Department of Chemistry and Chemical Biology, Harvard University , 12 Oxford Street, Cambridge, Massachusetts 02138, United States.
J Proteome Res. 2014 Mar 7;13(3):1757-65. doi: 10.1021/pr401280w. Epub 2014 Feb 14.
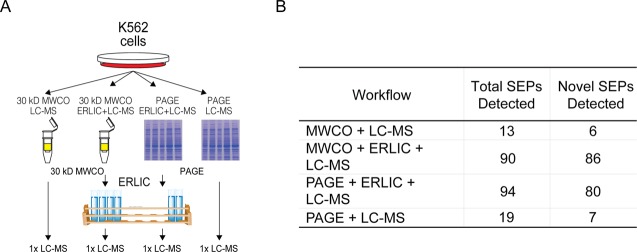
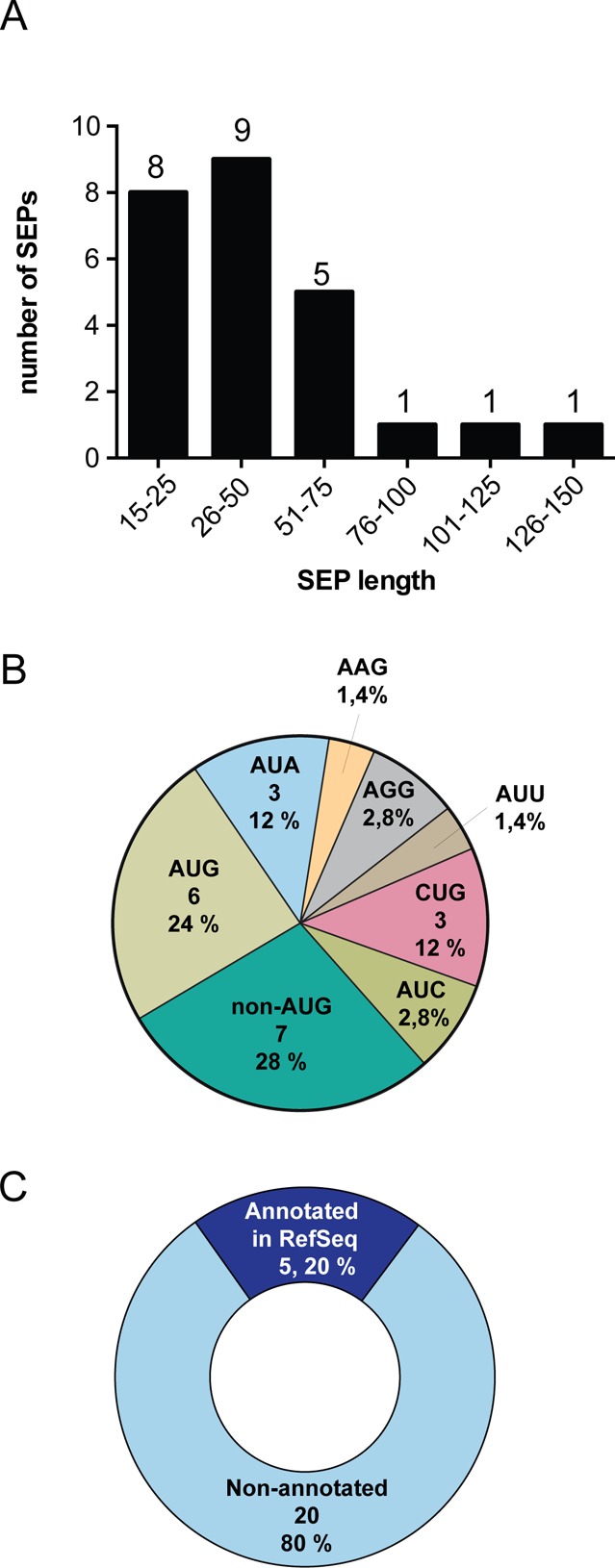
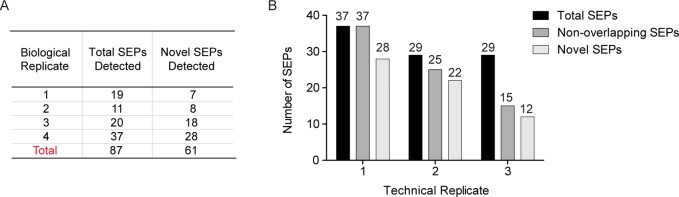
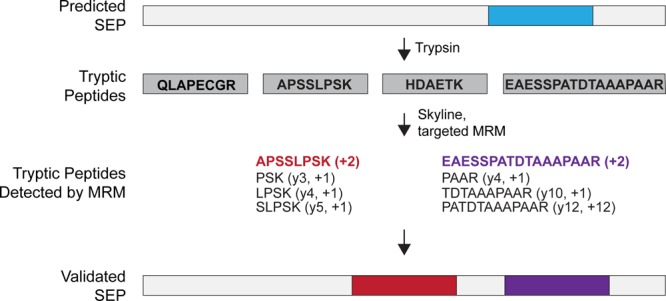
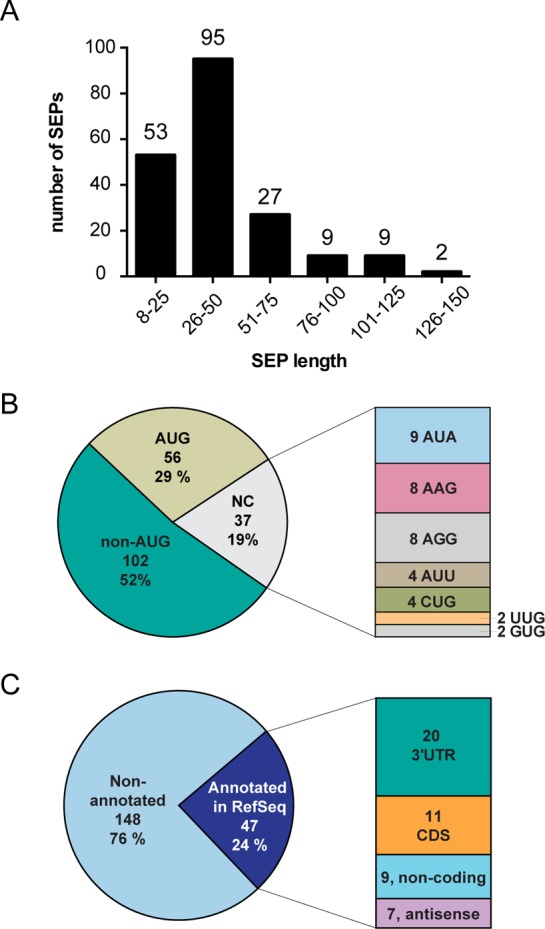
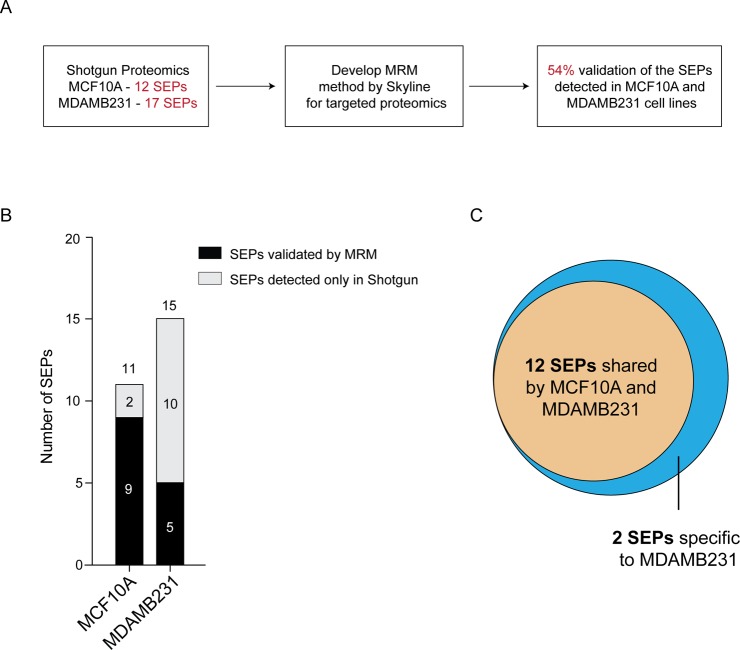
The existence of nonannotated protein-coding human short open reading frames (sORFs) has been revealed through the direct detection of their sORF-encoded polypeptide (SEP) products. The discovery of novel SEPs increases the size of the genome and the proteome and provides insights into the molecular biology of mammalian cells, such as the prevalent usage of non-AUG start codons. Through modifications of the existing SEP-discovery workflow, we discover an additional 195 SEPs in K562 cells and extend this methodology to identify novel human SEPs in additional cell lines and human tissue for a final tally of 237 new SEPs. These results continue to expand the human genome and proteome and demonstrate that SEPs are a ubiquitous class of nonannotated polypeptides that require further investigation.
通过直接检测其短开放阅读框(sORF)编码多肽(SEP)产物,揭示了非注释的蛋白质编码人类短开放阅读框(sORF)的存在。新 SEP 的发现增加了基因组和蛋白质组的大小,并深入了解了哺乳动物细胞的分子生物学,例如非 AUG 起始密码子的普遍使用。通过对现有 SEP 发现工作流程的修改,我们在 K562 细胞中发现了另外 195 个 SEP,并将此方法扩展到其他细胞系和人类组织中以鉴定新的人类 SEP,最终确定了 237 个新的 SEP。这些结果不断扩展人类基因组和蛋白质组,并证明 SEP 是一类普遍存在的非注释多肽,需要进一步研究。