Department of Biostatistics, Vanderbilt University School of Medicine, Nashville, TN, USA.
PLoS One. 2015 Apr 7;10(4):e0121263. doi: 10.1371/journal.pone.0121263. eCollection 2015.
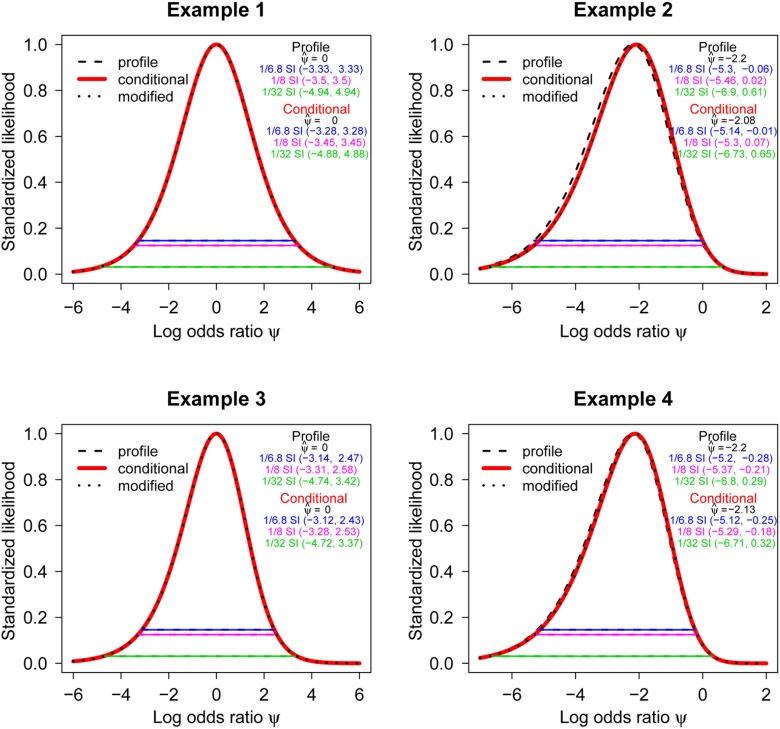
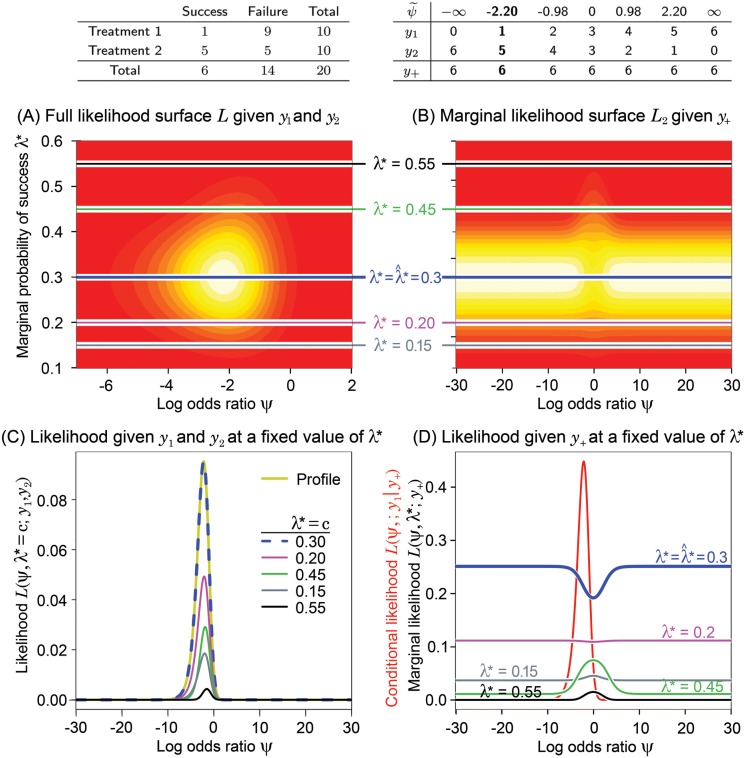
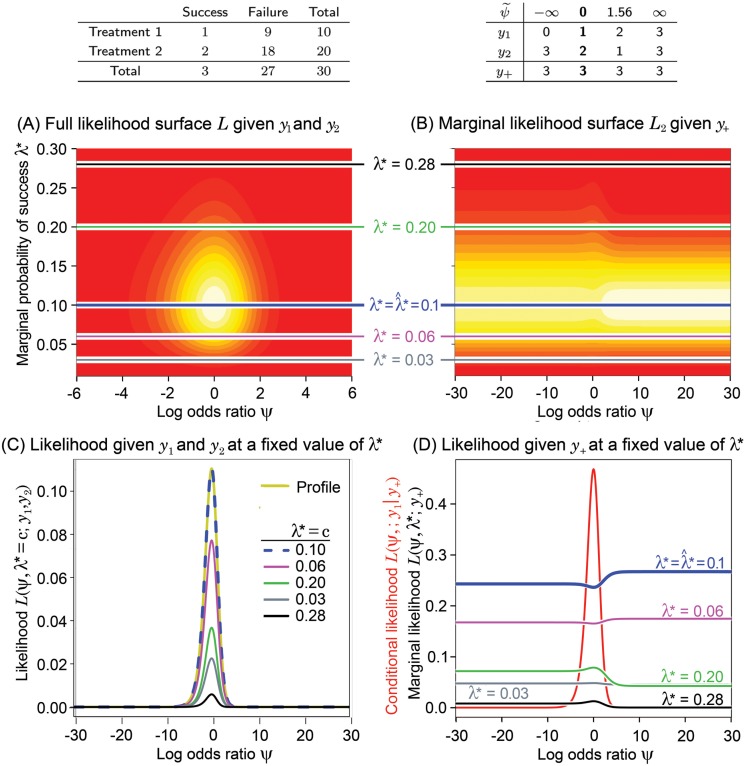
To many, the foundations of statistical inference are cryptic and irrelevant to routine statistical practice. The analysis of 2 x 2 contingency tables, omnipresent in the scientific literature, is a case in point. Fisher's exact test is routinely used even though it has been fraught with controversy for over 70 years. The problem, not widely acknowledged, is that several different p-values can be associated with a single table, making scientific inference inconsistent. The root cause of this controversy lies in the table's origins and the manner in which nuisance parameters are eliminated. However, fundamental statistical principles (e.g., sufficiency, ancillarity, conditionality, and likelihood) can shed light on the controversy and guide our approach in using this test. In this paper, we use these fundamental principles to show how much information is lost when the tables origins are ignored and when various approaches are used to eliminate unknown nuisance parameters. We present novel likelihood contours to aid in the visualization of information loss and show that the information loss is often virtually non-existent. We find that problems arising from the discreteness of the sample space are exacerbated by p-value-based inference. Accordingly, methods that are less sensitive to this discreteness - likelihood ratios, posterior probabilities and mid-p-values - lead to more consistent inferences.
对于许多人来说,统计推断的基础是神秘的,与常规统计实践无关。无处不在的 2 x 2 列联表分析就是一个例子。即使 Fisher 精确检验已经存在了 70 多年,并且存在争议,但它仍被常规使用。这个问题并没有得到广泛承认,即单个表格可能与多个 p 值相关联,从而导致科学推断不一致。这种争议的根本原因在于表格的起源以及消除干扰参数的方式。然而,基本的统计原理(例如充分性、辅助性、条件性和似然性)可以阐明争议,并指导我们使用该检验的方法。在本文中,我们使用这些基本原则来展示当忽略表格的起源以及使用各种方法来消除未知干扰参数时,会丢失多少信息。我们提出了新的似然轮廓来帮助可视化信息丢失,并表明信息丢失通常实际上不存在。我们发现,由于样本空间的离散性而产生的问题因基于 p 值的推断而加剧。因此,不太敏感于这种离散性的方法 - 似然比、后验概率和中值 p 值 - 会导致更一致的推断。