Faculty of Life Sciences, University of Manchester, Manchester, United Kingdom.
PLoS One. 2011;6(9):e24716. doi: 10.1371/journal.pone.0024716. Epub 2011 Sep 29.
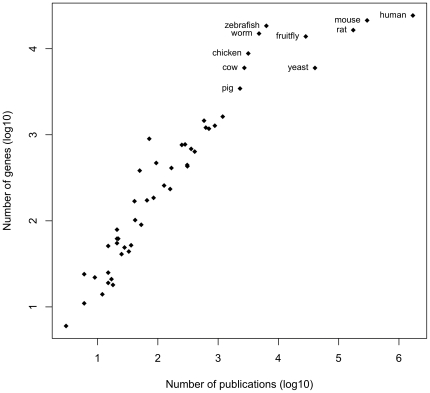
The last two decades have witnessed a dramatic acceleration in the production of genomic sequence information and publication of biomedical articles. Despite the fact that genome sequence data and publications are two of the most heavily relied-upon sources of information for many biologists, very little effort has been made to systematically integrate data from genomic sequences directly with the biological literature. For a limited number of model organisms dedicated teams manually curate publications about genes; however for species with no such dedicated staff many thousands of articles are never mapped to genes or genomic regions.
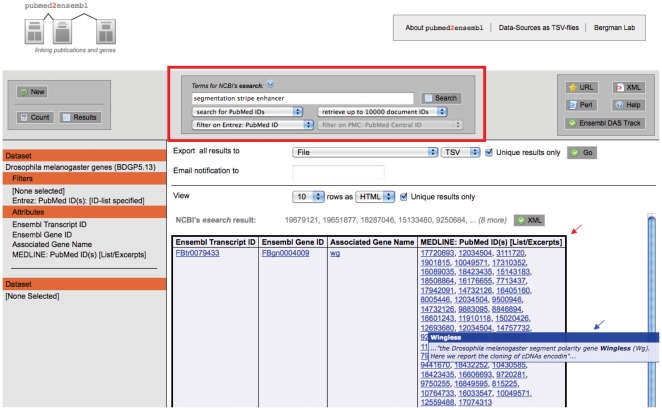
METHODOLOGY/PRINCIPAL FINDINGS: To overcome the lack of integration between genomic data and biological literature, we have developed pubmed2ensembl (http://www.pubmed2ensembl.org), an extension to the BioMart system that links over 2,000,000 articles in PubMed to nearly 150,000 genes in Ensembl from 50 species. We use several sources of curated (e.g., Entrez Gene) and automatically generated (e.g., gene names extracted through text-mining on MEDLINE records) sources of gene-publication links, allowing users to filter and combine different data sources to suit their individual needs for information extraction and biological discovery. In addition to extending the Ensembl BioMart database to include published information on genes, we also implemented a scripting language for automated BioMart construction and a novel BioMart interface that allows text-based queries to be performed against PubMed and PubMed Central documents in conjunction with constraints on genomic features. Finally, we illustrate the potential of pubmed2ensembl through typical use cases that involve integrated queries across the biomedical literature and genomic data.
CONCLUSION/SIGNIFICANCE: By allowing biologists to find the relevant literature on specific genomic regions or sets of functionally related genes more easily, pubmed2ensembl offers a much-needed genome informatics inspired solution to accessing the ever-increasing biomedical literature.
在过去的二十年中,基因组序列信息的产生和生物医学文献的发表呈现出急剧加速的趋势。尽管基因组序列数据和出版物是许多生物学家最依赖的信息来源之一,但很少有人努力系统地将来自基因组序列的数据直接与生物文献整合。对于少数几个有专门团队的模式生物,他们会手动整理有关基因的出版物;然而,对于没有专门人员的物种,成千上万的文章从未被映射到基因或基因组区域。
方法/主要发现:为了克服基因组数据与生物文献之间缺乏整合的问题,我们开发了 pubmed2ensembl(http://www.pubmed2ensembl.org),这是 BioMart 系统的一个扩展,将 PubMed 中的超过 200 万篇文章与 Ensembl 中的近 15 万条基因链接起来,这些基因来自 50 个物种。我们使用了几种经过精心整理的基因-出版物链接来源(例如,Entrez Gene)和自动生成的来源(例如,通过对 MEDLINE 记录进行文本挖掘提取的基因名称),允许用户过滤和组合不同的数据源,以满足他们个人对信息提取和生物发现的需求。除了将 Ensembl BioMart 数据库扩展到包含有关基因的已发表信息外,我们还实现了一个用于自动化 BioMart 构建的脚本语言,以及一个新颖的 BioMart 接口,该接口允许针对 PubMed 和 PubMed Central 文档执行基于文本的查询,并结合对基因组特征的约束。最后,我们通过典型的用例来说明 pubmed2ensembl 的潜力,这些用例涉及跨生物医学文献和基因组数据的集成查询。
结论/意义:通过允许生物学家更容易地找到特定基因组区域或功能相关基因集的相关文献,pubmed2ensembl 提供了一种急需的基于基因组信息学的解决方案,以访问不断增加的生物医学文献。