Barbara Davis Center for Childhood Diabetes, University of Colorado Denver, Denver, CO 80045, USA.
J Transl Med. 2012 Feb 27;10:32. doi: 10.1186/1479-5876-10-32.
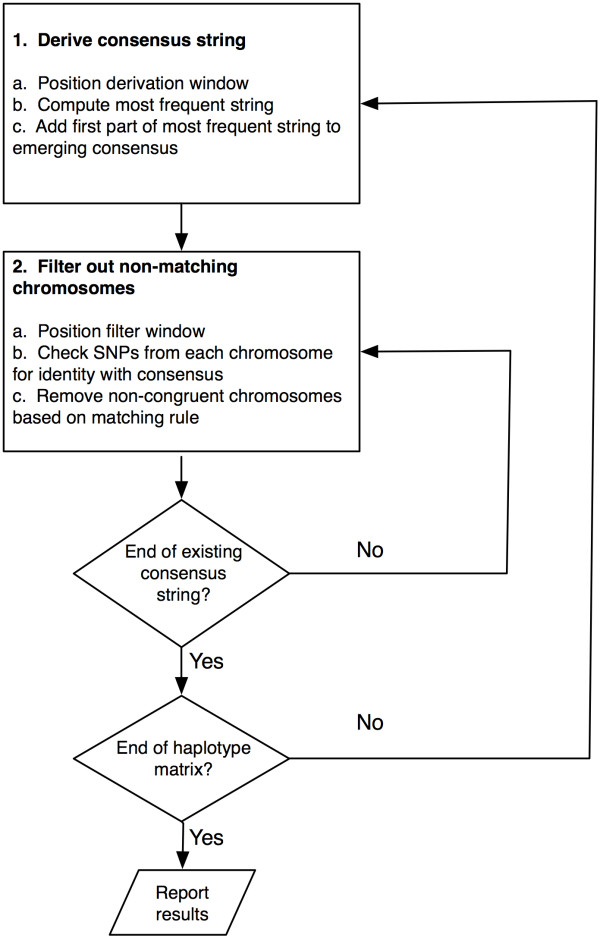
Historically, extended haplotypes have been defined using only a few data points, such as alleles for several HLA genes in the MHC. High-density SNP data, and the increasing affordability of whole genome SNP typing, creates the opportunity to define higher resolution extended haplotypes. This drives the need for new tools that support quantification and visualization of extended haplotypes as defined by as many as 2000 SNPs. Confronted with high-density SNP data across the major histocompatibility complex (MHC) for 2,300 complete families, compiled by the Type 1 Diabetes Genetics Consortium (T1DGC), we developed software for studying extended haplotypes.
The software, called ExHap (Extended Haplotype), uses a similarity measurement we term congruence to identify and quantify long-range allele identity. Using ExHap, we analyzed congruence in both the T1DGC data and family-phased data from the International HapMap Project.
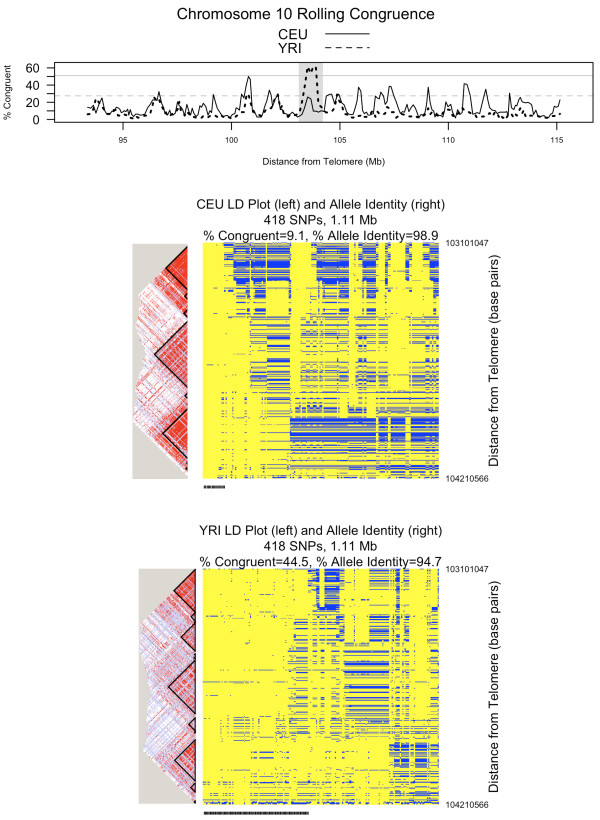
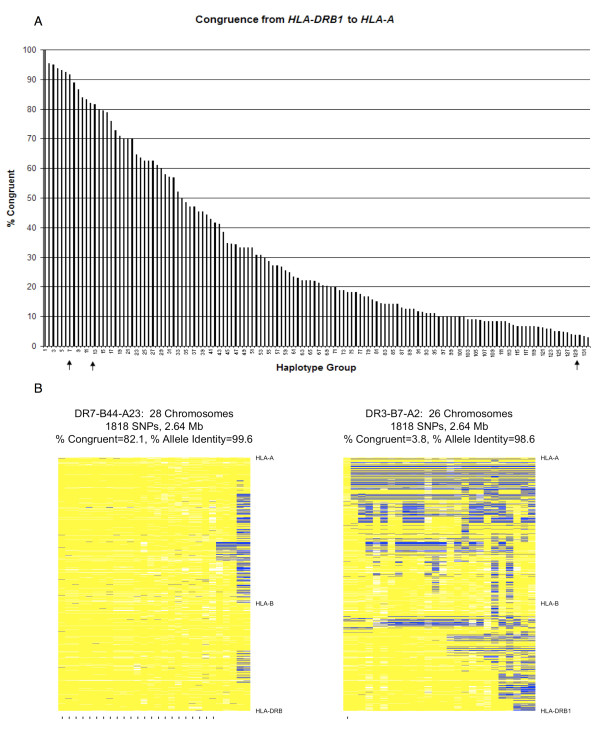
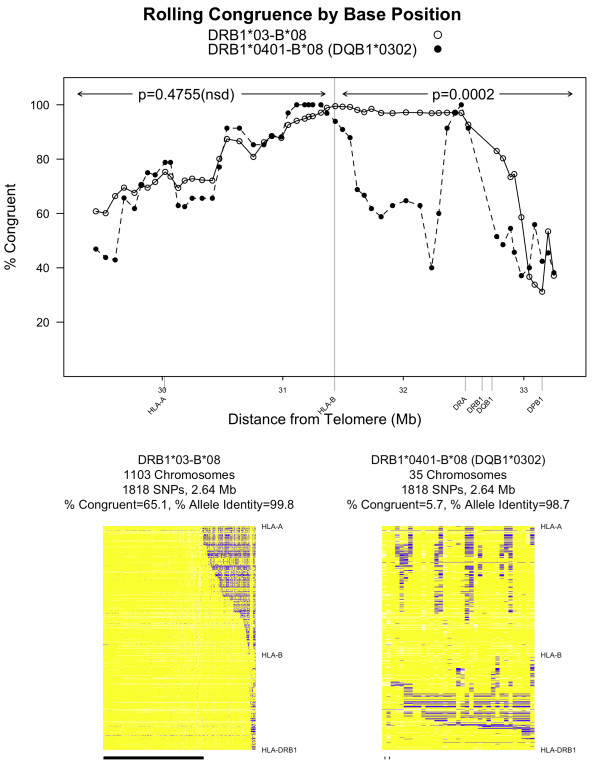
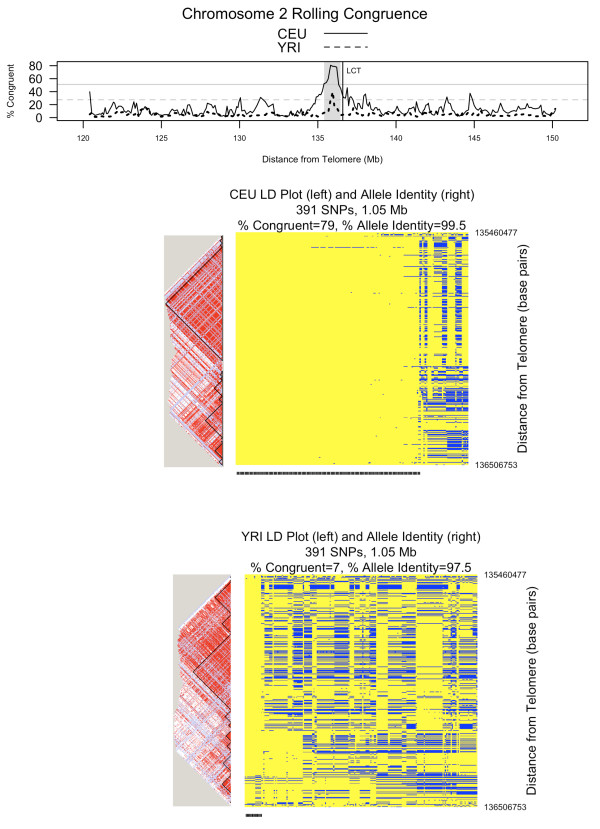
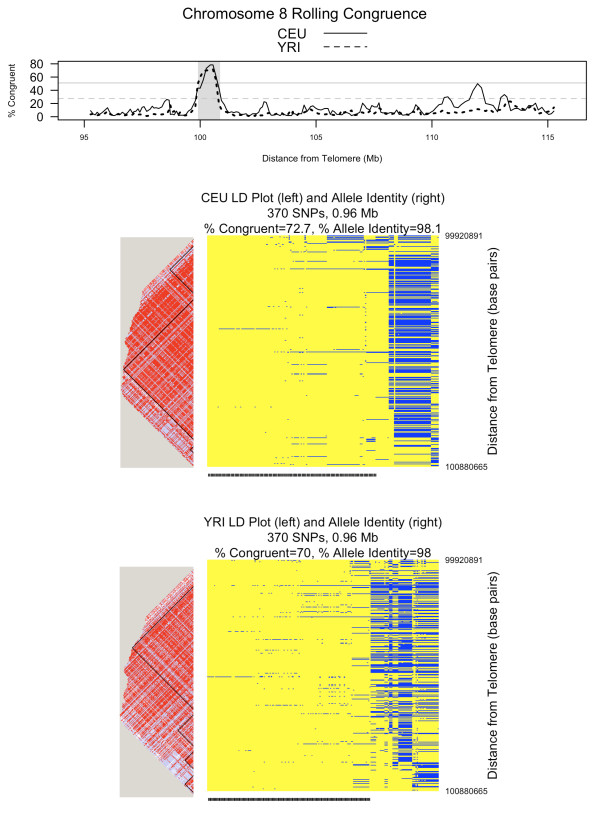
Congruent chromosomes from the T1DGC data have between 96.5% and 99.9% allele identity over 1,818 SNPs spanning 2.64 megabases of the MHC (HLA-DRB1 to HLA-A). Thirty-three of 132 DQ-DR-B-A defined haplotype groups have > 50% congruent chromosomes in this region. For example, 92% of chromosomes within the DR3-B8-A1 haplotype are congruent from HLA-DRB1 to HLA-A (99.8% allele identity). We also applied ExHap to all 22 autosomes for both CEU and YRI cohorts from the International HapMap Project, identifying multiple candidate extended haplotypes.
Long-range congruence is not unique to the MHC region. Patterns of allele identity on phased chromosomes provide a simple, straightforward approach to visually and quantitatively inspect complex long-range structural patterns in the genome. Such patterns aid the biologist in appreciating genetic similarities and differences across cohorts, and can lead to hypothesis generation for subsequent studies.
历史上,扩展单倍型仅使用少数数据点(例如 MHC 中几个 HLA 基因的等位基因)进行定义。高密度 SNP 数据以及全基因组 SNP 分型成本的降低,为定义更高分辨率的扩展单倍型创造了机会。这需要新的工具来支持多达 2000 个 SNP 定义的扩展单倍型的量化和可视化。面对由 1 型糖尿病遗传学联合会(T1DGC)编译的 2300 个完整家庭在主要组织相容性复合体(MHC)上的高密度 SNP 数据,我们开发了用于研究扩展单倍型的软件。
该软件称为 ExHap(扩展单倍型),使用我们称为一致性的相似性测量来识别和量化长程等位基因同一性。使用 ExHap,我们分析了 T1DGC 数据和国际人类基因组单体型图计划(HapMap Project)中的家族相染色体数据中的一致性。
T1DGC 数据中的一致染色体在跨越 MHC(HLA-DRB1 到 HLA-A)的 2.64 兆碱基的 1818 个 SNP 上具有 96.5%至 99.9%的等位基因同一性。在该区域内,132 个 DQ-DR-B-A 定义的单倍型组中有 33 个具有> 50%的一致染色体。例如,DR3-B8-A1 单倍型内的 92%染色体在 HLA-DRB1 到 HLA-A 之间是一致的(99.8%的等位基因同一性)。我们还将 ExHap 应用于国际人类基因组单体型图计划中的 CEU 和 YRI 队列的所有 22 条常染色体,鉴定了多个候选扩展单倍型。
长程一致性不仅存在于 MHC 区域。相染色体上的等位基因同一性模式为直观地定量检查基因组中的复杂长程结构模式提供了一种简单,直接的方法。这种模式有助于生物学家了解不同队列之间的遗传相似性和差异,并为后续研究生成假设。