Widita Chasanah Kusumastuti, Maruyama Osamu
BMC Syst Biol. 2013;7 Suppl 6(Suppl 6):S14. doi: 10.1186/1752-0509-7-S6-S14. Epub 2013 Dec 13.
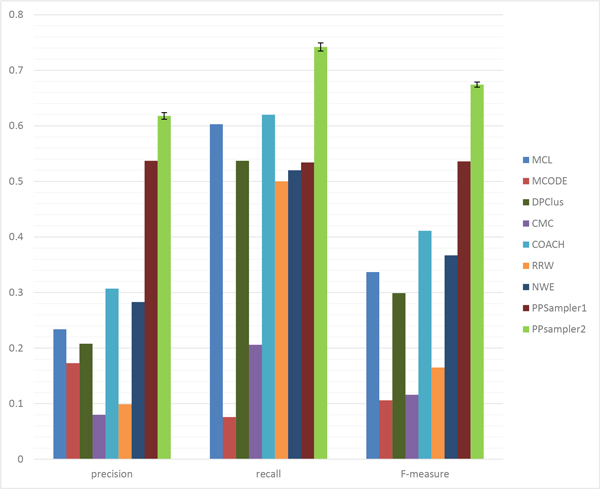
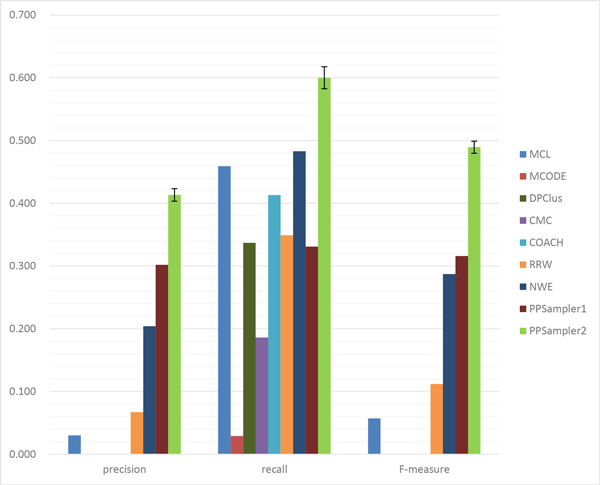
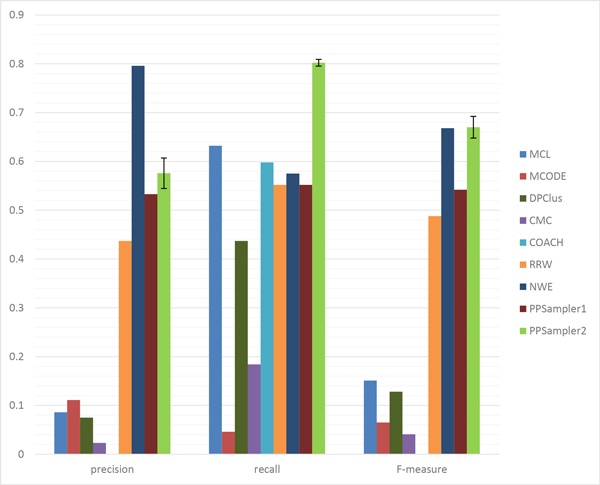
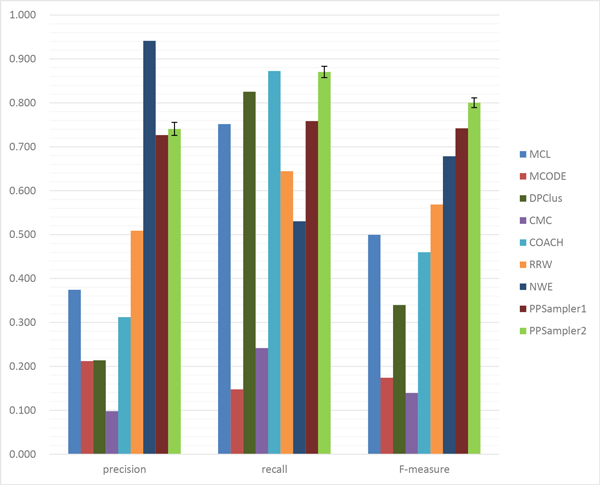
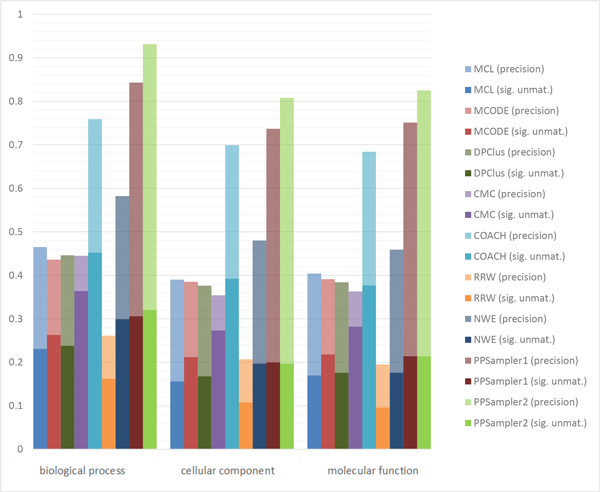
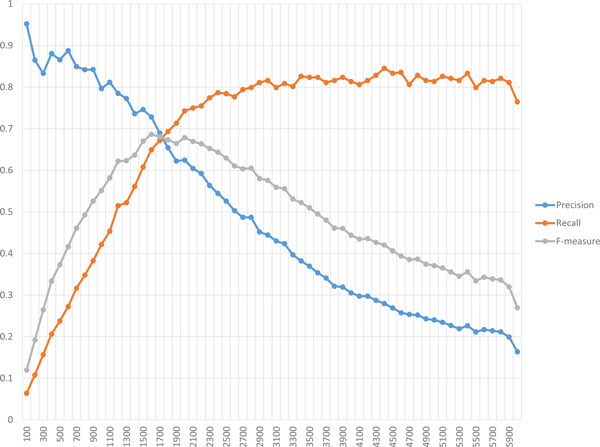
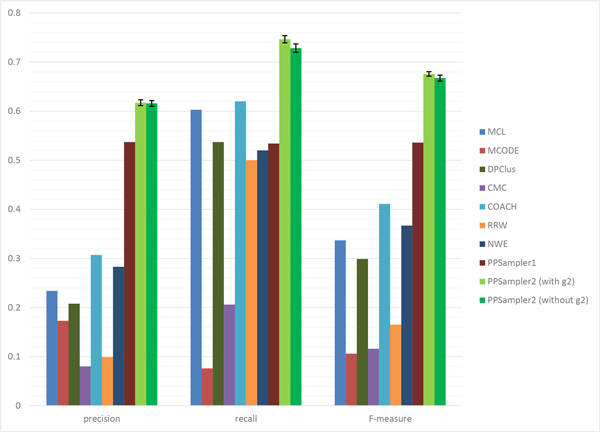
The problem of predicting sets of components of heteromeric protein complexes is a challenging problem in Systems Biology. There have been many tools proposed to predict those complexes. Among them, PPSampler, a protein complex prediction algorithm based on the Metropolis-Hastings algorithm, is reported to outperform other tools. In this work, we improve PPSampler by refining scoring functions and a proposal distribution used inside the algorithm so that predicted clusters are more accurate as well as the resulting algorithm runs faster. The new version is called PPSampler2. In computational experiments, PPSampler2 is shown to outperform other tools including PPSampler. The F-measure score of PPSampler2 is 0.67, which is at least 26% higher than those of the other tools. In addition, about 82% of the predicted clusters that are unmatched with any known complexes are statistically significant on the biological process aspect of Gene Ontology. Furthermore, the running time is reduced to twenty minutes, which is 1/24 of that of PPSampler.
预测异源蛋白复合物的组件集问题是系统生物学中一个具有挑战性的问题。已经提出了许多工具来预测这些复合物。其中,基于Metropolis-Hastings算法的蛋白质复合物预测算法PPSampler据报道优于其他工具。在这项工作中,我们通过优化算法内部使用的评分函数和提议分布来改进PPSampler,以使预测的聚类更准确,并且所得算法运行得更快。新版本称为PPSampler2。在计算实验中,PPSampler2被证明优于包括PPSampler在内的其他工具。PPSampler2的F-measure分数为0.67,比其他工具至少高26%。此外,约82%与任何已知复合物不匹配的预测聚类在基因本体论的生物学过程方面具有统计学意义。此外,运行时间减少到20分钟,这是PPSampler运行时间的1/24。