Howard Hughes Medical Institute, Department of Cellular and Molecular Pharmacology, University of California, San Francisco, San Francisco, CA 94158, USA.
Cell. 2011 Nov 11;147(4):789-802. doi: 10.1016/j.cell.2011.10.002. Epub 2011 Nov 3.
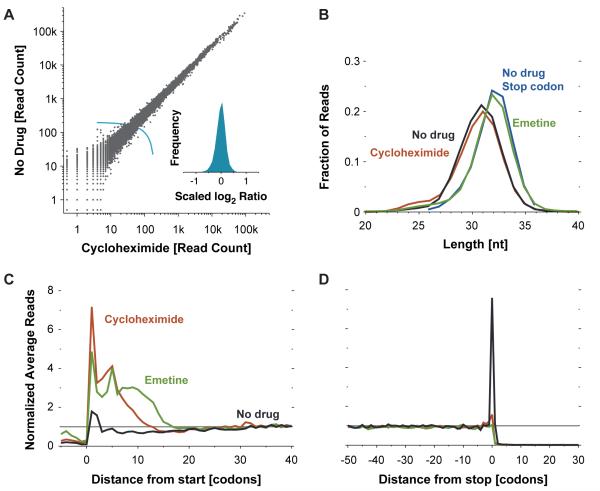
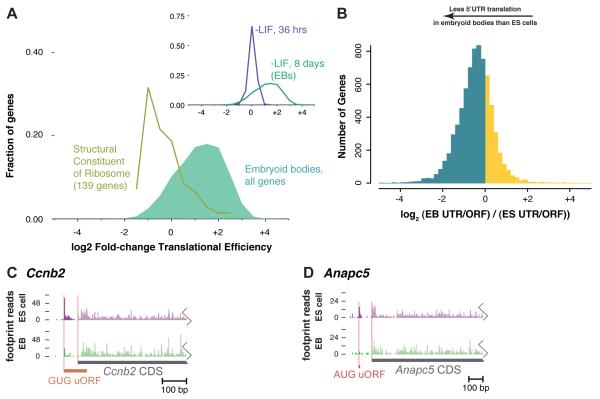
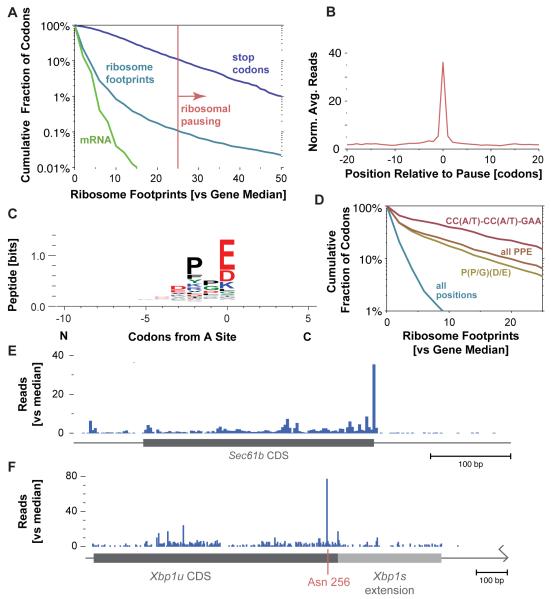
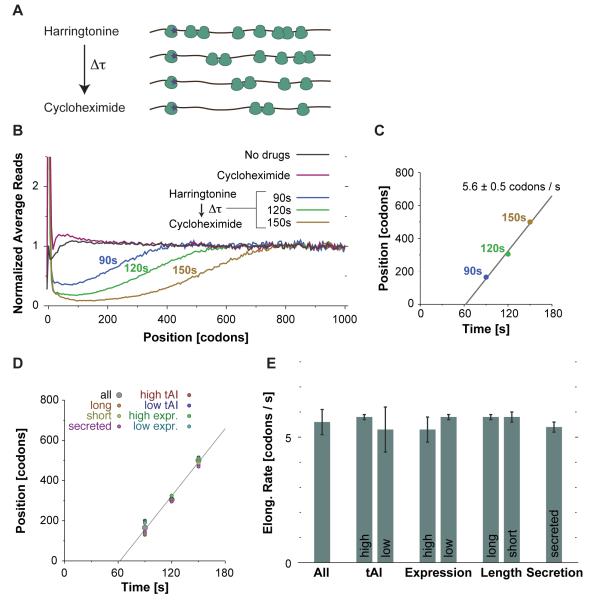
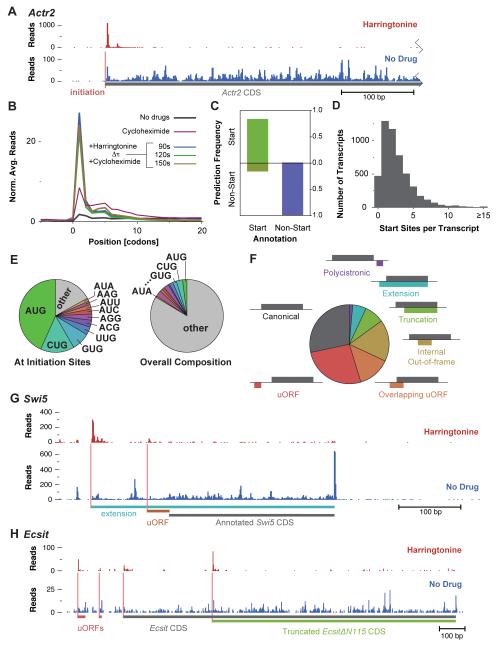
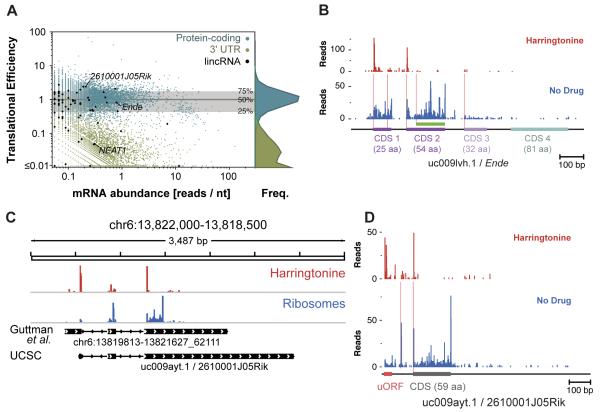
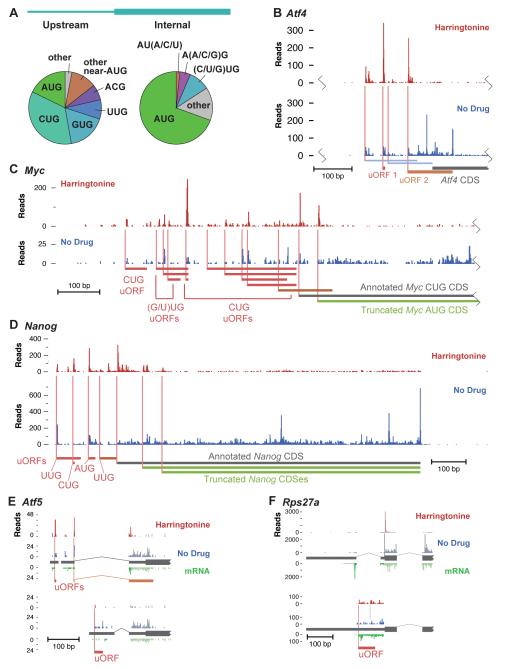
The ability to sequence genomes has far outstripped approaches for deciphering the information they encode. Here we present a suite of techniques, based on ribosome profiling (the deep sequencing of ribosome-protected mRNA fragments), to provide genome-wide maps of protein synthesis as well as a pulse-chase strategy for determining rates of translation elongation. We exploit the propensity of harringtonine to cause ribosomes to accumulate at sites of translation initiation together with a machine learning algorithm to define protein products systematically. Analysis of translation in mouse embryonic stem cells reveals thousands of strong pause sites and unannotated translation products. These include amino-terminal extensions and truncations and upstream open reading frames with regulatory potential, initiated at both AUG and non-AUG codons, whose translation changes after differentiation. We also define a class of short, polycistronic ribosome-associated coding RNAs (sprcRNAs) that encode small proteins. Our studies reveal an unanticipated complexity to mammalian proteomes.
测序技术的发展已经远远超过了解码它们所编码信息的方法。在这里,我们提出了一系列基于核糖体分析(核糖体保护的 mRNA 片段的深度测序)的技术,以提供蛋白质合成的全基因组图谱,以及一种用于确定翻译延伸速率的脉冲追踪策略。我们利用长春花碱引起核糖体在翻译起始位点积累的倾向,以及机器学习算法,系统地定义蛋白质产物。对小鼠胚胎干细胞中转录的分析揭示了数千个强暂停位点和未注释的翻译产物。这些包括氨基末端延伸和截断以及具有调节潜力的上游开放阅读框,它们可以在 AUG 和非 AUG 密码子处起始翻译,其翻译在分化后发生变化。我们还定义了一类短的、多顺反子的核糖体相关编码 RNA(sprcRNAs),它们编码小蛋白。我们的研究揭示了哺乳动物蛋白质组的出人意料的复杂性。