State Key Laboratory for Molecular Virology and Genetic Engineering, Institute of Pathogen Biology, Chinese Academy of Medical Sciences & Peking Union Medical College, Beijing, PR China.
BMC Genomics. 2011 Oct 28;12:528. doi: 10.1186/1471-2164-12-528.
New strategies for high-throughput sequencing are constantly appearing, leading to a great increase in the number of completely sequenced genomes. Unfortunately, computational genome annotation is out of step with this progress. Thus, the accurate annotation of these genomes has become a bottleneck of knowledge acquisition.
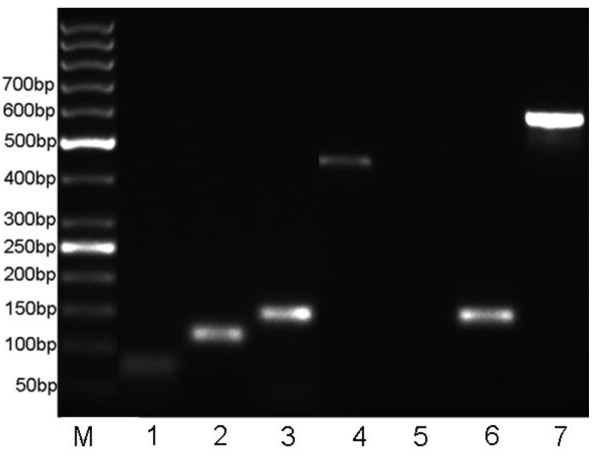
We exploited a proteogenomic approach to improve conventional genome annotation by integrating proteomic data with genomic information. Using Shigella flexneri 2a as a model, we identified total 823 proteins, including 187 hypothetical proteins. Among them, three annotated ORFs were extended upstream through comprehensive analysis against an in-house N-terminal extension database. Two genes, which could not be translated to their full length because of stop codon 'mutations' induced by genome sequencing errors, were revised and annotated as fully functional genes. Above all, seven new ORFs were discovered, which were not predicted in S. flexneri 2a str.301 by any other annotation approaches. The transcripts of four novel ORFs were confirmed by RT-PCR assay. Additionally, most of these novel ORFs were overlapping genes, some even nested within the coding region of other known genes.
Our findings demonstrate that current Shigella genome annotation methods are not perfect and need to be improved. Apart from the validation of predicted genes at the protein level, the additional features of proteogenomic tools include revision of annotation errors and discovery of novel ORFs. The complementary dataset could provide more targets for those interested in Shigella to perform functional studies.
高通量测序的新策略不断涌现,导致完全测序基因组的数量大幅增加。不幸的是,计算基因组注释与这一进展不同步。因此,这些基因组的准确注释已成为知识获取的瓶颈。
我们利用蛋白质基因组学方法通过将蛋白质组数据与基因组信息相结合来改进传统的基因组注释。我们以福氏志贺菌 2a 为模型,共鉴定出 823 种蛋白质,包括 187 种假定蛋白质。其中,通过综合分析内部 N 端延伸数据库,对三个注释的 ORF 进行了上游延伸。由于基因组测序错误引起的“突变”导致两个基因无法翻译为全长,我们对这两个基因进行了修正和注释,使其成为完全功能的基因。最重要的是,发现了七个新的 ORF,这些 ORF 无法通过任何其他注释方法预测到福氏志贺菌 2a str.301 中。通过 RT-PCR 检测证实了四个新 ORF 的转录本。此外,这些新的 ORF 中的大多数是重叠基因,有些甚至嵌套在其他已知基因的编码区内。
我们的研究结果表明,目前的志贺氏菌基因组注释方法并不完善,需要改进。除了在蛋白质水平上验证预测基因外,蛋白质基因组学工具的附加功能还包括注释错误的修正和新 ORF 的发现。互补数据集可以为那些对志贺氏菌感兴趣的人提供更多的功能研究目标。