Masconi Katya L, Matsha Tandi E, Echouffo-Tcheugui Justin B, Erasmus Rajiv T, Kengne Andre P
Division of Chemical Pathology, Faculty of Health Sciences, National Health Laboratory Service (NHLS) and University of Stellenbosch, Cape Town, South Africa ; Non-Communicable Diseases Research Unit, South African Medical Research Council, PO Box 19070, , Tygerberg, 7505 Cape Town, South Africa.
Department of Biomedical Technology, Faculty of Health and Wellness Sciences, Cape Peninsula University of Technology, Cape Town, South Africa.
EPMA J. 2015 Mar 11;6(1):7. doi: 10.1186/s13167-015-0028-0. eCollection 2015.
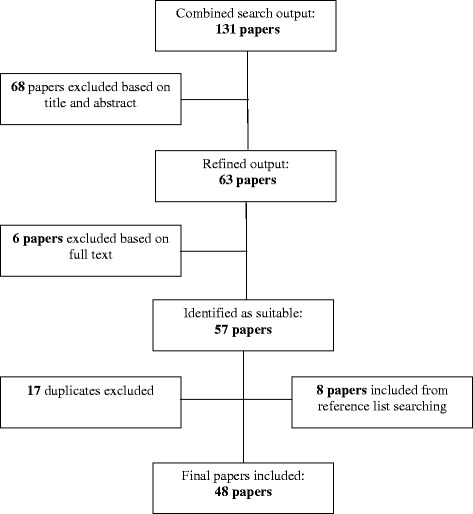
Missing values are common in health research and omitting participants with missing data often leads to loss of statistical power, biased estimates and, consequently, inaccurate inferences. We critically reviewed the challenges posed by missing data in medical research and approaches to address them. To achieve this more efficiently, these issues were analyzed and illustrated through a systematic review on the reporting of missing data and imputation methods (prediction of missing values through relationships within and between variables) undertaken in risk prediction studies of undiagnosed diabetes. Prevalent diabetes risk models were selected based on a recent comprehensive systematic review, supplemented by an updated search of English-language studies published between 1997 and 2014. Reporting of missing data has been limited in studies of prevalent diabetes prediction. Of the 48 articles identified, 62.5% (n = 30) did not report any information on missing data or handling techniques. In 21 (43.8%) studies, researchers opted out of imputation, completing case-wise deletion of participants missing any predictor values. Although imputation methods are encouraged to handle missing data and ensure the accuracy of inferences, this has seldom been the case in studies of diabetes risk prediction. Hence, we elaborated on the various types and patterns of missing data, the limitations of case-wise deletion and state-of the-art methods of imputations and their challenges. This review highlights the inexperience or disregard of investigators of the effect of missing data in risk prediction research. Formal guidelines may enhance the reporting and appropriate handling of missing data in scientific journals.
缺失值在健康研究中很常见,忽略有缺失数据的参与者往往会导致统计功效的损失、估计偏差,进而得出不准确的推断。我们批判性地审视了医学研究中缺失数据带来的挑战以及应对这些挑战的方法。为了更高效地实现这一目标,通过对未诊断糖尿病风险预测研究中缺失数据报告和插补方法(通过变量内部和变量之间的关系预测缺失值)进行系统综述,对这些问题进行了分析和阐述。基于最近一项全面的系统综述选择了常见的糖尿病风险模型,并补充了对1997年至2014年发表的英文研究的最新检索。在常见糖尿病预测研究中,缺失数据的报告一直很有限。在确定的48篇文章中,62.5%(n = 30)没有报告任何关于缺失数据或处理技术的信息。在21项(43.8%)研究中,研究人员选择不进行插补,而是对任何预测变量值缺失的参与者进行逐例删除。尽管鼓励使用插补方法来处理缺失数据并确保推断的准确性,但在糖尿病风险预测研究中情况很少如此。因此,我们阐述了缺失数据的各种类型和模式、逐例删除的局限性以及最新的插补方法及其面临的挑战。本综述强调了研究人员在风险预测研究中对缺失数据影响缺乏经验或忽视的情况。正式的指南可能会加强科学期刊中缺失数据的报告和适当处理。