Feng Changli, Ma Zhaogui, Yang Deyun, Li Xin, Zhang Jun, Li Yanjuan
College of Information Science and Technology, Taishan University, Tai'an, China.
Department of Rehabilitation, General Hospital of Heilongjiang Province Land Reclamation Bureau, Harbin, China.
Front Bioeng Biotechnol. 2020 May 5;8:285. doi: 10.3389/fbioe.2020.00285. eCollection 2020.
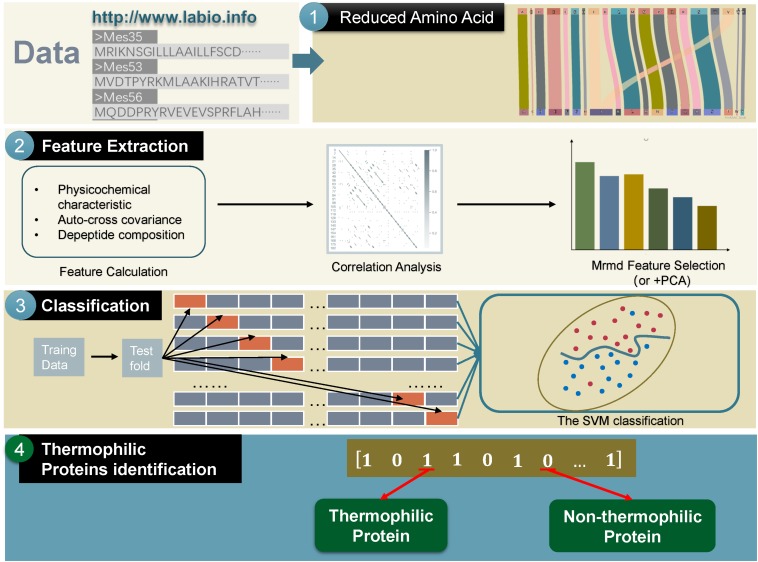
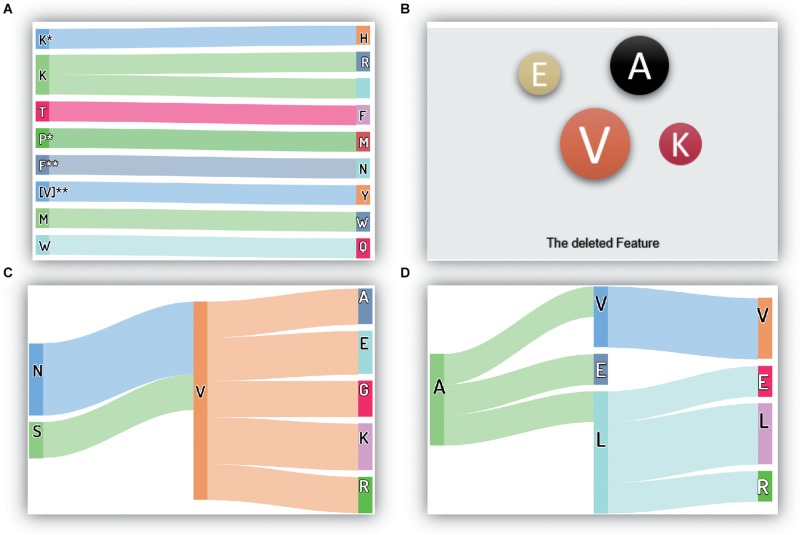
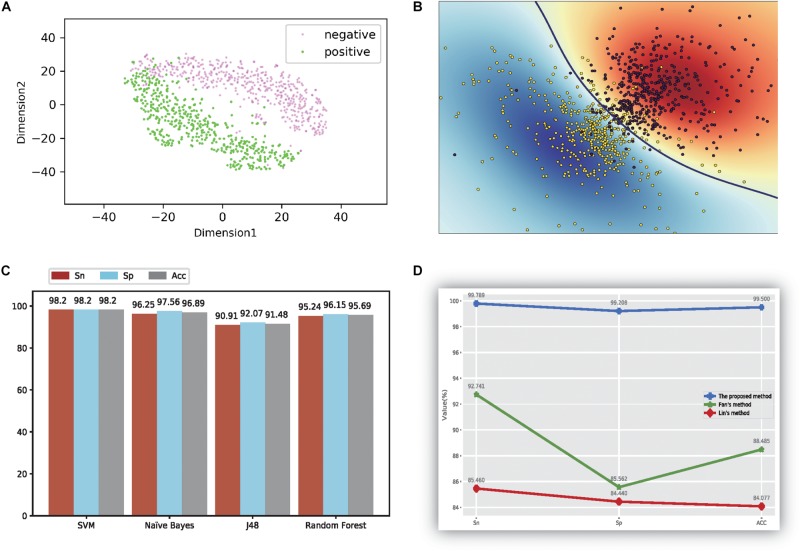
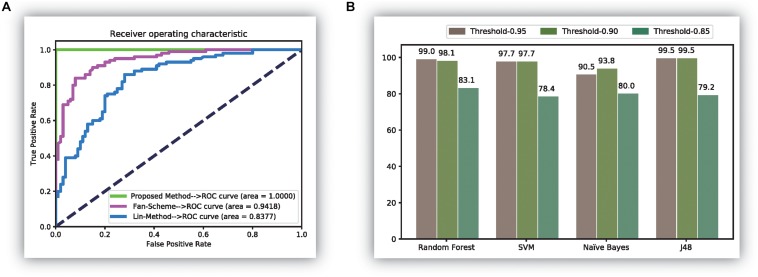
The thermostability of proteins is a key factor considered during enzyme engineering, and finding a method that can identify thermophilic and non-thermophilic proteins will be helpful for enzyme design. In this study, we established a novel method combining mixed features and machine learning to achieve this recognition task. In this method, an amino acid reduction scheme was adopted to recode the amino acid sequence. Then, the physicochemical characteristics, auto-cross covariance (ACC), and reduced dipeptides were calculated and integrated to form a mixed feature set, which was processed using correlation analysis, feature selection, and principal component analysis (PCA) to remove redundant information. Finally, four machine learning methods and a dataset containing 500 random observations out of 915 thermophilic proteins and 500 random samples out of 793 non-thermophilic proteins were used to train and predict the data. The experimental results showed that 98.2% of thermophilic and non-thermophilic proteins were correctly identified using 10-fold cross-validation. Moreover, our analysis of the final reserved features and removed features yielded information about the crucial, unimportant and insensitive elements, it also provided essential information for enzyme design.
蛋白质的热稳定性是酶工程中考虑的关键因素,找到一种能够识别嗜热蛋白和非嗜热蛋白的方法将有助于酶的设计。在本研究中,我们建立了一种结合混合特征和机器学习的新方法来完成这一识别任务。在该方法中,采用氨基酸缩减方案对氨基酸序列进行重新编码。然后,计算并整合物理化学特征、自交叉协方差(ACC)和缩减二肽,形成一个混合特征集,使用相关分析、特征选择和主成分分析(PCA)对其进行处理以去除冗余信息。最后,使用四种机器学习方法以及一个数据集进行数据训练和预测,该数据集包含从915个嗜热蛋白中随机选取的500个观测值以及从793个非嗜热蛋白中随机选取的500个样本。实验结果表明,使用10折交叉验证时,98.2%的嗜热蛋白和非嗜热蛋白被正确识别。此外,我们对最终保留特征和去除特征的分析产生了关于关键、不重要和不敏感元素的信息,这也为酶的设计提供了重要信息。