Topa Hande, Jónás Ágnes, Kofler Robert, Kosiol Carolin, Honkela Antti
Helsinki Institute for Information Technology (HIIT), Department of Information and Computer Science, Aalto University, Espoo, Finland, Institut für Populationsgenetik, Vetmeduni Vienna, 1210 Wien, Austria, Vienna Graduate School of Population Genetics, Wien, Austria and Helsinki Institute for Information Technology (HIIT), Department of Computer Science, University of Helsinki, Helsinki, Finland.
Helsinki Institute for Information Technology (HIIT), Department of Information and Computer Science, Aalto University, Espoo, Finland, Institut für Populationsgenetik, Vetmeduni Vienna, 1210 Wien, Austria, Vienna Graduate School of Population Genetics, Wien, Austria and Helsinki Institute for Information Technology (HIIT), Department of Computer Science, University of Helsinki, Helsinki, Finland Helsinki Institute for Information Technology (HIIT), Department of Information and Computer Science, Aalto University, Espoo, Finland, Institut für Populationsgenetik, Vetmeduni Vienna, 1210 Wien, Austria, Vienna Graduate School of Population Genetics, Wien, Austria and Helsinki Institute for Information Technology (HIIT), Department of Computer Science, University of Helsinki, Helsinki, Finland.
Bioinformatics. 2015 Jun 1;31(11):1762-70. doi: 10.1093/bioinformatics/btv014. Epub 2015 Jan 21.
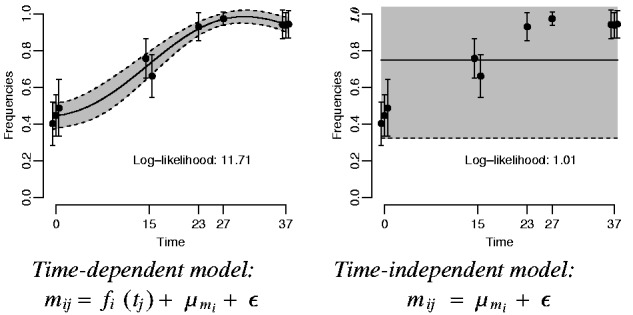
Recent advances in high-throughput sequencing (HTS) have made it possible to monitor genomes in great detail. New experiments not only use HTS to measure genomic features at one time point but also monitor them changing over time with the aim of identifying significant changes in their abundance. In population genetics, for example, allele frequencies are monitored over time to detect significant frequency changes that indicate selection pressures. Previous attempts at analyzing data from HTS experiments have been limited as they could not simultaneously include data at intermediate time points, replicate experiments and sources of uncertainty specific to HTS such as sequencing depth.
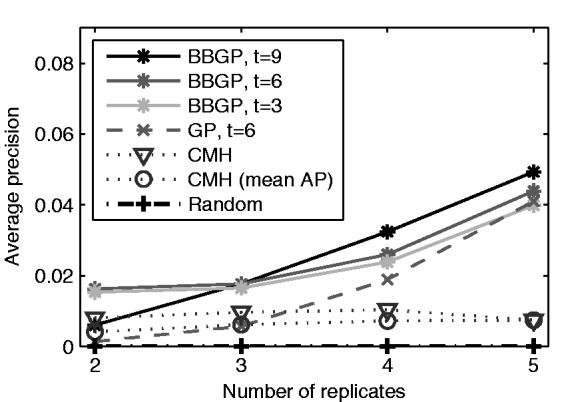
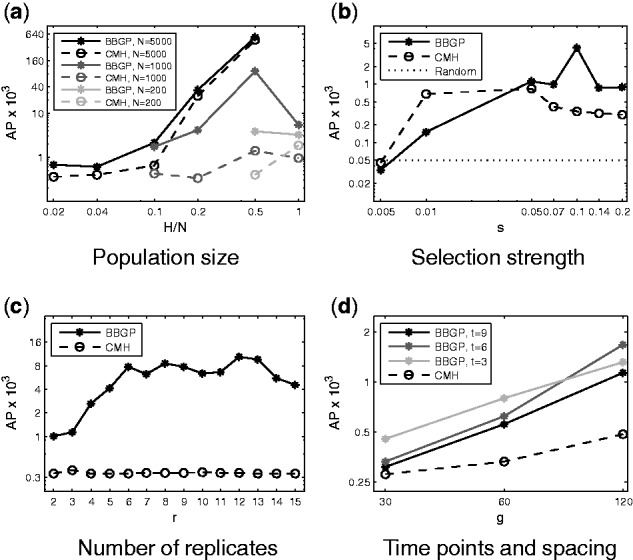
We present the beta-binomial Gaussian process model for ranking features with significant non-random variation in abundance over time. The features are assumed to represent proportions, such as proportion of an alternative allele in a population. We use the beta-binomial model to capture the uncertainty arising from finite sequencing depth and combine it with a Gaussian process model over the time series. In simulations that mimic the features of experimental evolution data, the proposed method clearly outperforms classical testing in average precision of finding selected alleles. We also present simulations exploring different experimental design choices and results on real data from Drosophila experimental evolution experiment in temperature adaptation.
R software implementing the test is available at https://github.com/handetopa/BBGP.
高通量测序(HTS)的最新进展使得详细监测基因组成为可能。新的实验不仅使用HTS在一个时间点测量基因组特征,还监测它们随时间的变化,目的是识别其丰度的显著变化。例如,在群体遗传学中,等位基因频率随时间被监测,以检测表明选择压力的显著频率变化。先前分析HTS实验数据的尝试受到限制,因为它们不能同时包含中间时间点的数据、重复实验以及HTS特有的不确定性来源,如测序深度。
我们提出了贝塔 - 二项式高斯过程模型,用于对随时间具有显著非随机丰度变化的特征进行排名。这些特征被假定代表比例,例如群体中替代等位基因的比例。我们使用贝塔 - 二项式模型来捕捉由于有限测序深度产生的不确定性,并将其与时间序列上的高斯过程模型相结合。在模拟实验进化数据特征的模拟中,所提出的方法在找到选定等位基因的平均精度方面明显优于经典测试。我们还展示了探索不同实验设计选择的模拟以及来自果蝇温度适应实验进化实验的真实数据的结果。
实现该测试的R软件可在https://github.com/handetopa/BBGP获取。