Fang Ruogu, Karlsson Kolbeinn, Chen Tsuhan, Sanelli Pina C
Department of Electrical and Computer Engineering, Cornell University, Ithaca, NY, USA.
Department of Electrical and Computer Engineering, Cornell University, Ithaca, NY, USA.
Med Image Anal. 2014 Aug;18(6):866-80. doi: 10.1016/j.media.2013.09.008. Epub 2013 Oct 17.
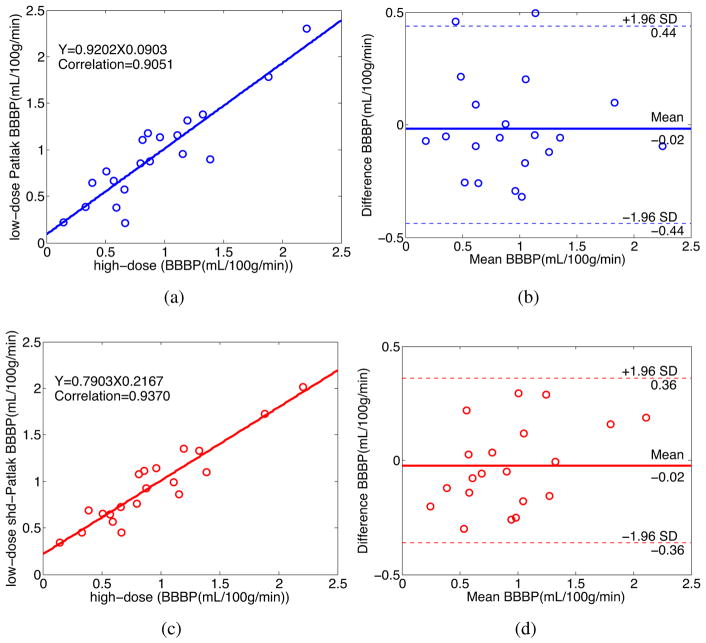
Blood-brain barrier permeability (BBBP) measurements extracted from the perfusion computed tomography (PCT) using the Patlak model can be a valuable indicator to predict hemorrhagic transformation in patients with acute stroke. Unfortunately, the standard Patlak model based PCT requires excessive radiation exposure, which raised attention on radiation safety. Minimizing radiation dose is of high value in clinical practice but can degrade the image quality due to the introduced severe noise. The purpose of this work is to construct high quality BBBP maps from low-dose PCT data by using the brain structural similarity between different individuals and the relations between the high- and low-dose maps. The proposed sparse high-dose induced (shd-Patlak) model performs by building a high-dose induced prior for the Patlak model with a set of location adaptive dictionaries, followed by an optimized estimation of BBBP map with the prior regularized Patlak model. Evaluation with the simulated low-dose clinical brain PCT datasets clearly demonstrate that the shd-Patlak model can achieve more significant gains than the standard Patlak model with improved visual quality, higher fidelity to the gold standard and more accurate details for clinical analysis.
使用Patlak模型从灌注计算机断层扫描(PCT)中提取的血脑屏障通透性(BBBP)测量值,可能是预测急性中风患者出血性转化的一个有价值的指标。不幸的是,基于标准Patlak模型的PCT需要过多的辐射暴露,这引发了对辐射安全的关注。在临床实践中,将辐射剂量降至最低很有价值,但由于引入的严重噪声,可能会降低图像质量。这项工作的目的是利用不同个体之间的脑结构相似性以及高剂量和低剂量图像之间的关系,从低剂量PCT数据构建高质量的BBBP图。所提出的稀疏高剂量诱导(shd-Patlak)模型通过使用一组位置自适应字典为Patlak模型构建高剂量诱导先验,然后使用先验正则化的Patlak模型对BBBP图进行优化估计。对模拟的低剂量临床脑PCT数据集的评估清楚地表明,shd-Patlak模型比标准Patlak模型能取得更显著的收益,具有更好的视觉质量、对金标准更高的保真度以及用于临床分析的更准确细节。