National Center for Biotechnology Information, National Library of Medicine, Bethesda, Maryland 20894, USA.
Bioinformatics. 2011 Dec 1;27(23):3306-12. doi: 10.1093/bioinformatics/btr573. Epub 2011 Oct 13.
Research in the biomedical domain can have a major impact through open sharing of the data produced. For this reason, it is important to be able to identify instances of data production and deposition for potential re-use. Herein, we report on the automatic identification of data deposition statements in research articles.
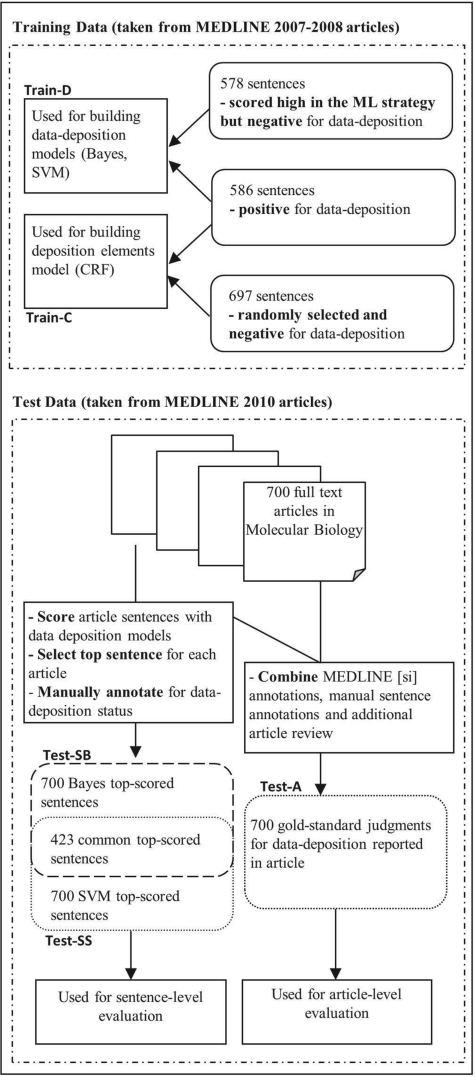
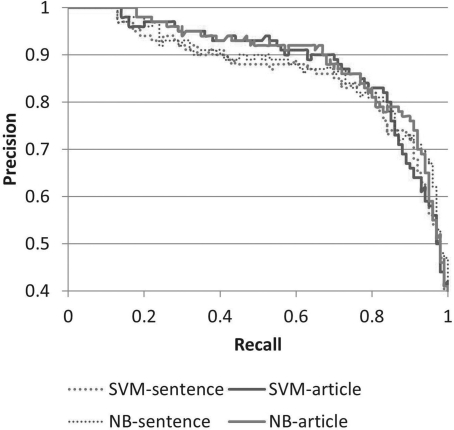
We apply machine learning algorithms to sentences extracted from full-text articles in PubMed Central in order to automatically determine whether a given article contains a data deposition statement, and retrieve the specific statements. With an Support Vector Machine classifier using conditional random field determined deposition features, articles containing deposition statements are correctly identified with 81% F-measure. An error analysis shows that almost half of the articles classified as containing a deposition statement by our method but not by the gold standard do indeed contain a deposition statement. In addition, our system was used to process articles in PubMed Central, predicting that a total of 52 932 articles report data deposition, many of which are not currently included in the Secondary Source Identifier [si] field for MEDLINE citations.
All annotated datasets described in this study are freely available from the NLM/NCBI website at http://www.ncbi.nlm.nih.gov/CBBresearch/Fellows/Neveol/DepositionDataSets.zip
aurelie.neveol@nih.gov; john.wilbur@nih.gov; zhiyong.lu@nih.gov
Supplementary data are available at Bioinformatics online.
通过开放共享所产生的数据,生物医学领域的研究可以产生重大影响。出于这个原因,能够识别数据产生和存储的实例以便潜在地重用是很重要的。在此,我们报告了在研究文章中自动识别数据存储声明的方法。
我们应用机器学习算法来处理从 PubMed Central 中的全文文章中提取的句子,以便自动确定给定的文章是否包含数据存储声明,并检索特定的声明。使用基于支持向量机的分类器和条件随机场确定的存储特征,包含存储声明的文章的正确识别率为 81%的 F 度量。错误分析表明,我们的方法分类为包含存储声明的文章中,有近一半实际上确实包含存储声明,但这些文章未被黄金标准所识别。此外,我们的系统还用于处理 PubMed Central 中的文章,预测共有 52932 篇文章报告了数据存储,其中许多文章目前并未包含在 MEDLINE 引用的二级来源标识符[si]字段中。
本研究中描述的所有注释数据集均可从 NLM/NCBI 网站免费获得,网址为 http://www.ncbi.nlm.nih.gov/CBBresearch/Fellows/Neveol/DepositionDataSets.zip。
aurelie.neveol@nih.gov; john.wilbur@nih.gov; zhiyong.lu@nih.gov
补充数据可在 Bioinformatics 在线获取。