Xu Ruifeng, Zhou Jiyun, Liu Bin, Yao Lin, He Yulan, Zou Quan, Wang Xiaolong
School of Computer Science and Technology, Harbin Institute of Technology Shenzhen Graduate School, Shenzhen, Guangdong 518055, China ; Key Laboratory of Network Oriented Intelligent Computation, Harbin Institute of Technology Shenzhen Graduate School, Shenzhen, Guangdong 518055, China.
School of Computer Science and Technology, Harbin Institute of Technology Shenzhen Graduate School, Shenzhen, Guangdong 518055, China.
Biomed Res Int. 2014;2014:294279. doi: 10.1155/2014/294279. Epub 2014 May 26.
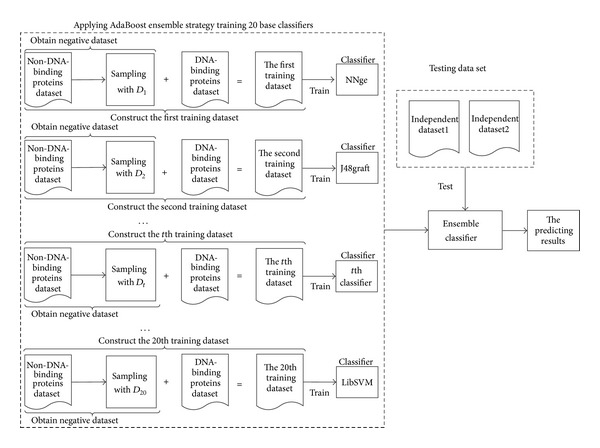
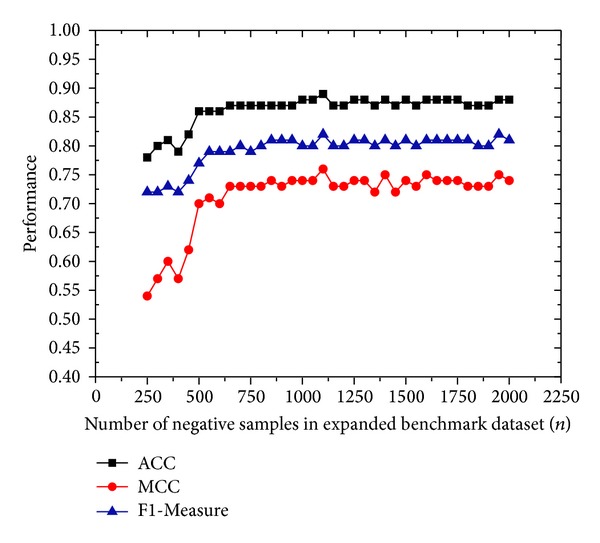
DNA-binding proteins are crucial for various cellular processes, such as recognition of specific nucleotide, regulation of transcription, and regulation of gene expression. Developing an effective model for identifying DNA-binding proteins is an urgent research problem. Up to now, many methods have been proposed, but most of them focus on only one classifier and cannot make full use of the large number of negative samples to improve predicting performance. This study proposed a predictor called enDNA-Prot for DNA-binding protein identification by employing the ensemble learning technique. Experiential results showed that enDNA-Prot was comparable with DNA-Prot and outperformed DNAbinder and iDNA-Prot with performance improvement in the range of 3.97-9.52% in ACC and 0.08-0.19 in MCC. Furthermore, when the benchmark dataset was expanded with negative samples, the performance of enDNA-Prot outperformed the three existing methods by 2.83-16.63% in terms of ACC and 0.02-0.16 in terms of MCC. It indicated that enDNA-Prot is an effective method for DNA-binding protein identification and expanding training dataset with negative samples can improve its performance. For the convenience of the vast majority of experimental scientists, we developed a user-friendly web-server for enDNA-Prot which is freely accessible to the public.
DNA结合蛋白对于各种细胞过程至关重要,例如识别特定核苷酸、转录调控和基因表达调控。开发一种有效的DNA结合蛋白识别模型是一个亟待解决的研究问题。到目前为止,已经提出了许多方法,但大多数方法只关注单一分类器,无法充分利用大量负样本提高预测性能。本研究提出了一种名为enDNA-Prot的预测器,通过采用集成学习技术来识别DNA结合蛋白。实验结果表明,enDNA-Prot与DNA-Prot相当,并且在ACC方面的性能提升范围为3.97-9.52%,在MCC方面的性能提升范围为0.08-0.19,优于DNAbinder和iDNA-Prot。此外,当使用负样本扩展基准数据集时,enDNA-Prot在ACC方面比三种现有方法高出2.83-16.63%,在MCC方面高出0.02-0.16。这表明enDNA-Prot是一种识别DNA结合蛋白的有效方法,使用负样本扩展训练数据集可以提高其性能。为方便广大实验科学家使用,我们为enDNA-Prot开发了一个用户友好的网络服务器,公众可免费访问。