Department of Chemistry and Chemical Biology, Harvard University, Cambridge, Massachusetts, USA.
Nat Chem Biol. 2013 Jan;9(1):59-64. doi: 10.1038/nchembio.1120. Epub 2012 Nov 18.
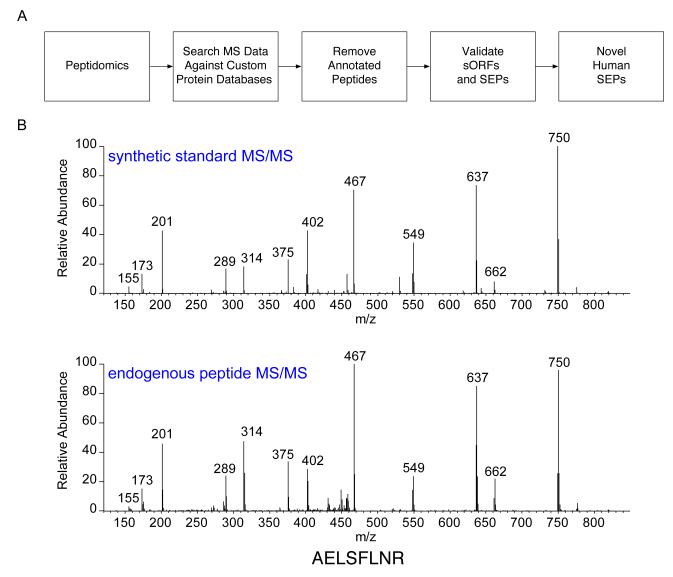
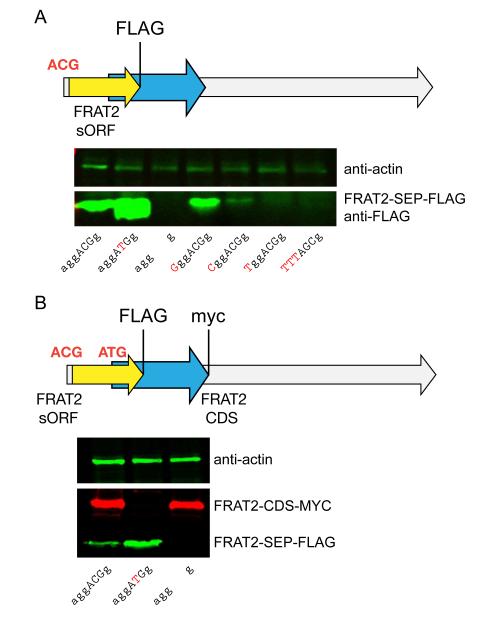
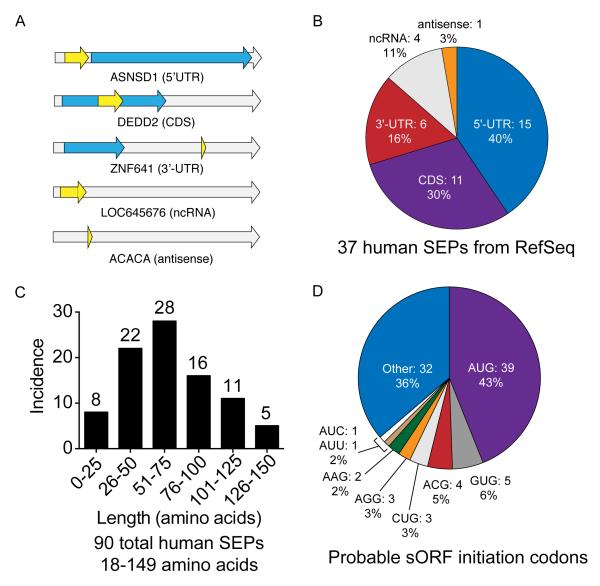
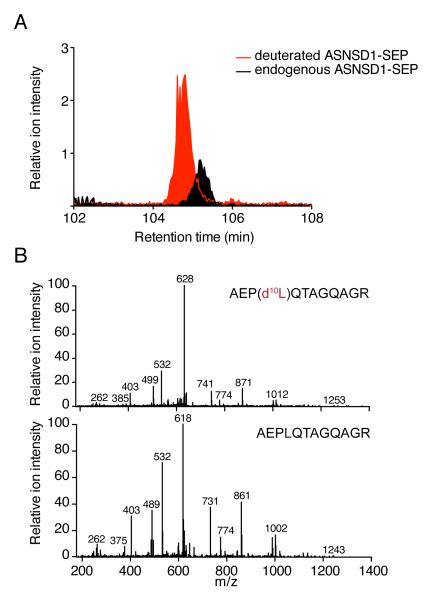
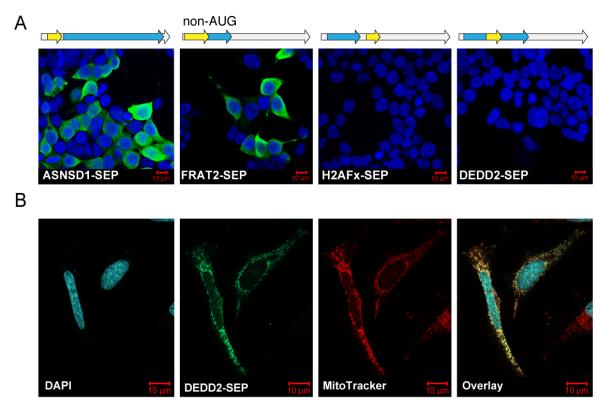
The complete extent to which the human genome is translated into polypeptides is of fundamental importance. We report a peptidomic strategy to detect short open reading frame (sORF)-encoded polypeptides (SEPs) in human cells. We identify 90 SEPs, 86 of which are previously uncharacterized, which is the largest number of human SEPs ever reported. SEP abundances range from 10-1,000 molecules per cell, identical to abundances of known proteins. SEPs arise from sORFs in noncoding RNAs as well as multicistronic mRNAs, and many SEPs initiate with non-AUG start codons, indicating that noncanonical translation may be more widespread in mammals than previously thought. In addition, coding sORFs are present in a small fraction (8 out of 1,866) of long intergenic noncoding RNAs. Together, these results provide strong evidence that the human proteome is more complex than previously appreciated.
人类基因组翻译为多肽的完整程度具有根本重要性。我们报告了一种用于检测人类细胞中短开放阅读框(sORF)编码多肽(SEP)的肽组学策略。我们鉴定了 90 个 SEP,其中 86 个是以前未被描述的,这是迄今为止报道的最大数量的人类 SEP。SEP 的丰度范围为每个细胞 10-1000 个分子,与已知蛋白质的丰度相同。SEP 来源于非编码 RNA 中的 sORF 以及多顺反子 mRNA,并且许多 SEP 以非 AUG 起始密码子开始,这表明非规范翻译在哺乳动物中可能比以前认为的更为普遍。此外,编码 sORF 存在于一小部分(1866 个中的 8 个)长基因间非编码 RNA 中。总之,这些结果提供了强有力的证据,表明人类蛋白质组比以前认为的更为复杂。