Interdisciplinary Centre for Mathematical and Computational Modelling, University of Warsaw, 02-106 Warsaw, Poland.
Amino Acids. 2012 Aug;43(2):583-94. doi: 10.1007/s00726-011-1106-9. Epub 2011 Oct 13.
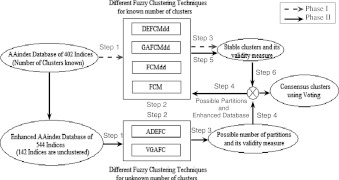
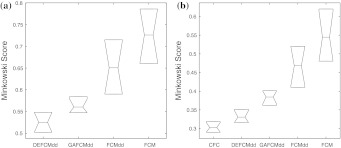
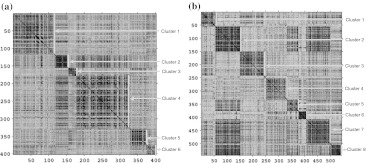
In this article, we categorize presently available experimental and theoretical knowledge of various physicochemical and biochemical features of amino acids, as collected in the AAindex database of known 544 amino acid (AA) indices. Previously reported 402 indices were categorized into six groups using hierarchical clustering technique and 142 were left unclustered. However, due to the increasing diversity of the database these indices are overlapping, therefore crisp clustering method may not provide optimal results. Moreover, in various large-scale bioinformatics analyses of whole proteomes, the proper selection of amino acid indices representing their biological significance is crucial for efficient and error-prone encoding of the short functional sequence motifs. In most cases, researchers perform exhaustive manual selection of the most informative indices. These two facts motivated us to analyse the widely used AA indices. The main goal of this article is twofold. First, we present a novel method of partitioning the bioinformatics data using consensus fuzzy clustering, where the recently proposed fuzzy clustering techniques are exploited. Second, we prepare three high quality subsets of all available indices. Superiority of the consensus fuzzy clustering method is demonstrated quantitatively, visually and statistically by comparing it with the previously proposed hierarchical clustered results. The processed AAindex1 database, supplementary material and the software are available at http://sysbio.icm.edu.pl/aaindex/ .
在本文中,我们对已知的 544 种氨基酸(AA)指数的 AAindex 数据库中收集到的各种物理化学和生化特性的现有实验和理论知识进行了分类。先前报道的 402 个指数使用层次聚类技术分为六组,还有 142 个未聚类。然而,由于数据库的多样性不断增加,这些指数存在重叠,因此,清晰聚类方法可能无法提供最佳结果。此外,在对整个蛋白质组进行各种大规模的生物信息学分析时,选择代表其生物学意义的氨基酸指数对于有效且易于出错地对短功能序列基元进行编码至关重要。在大多数情况下,研究人员会手动选择最具信息量的指数。这两个事实促使我们对广泛使用的 AA 指数进行分析。本文的主要目标有两个。首先,我们提出了一种使用共识模糊聚类对生物信息学数据进行分区的新方法,其中利用了最近提出的模糊聚类技术。其次,我们准备了所有可用指数的三个高质量子集。通过与先前提出的层次聚类结果进行定量、可视化和统计学比较,证明了共识模糊聚类方法的优越性。处理后的 AAindex1 数据库、补充材料和软件可在 http://sysbio.icm.edu.pl/aaindex/ 上获得。