Children's Hospital of Eastern Ontario Research Institute, 401 Smyth Road, Ottawa, Ontario, K1J 8 L1, Canada.
BMC Med Inform Decis Mak. 2013 Oct 5;13:114. doi: 10.1186/1472-6947-13-114.
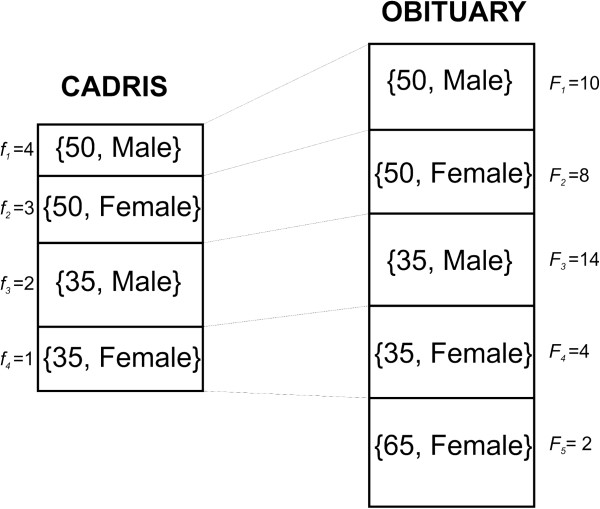
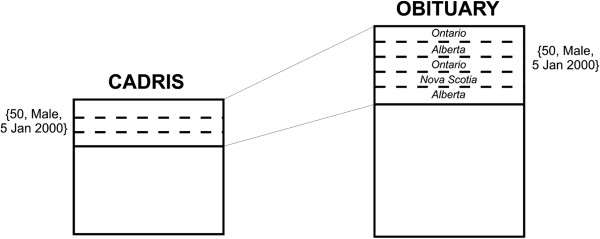
Our objective was to develop a model for measuring re-identification risk that more closely mimics the behaviour of an adversary by accounting for repeated attempts at matching and verification of matches, and apply it to evaluate the risk of re-identification for Canada's post-marketing adverse drug event database (ADE).Re-identification is only demonstrably plausible for deaths in ADE. A matching experiment between ADE records and virtual obituaries constructed from Statistics Canada vital statistics was simulated. A new re-identification risk is considered, it assumes that after gathering all the potential matches for a patient record (all records in the obituaries that are potential matches for an ADE record), an adversary tries to verify these potential matches. Two adversary scenarios were considered: (a) a mildly motivated adversary who will stop after one verification attempt, and (b) a highly motivated adversary who will attempt to verify all the potential matches and is only limited by practical or financial considerations.
The mean percentage of records in ADE that had a high probability of being re-identified was computed.
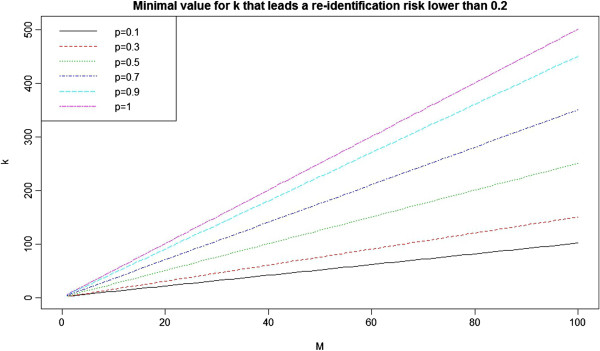
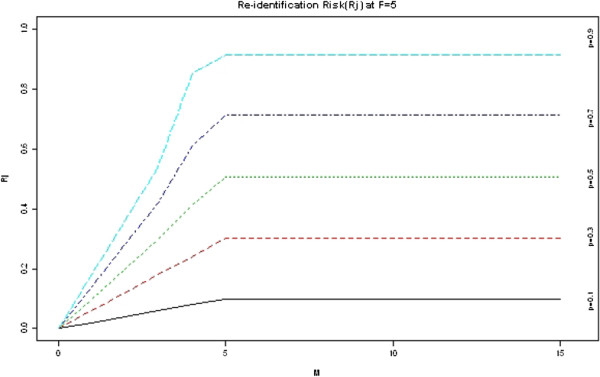
Under scenario (a), the risk of re-identification from disclosing the province, age at death, gender, and exact date of the report is quite high, but the removal of province brings down the risk significantly. By only generalizing the date of reporting to month and year and including all other variables, the risk is always low. All ADE records have a high risk of re-identification under scenario (b), but the plausibility of that scenario is limited because of the financial and practical deterrent even for highly motivated adversaries.
It is possible to disclose Canada's adverse drug event database while ensuring that plausible re-identification risks are acceptably low. Our new re-identification risk model is suitable for such risk assessments.
我们的目标是开发一种更能模拟对手行为的重新识别风险模型,通过考虑到重复的匹配尝试和匹配验证,应用于评估加拿大上市后药物不良事件数据库(ADE)重新识别的风险。只有在 ADE 的死亡事件中,重新识别才是明显合理的。我们模拟了在 ADE 记录和从加拿大统计部门生命统计数据构建的虚拟讣告之间进行匹配实验。考虑了一种新的重新识别风险,它假设在收集了患者记录的所有潜在匹配项(讣告中所有可能与 ADE 记录匹配的记录)后,对手试图验证这些潜在匹配项。考虑了两种对手场景:(a)一个动机较弱的对手,他将在一次验证尝试后停止;(b)一个动机较强的对手,他将尝试验证所有潜在的匹配项,并且只受到实际或财务考虑的限制。
计算了 ADE 中具有高重新识别概率的记录的平均百分比。
在场景(a)下,披露省份、死亡时的年龄、性别和报告的确切日期的重新识别风险相当高,但去除省份会显著降低风险。通过仅将报告日期概括为月份和年份,并包含所有其他变量,风险始终很低。在场景(b)下,所有 ADE 记录都有很高的重新识别风险,但由于财务和实际的威慑,即使是动机很强的对手,这种情况的可能性也很有限。
可以在确保合理的重新识别风险可接受的低水平的情况下披露加拿大的药物不良事件数据库。我们的新重新识别风险模型适用于这种风险评估。