State Key Laboratory of Bioelectronics, School of Biological Science and Medical Engineering, Southeast University, Nanjing, China.
DNA Res. 2011 Dec;18(6):435-49. doi: 10.1093/dnares/dsr030. Epub 2011 Sep 8.
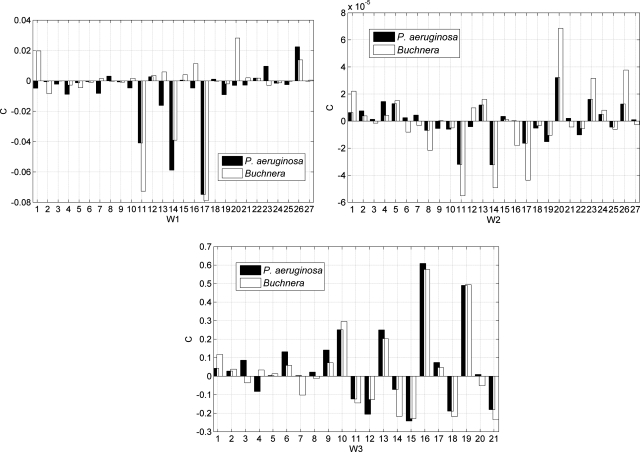
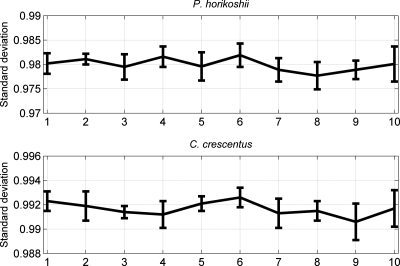
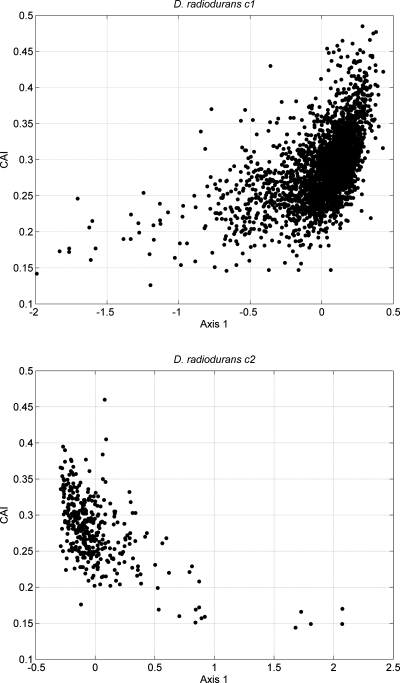
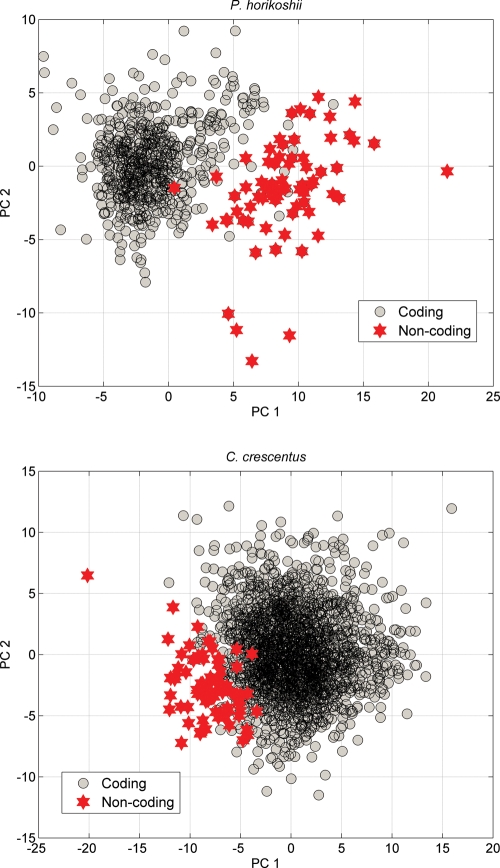
The falsely annotated protein-coding genes have been deemed one of the major causes accounting for the annotating errors in public databases. Although many filtering approaches have been designed for the over-annotated protein-coding genes, some are questionable due to the resultant increase in false negative. Furthermore, there is no webserver or software specifically devised for the problem of over-annotation. In this study, we propose an integrative algorithm for detecting the over-annotated protein-coding genes in microorganisms. Overall, an average accuracy of 99.94% is achieved over 61 microbial genomes. The extremely high accuracy indicates that the presented algorithm is efficient to differentiate the protein-coding genes from the non-coding open reading frames. Abundant analyses show that the predicting results are reliable and the integrative algorithm is robust and convenient. Our analysis also indicates that the over-annotated protein-coding genes can cause the false positive of horizontal gene transfers detection. The webserver of the proposed algorithm can be freely accessible from www.cbi.seu.edu.cn/RPGM.
错误注释的蛋白编码基因被认为是导致公共数据库注释错误的主要原因之一。尽管已经设计了许多过滤方法来过滤过度注释的蛋白编码基因,但由于假阴性的增加,其中一些方法存在疑问。此外,目前还没有专门针对过度注释问题设计的网络服务器或软件。在本研究中,我们提出了一种用于检测微生物中过度注释的蛋白编码基因的综合算法。总的来说,在 61 个微生物基因组上的平均准确率达到了 99.94%。极高的准确率表明,所提出的算法能够有效地将蛋白编码基因与非编码开放阅读框区分开来。大量的分析表明,预测结果是可靠的,综合算法是稳健和方便的。我们的分析还表明,过度注释的蛋白编码基因可能导致水平基因转移检测的假阳性。该算法的网络服务器可以从 www.cbi.seu.edu.cn/RPGM 免费访问。