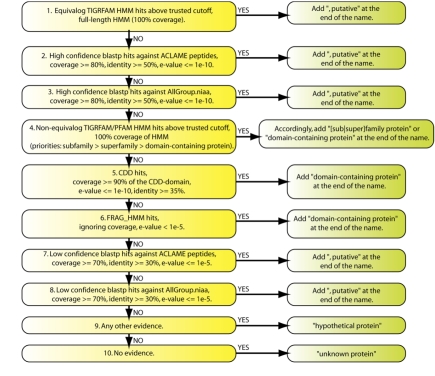
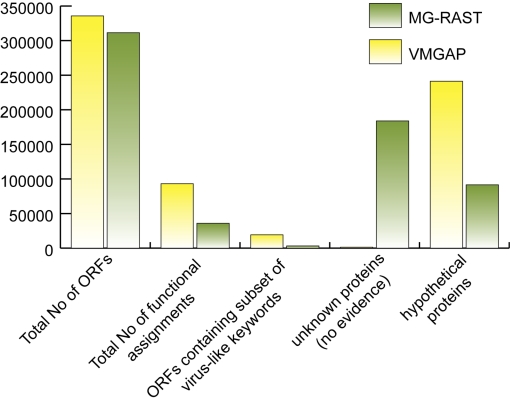
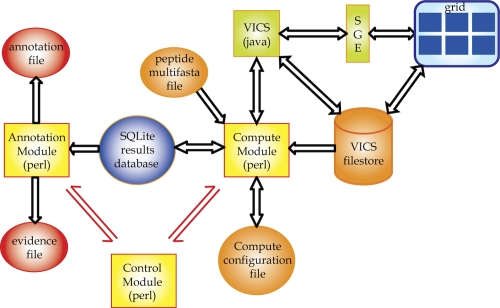
In the past few years, the field of metagenomics has been growing at an accelerated pace, particularly in response to advancements in new sequencing technologies. The large volume of sequence data from novel organisms generated by metagenomic projects has triggered the development of specialized databases and tools focused on particular groups of organisms or data types. Here we describe a pipeline for the functional annotation of viral metagenomic sequence data. The Viral MetaGenome Annotation Pipeline (VMGAP) pipeline takes advantage of a number of specialized databases, such as collections of mobile genetic elements and environmental metagenomes to improve the classification and functional prediction of viral gene products. The pipeline assigns a functional term to each predicted protein sequence following a suite of comprehensive analyses whose results are ranked according to a priority rules hierarchy. Additional annotation is provided in the form of enzyme commission (EC) numbers, GO/MeGO terms and Hidden Markov Models together with supporting evidence.
在过去几年中,宏基因组学领域一直在加速发展,特别是为了应对新测序技术的进步。宏基因组项目产生的来自新型生物体的大量序列数据引发了专注于特定生物体群体或数据类型的专业数据库和工具的开发。在这里,我们描述了一种用于病毒宏基因组序列数据功能注释的流程。病毒宏基因组注释流程(VMGAP)利用了许多专业数据库,如移动遗传元件集合和环境宏基因组,以改进病毒基因产物的分类和功能预测。该流程在一系列综合分析之后为每个预测的蛋白质序列赋予一个功能术语,其结果根据优先级规则层次进行排序。以酶委员会(EC)编号、GO/MeGO术语和隐马尔可夫模型的形式提供额外注释以及支持证据。