Department of Educational Psychology, Ball State University Muncie, IN, USA.
Department of Management, University of Notre Dame Notre Dame, IN, USA.
Front Psychol. 2014 May 20;5:337. doi: 10.3389/fpsyg.2014.00337. eCollection 2014.
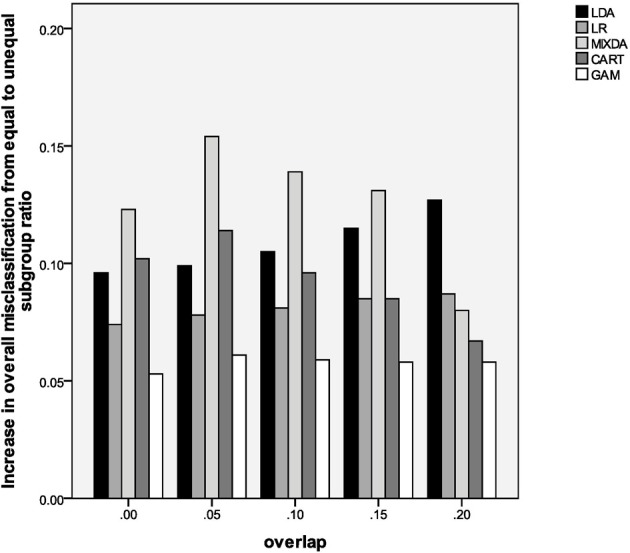
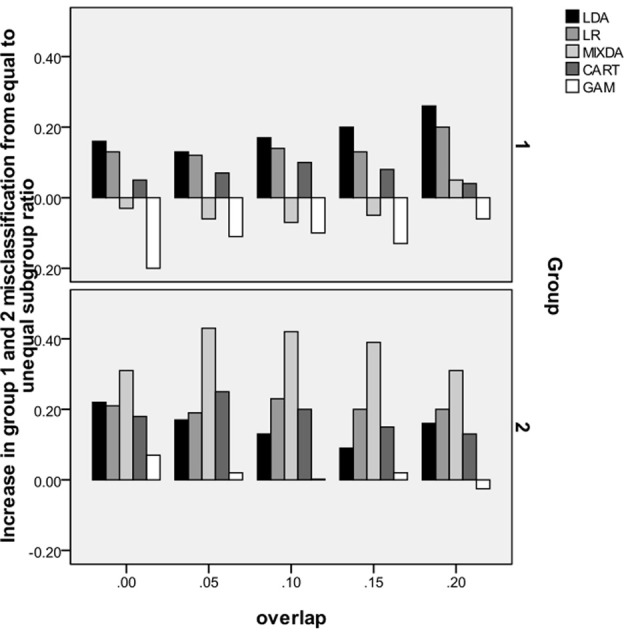
Classification using standard statistical methods such as linear discriminant analysis (LDA) or logistic regression (LR) presume knowledge of group membership prior to the development of an algorithm for prediction. However, in many real world applications members of the same nominal group, might in fact come from different subpopulations on the underlying construct. For example, individuals diagnosed with depression will not all have the same levels of this disorder, though for the purposes of LDA or LR they will be treated in the same manner. The goal of this simulation study was to examine the performance of several methods for group classification in the case where within group membership was not homogeneous. For example, suppose there are 3 known groups but within each group two unknown classes. Several approaches were compared, including LDA, LR, classification and regression trees (CART), generalized additive models (GAM), and mixture discriminant analysis (MIXDA). Results of the study indicated that CART and mixture discriminant analysis were the most effective tools for situations in which known groups were not homogeneous, whereas LDA, LR, and GAM had the highest rates of misclassification. Implications of these results for theory and practice are discussed.
使用标准统计方法(如线性判别分析(LDA)或逻辑回归(LR))进行分类,前提是在开发预测算法之前就已经了解了组别的成员身份。然而,在许多实际应用中,同一名义群体的成员实际上可能来自潜在结构中的不同亚群。例如,被诊断患有抑郁症的个体并不一定都具有相同程度的这种疾病,但出于 LDA 或 LR 的目的,他们将以相同的方式进行治疗。本模拟研究的目的是检验几种群组分类方法在组内成员不具有同质性的情况下的性能。例如,假设存在 3 个已知组,但每个组内有两个未知类别。比较了几种方法,包括 LDA、LR、分类和回归树(CART)、广义加性模型(GAM)和混合判别分析(MIXDA)。研究结果表明,CART 和混合判别分析是用于已知组不具有同质性的情况的最有效工具,而 LDA、LR 和 GAM 的分类错误率最高。讨论了这些结果对理论和实践的影响。