Jimeno Yepes Antonio, Verspoor Karin
National ICT Australia, Victoria Research Laboratory, Melbourne, Australia and Department of Computing and Information Systems, The University of Melbourne, Melbourne, Australia.
Database (Oxford). 2014 Feb 10;2014:bau003. doi: 10.1093/database/bau003. Print 2014.
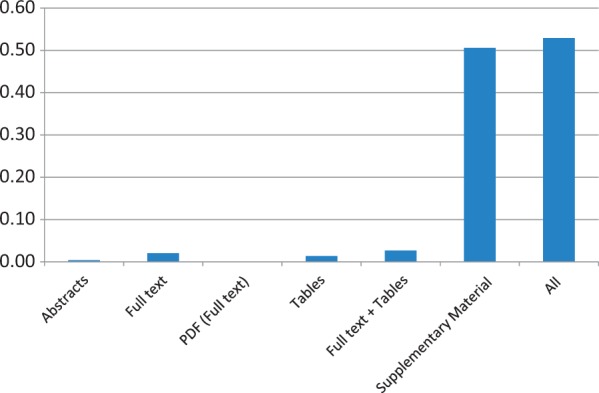
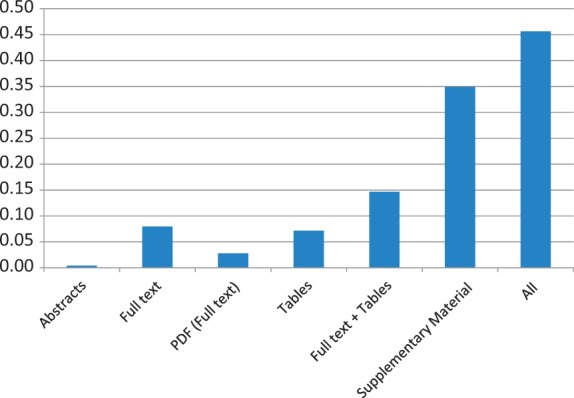
A major focus of modern biological research is the understanding of how genomic variation relates to disease. Although there are significant ongoing efforts to capture this understanding in curated resources, much of the information remains locked in unstructured sources, in particular, the scientific literature. Thus, there have been several text mining systems developed to target extraction of mutations and other genetic variation from the literature. We have performed the first study of the use of text mining for the recovery of genetic variants curated directly from the literature. We consider two curated databases, COSMIC (Catalogue Of Somatic Mutations In Cancer) and InSiGHT (International Society for Gastro-intestinal Hereditary Tumours), that contain explicit links to the source literature for each included mutation. Our analysis shows that the recall of the mutations catalogued in the databases using a text mining tool is very low, despite the well-established good performance of the tool and even when the full text of the associated article is available for processing. We demonstrate that this discrepancy can be explained by considering the supplementary material linked to the published articles, not previously considered by text mining tools. Although it is anecdotally known that supplementary material contains 'all of the information', and some researchers have speculated about the role of supplementary material (Schenck et al. Extraction of genetic mutations associated with cancer from public literature. J Health Med Inform 2012;S2:2.), our analysis substantiates the significant extent to which this material is critical. Our results highlight the need for literature mining tools to consider not only the narrative content of a publication but also the full set of material related to a publication.
现代生物学研究的一个主要重点是理解基因组变异与疾病之间的关系。尽管目前正在做出巨大努力,试图在经过整理的资源中体现这种理解,但许多信息仍被锁定在非结构化来源中,尤其是科学文献。因此,已经开发了几种文本挖掘系统,旨在从文献中提取突变和其他基因变异。我们首次开展了一项关于利用文本挖掘从文献中直接恢复经过整理的基因变异的研究。我们考虑了两个经过整理的数据库,即COSMIC(癌症体细胞突变目录)和InSiGHT(国际胃肠道遗传性肿瘤协会),它们包含了每个收录突变与来源文献的明确链接。我们的分析表明,尽管文本挖掘工具性能良好,甚至在相关文章的全文可供处理的情况下,使用该工具召回数据库中编目的突变的召回率仍然很低。我们证明,这种差异可以通过考虑与已发表文章相关的补充材料来解释,而文本挖掘工具此前并未考虑这些材料。虽然人们凭经验知道补充材料包含“所有信息”,并且一些研究人员也推测过补充材料的作用(申克等人。从公共文献中提取与癌症相关的基因突变。《健康医学信息杂志》2012年;S2:2。),但我们的分析证实了这些材料至关重要的程度。我们的结果凸显了文献挖掘工具不仅要考虑出版物的叙述内容,还要考虑与出版物相关的全套材料的必要性。