Aalto University School of Science and Helsinki Institute for Information Technology HIIT, Finland, International Computer Science Institute, Berkeley, CA, USA, CRS4-Center for Advanced Studies, Research and Development in Sardinia, Italy and CSC-IT Center for Science, Finland.
Bioinformatics. 2014 Jan 1;30(1):119-20. doi: 10.1093/bioinformatics/btt601. Epub 2013 Oct 22.
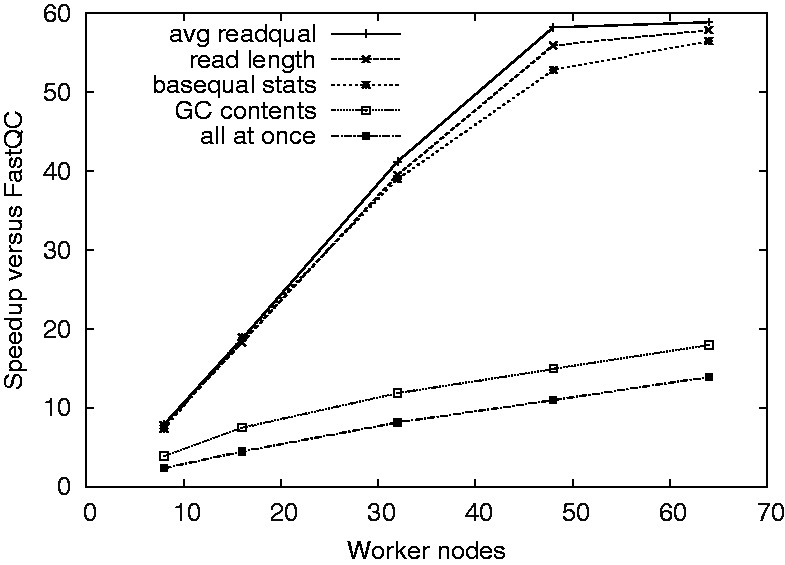
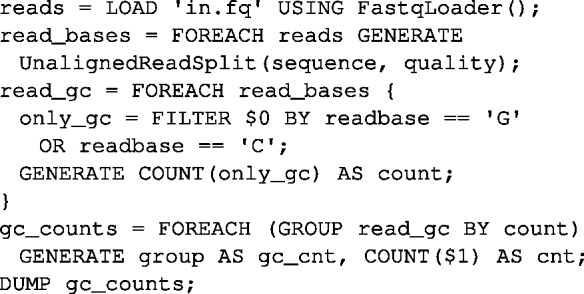
Hadoop MapReduce-based approaches have become increasingly popular due to their scalability in processing large sequencing datasets. However, as these methods typically require in-depth expertise in Hadoop and Java, they are still out of reach of many bioinformaticians. To solve this problem, we have created SeqPig, a library and a collection of tools to manipulate, analyze and query sequencing datasets in a scalable and simple manner. SeqPigscripts use the Hadoop-based distributed scripting engine Apache Pig, which automatically parallelizes and distributes data processing tasks. We demonstrate SeqPig's scalability over many computing nodes and illustrate its use with example scripts.
Available under the open source MIT license at http://sourceforge.net/projects/seqpig/
由于其在处理大型测序数据集方面的可扩展性,基于 Hadoop MapReduce 的方法变得越来越流行。然而,由于这些方法通常需要深入了解 Hadoop 和 Java,因此它们仍然超出了许多生物信息学家的能力范围。为了解决这个问题,我们创建了 SeqPig,这是一个库和一组工具,用于以可扩展和简单的方式操作、分析和查询测序数据集。SeqPigscripts 使用基于 Hadoop 的分布式脚本引擎 Apache Pig,它可以自动并行化和分发数据处理任务。我们展示了 SeqPig 在许多计算节点上的可扩展性,并通过示例脚本说明了它的用法。
可在开源 MIT 许可证下从 http://sourceforge.net/projects/seqpig/ 获取