Ciccarese Paolo, Soiland-Reyes Stian, Belhajjame Khalid, Gray Alasdair Jg, Goble Carole, Clark Tim
Department of Neurology, Massachusetts General Hospital, 55 Fruit Street, Boston, MA 02114, USA.
J Biomed Semantics. 2013 Nov 22;4(1):37. doi: 10.1186/2041-1480-4-37.
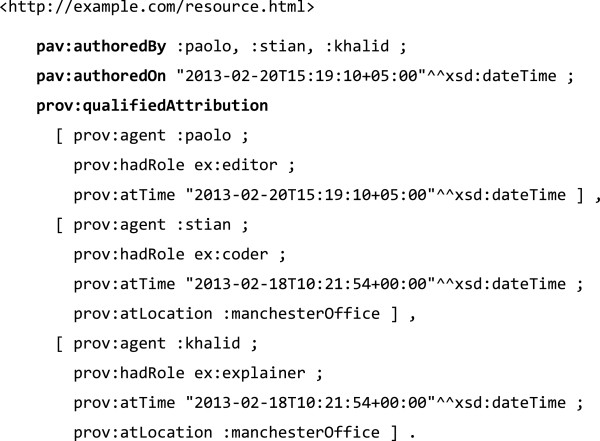
Provenance is a critical ingredient for establishing trust of published scientific content. This is true whether we are considering a data set, a computational workflow, a peer-reviewed publication or a simple scientific claim with supportive evidence. Existing vocabularies such as Dublin Core Terms (DC Terms) and the W3C Provenance Ontology (PROV-O) are domain-independent and general-purpose and they allow and encourage for extensions to cover more specific needs. In particular, to track authoring and versioning information of web resources, PROV-O provides a basic methodology but not any specific classes and properties for identifying or distinguishing between the various roles assumed by agents manipulating digital artifacts, such as author, contributor and curator.
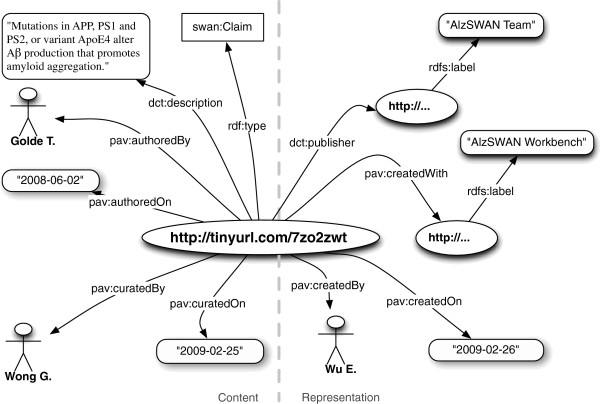
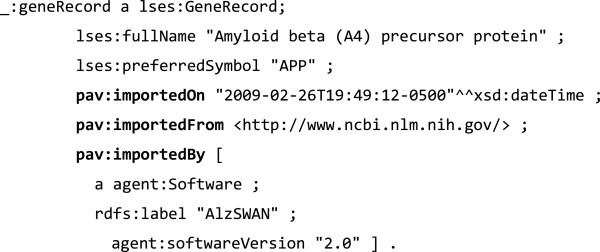
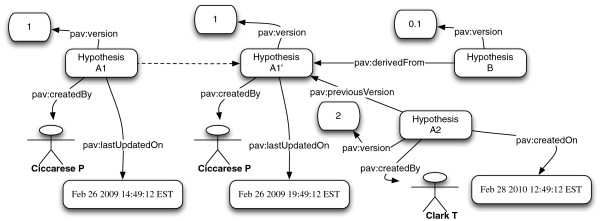
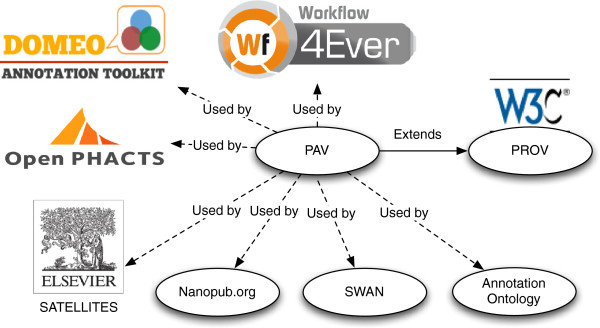
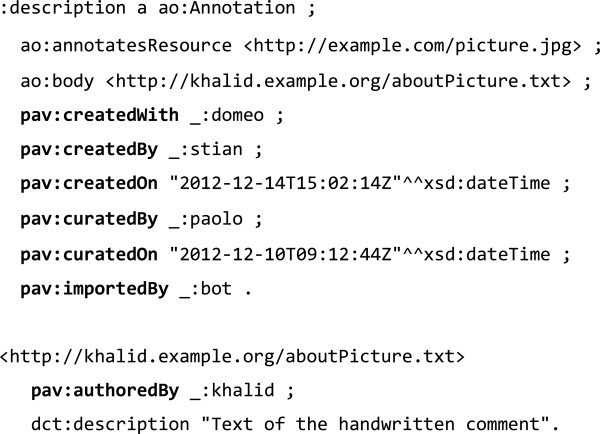
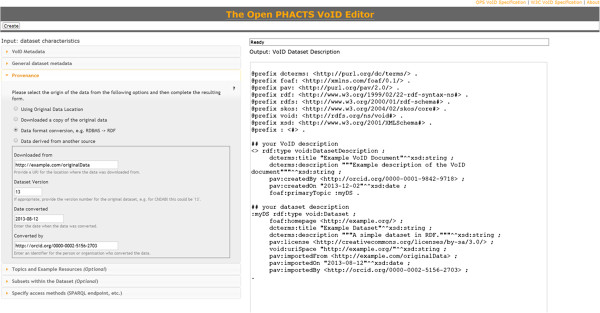
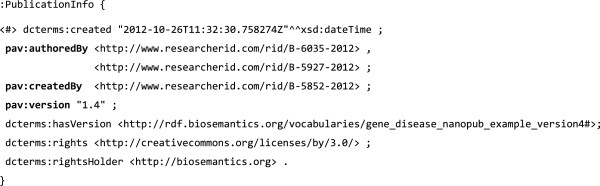
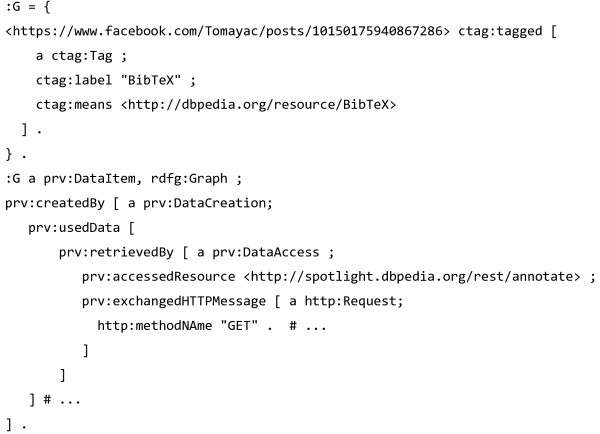
We present the Provenance, Authoring and Versioning ontology (PAV, namespace http://purl.org/pav/): a lightweight ontology for capturing "just enough" descriptions essential for tracking the provenance, authoring and versioning of web resources. We argue that such descriptions are essential for digital scientific content. PAV distinguishes between contributors, authors and curators of content and creators of representations in addition to the provenance of originating resources that have been accessed, transformed and consumed. We explore five projects (and communities) that have adopted PAV illustrating their usage through concrete examples. Moreover, we present mappings that show how PAV extends the W3C PROV-O ontology to support broader interoperability.
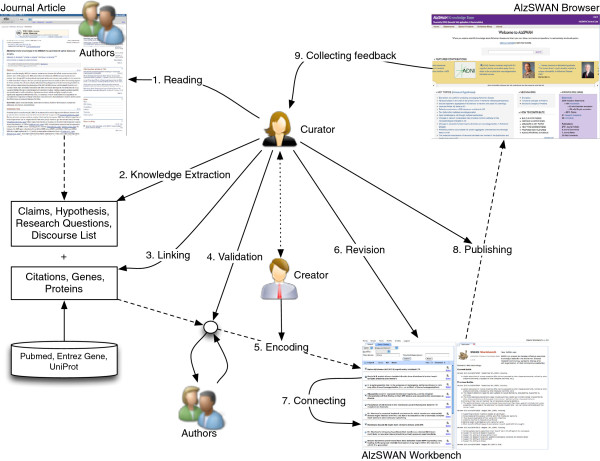
The initial design of the PAV ontology was driven by requirements from the AlzSWAN project with further requirements incorporated later from other projects detailed in this paper. The authors strived to keep PAV lightweight and compact by including only those terms that have demonstrated to be pragmatically useful in existing applications, and by recommending terms from existing ontologies when plausible.
We analyze and compare PAV with related approaches, namely Provenance Vocabulary (PRV), DC Terms and BIBFRAME. We identify similarities and analyze differences between those vocabularies and PAV, outlining strengths and weaknesses of our proposed model. We specify SKOS mappings that align PAV with DC Terms. We conclude the paper with general remarks on the applicability of PAV.
出处是建立对已发表科学内容信任的关键要素。无论是考虑数据集、计算工作流程、同行评审出版物还是带有支持性证据的简单科学主张,都是如此。诸如都柏林核心术语(DC Terms)和万维网联盟出处本体(PROV-O)等现有词汇表是独立于领域的通用词汇表,它们允许并鼓励进行扩展以满足更具体的需求。特别是,为了跟踪网络资源的创作和版本信息,PROV-O提供了一种基本方法,但没有用于识别或区分操纵数字工件的主体(如作者、贡献者和策展人)所承担的各种角色的任何特定类和属性。
PAV本体的初始设计由AlzSWAN项目的需求驱动,本文后面详细介绍的其他项目的进一步需求随后也被纳入。作者努力使PAV保持轻量级和紧凑,只纳入那些在现有应用中已证明实用的术语,并在合理的情况下推荐现有本体中的术语。
我们分析并比较了PAV与相关方法,即出处词汇表(PRV)、DC Terms和BIBFRAME。我们确定了这些词汇表与PAV之间的异同,概述了我们提出的模型的优缺点。我们指定了将PAV与DC Terms对齐的SKOS映射。我们在论文结尾对PAV的适用性进行了一般性评论。