Tyzack Jonathan D, Mussa Hamse Y, Williamson Mark J, Kirchmair Johannes, Glen Robert C
Unilever Centre for Molecular Science Informatics, Department of Chemistry, University of Cambridge, Lensfield Road, CB2 1EW Cambridge, UK.
ETH Zurich, Department of Chemistry and Applied Biosciences, Institute of Pharmaceutical Sciences, HCI G 474.2, Vladimir-Prelog-Weg 1-5/10, 8093 Zurich, Switzerland.
J Cheminform. 2014 May 27;6:29. doi: 10.1186/1758-2946-6-29. eCollection 2014.
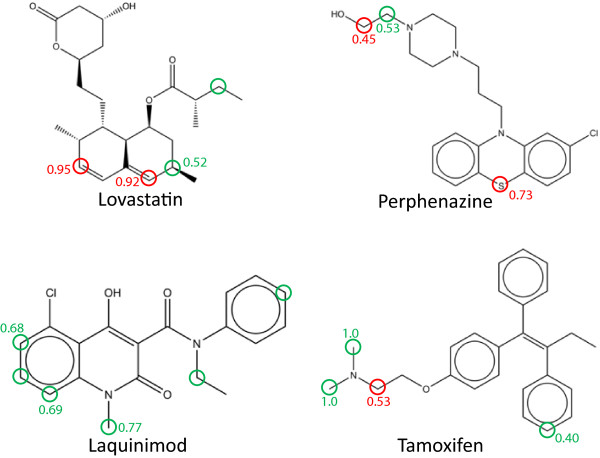
The prediction of sites and products of metabolism in xenobiotic compounds is key to the development of new chemical entities, where screening potential metabolites for toxicity or unwanted side-effects is of crucial importance. In this work 2D topological fingerprints are used to encode atomic sites and three probabilistic machine learning methods are applied: Parzen-Rosenblatt Window (PRW), Naive Bayesian (NB) and a novel approach called RASCAL (Random Attribute Subsampling Classification ALgorithm). These are implemented by randomly subsampling descriptor space to alleviate the problem often suffered by data mining methods of having to exactly match fingerprints, and in the case of PRW by measuring a distance between feature vectors rather than exact matching. The classifiers have been implemented in CUDA/C++ to exploit the parallel architecture of graphical processing units (GPUs) and is freely available in a public repository.
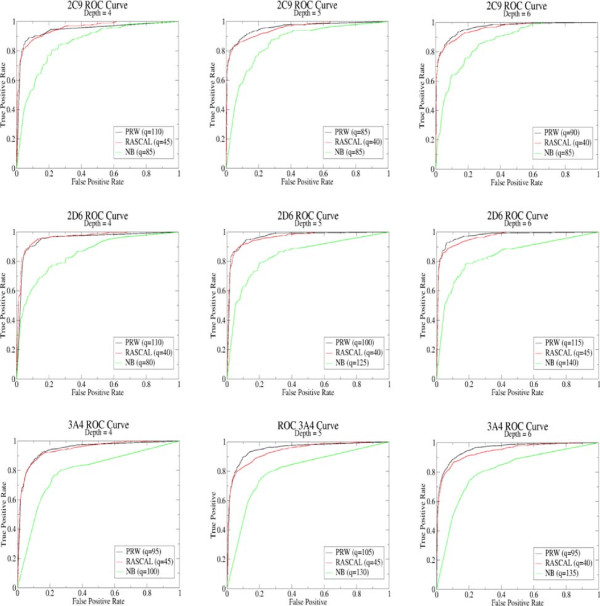
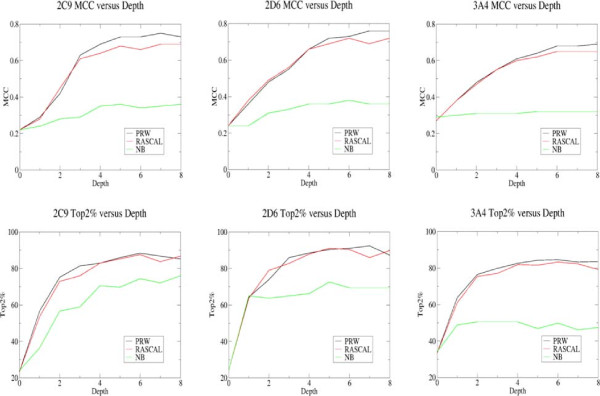
It is shown that for PRW a SoM (Site of Metabolism) is identified in the top two predictions for 85%, 91% and 88% of the CYP 3A4, 2D6 and 2C9 data sets respectively, with RASCAL giving similar performance of 83%, 91% and 88%, respectively. These results put PRW and RASCAL performance ahead of NB which gave a much lower classification performance of 51%, 73% and 74%, respectively.
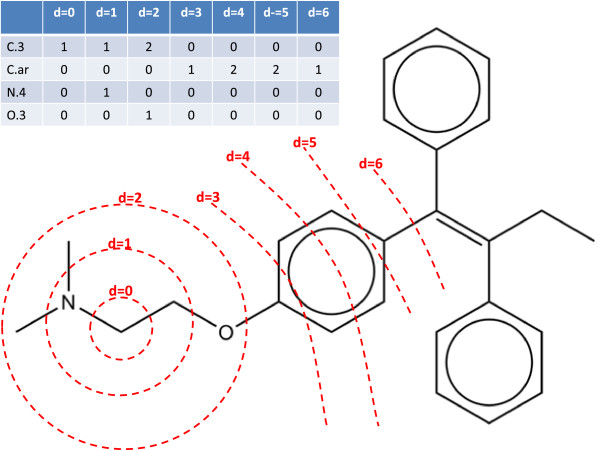
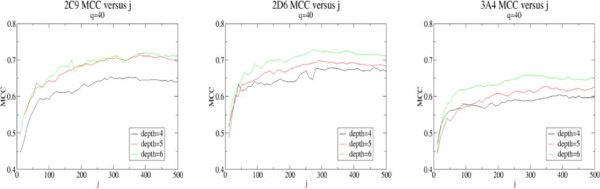
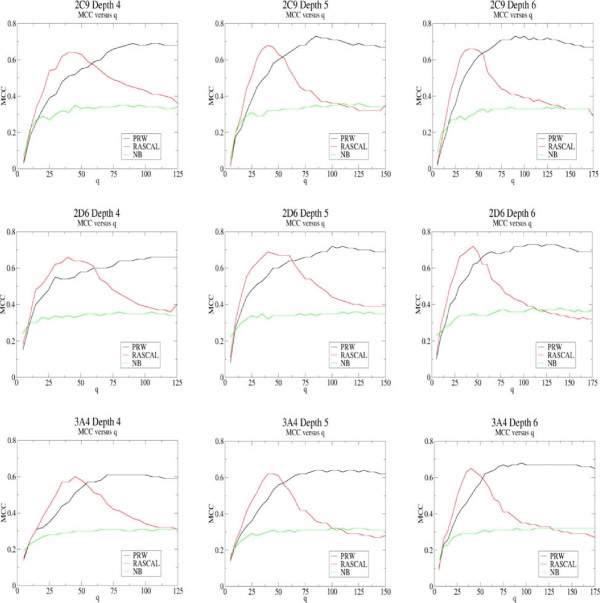
2D topological fingerprints calculated to a bond depth of 4-6 contain sufficient information to allow the identification of SoMs using classifiers based on relatively small data sets. Thus, the machine learning methods outlined in this paper are conceptually simpler and more efficient than other methods tested and the use of simple topological descriptors derived from 2D structure give results competitive with other approaches using more expensive quantum chemical descriptors. The descriptor space subsampling approach and ensemble methodology allow the methods to be applied to molecules more distant from the training data where data mining would be more likely to fail due to the lack of common fingerprints. The RASCAL algorithm is shown to give equivalent classification performance to PRW but at lower computational expense allowing it to be applied more efficiently in the ensemble scheme.
预测异源生物化合物的代谢位点和产物是新化学实体开发的关键,其中筛选潜在代谢物的毒性或不良副作用至关重要。在这项工作中,使用二维拓扑指纹对原子位点进行编码,并应用了三种概率机器学习方法:Parzen-Rosenblatt窗口法(PRW)、朴素贝叶斯法(NB)和一种名为RASCAL(随机属性子采样分类算法)的新方法。这些方法通过对描述符空间进行随机子采样来实现,以缓解数据挖掘方法经常遇到的必须精确匹配指纹的问题,对于PRW方法,通过测量特征向量之间的距离而不是精确匹配来实现。这些分类器已在CUDA/C++中实现,以利用图形处理单元(GPU)的并行架构,并且可在公共存储库中免费获取。
结果表明,对于PRW,在CYP 3A4、2D6和2C9数据集的前两个预测中分别有85%、91%和88%识别出代谢位点(SoM),RASCAL的表现与之相似,分别为83%、91%和88%。这些结果使PRW和RASCAL的性能优于NB,NB的分类性能要低得多,分别为51%、73%和74%。
计算到键深度为4 - 6的二维拓扑指纹包含足够的信息,能够使用基于相对较小数据集建立的分类器来识别代谢位点。因此,本文概述的机器学习方法在概念上比其他测试方法更简单、更高效,并且使用从二维结构导出的简单拓扑描述符所得到的结果与使用更昂贵的量子化学描述符的其他方法具有竞争力。描述符空间子采样方法和集成方法使这些方法能够应用于与训练数据差异更大的分子,在这种情况下,由于缺乏共同指纹,数据挖掘更有可能失败。结果表明,RASCAL算法与PRW具有同等的分类性能,但计算成本更低,使其能够在集成方案中更高效地应用。