Somervuo Panu, Holm Liisa
Institute of Biotechnology, University of Helsinki, PO Box 65, Finland Department of Biosciences, University of Helsinki, PO Box 65, Finland.
Institute of Biotechnology, University of Helsinki, PO Box 65, Finland Department of Biosciences, University of Helsinki, PO Box 65, Finland
Nucleic Acids Res. 2015 Jul 1;43(W1):W24-9. doi: 10.1093/nar/gkv317. Epub 2015 Apr 8.
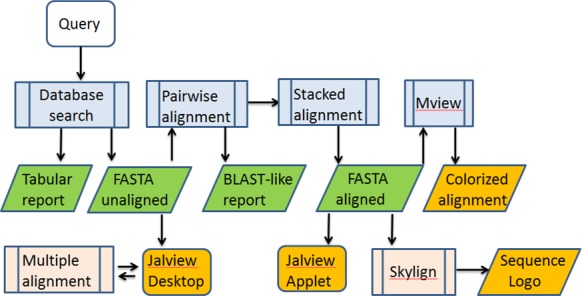
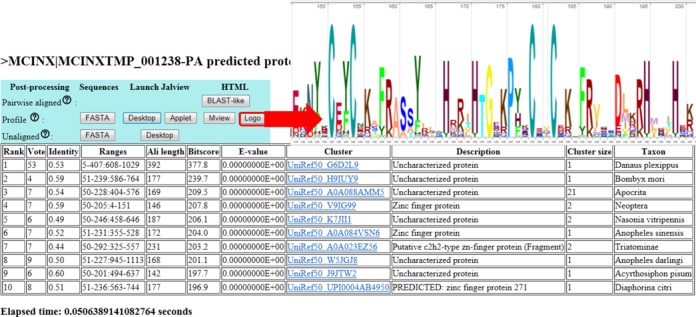
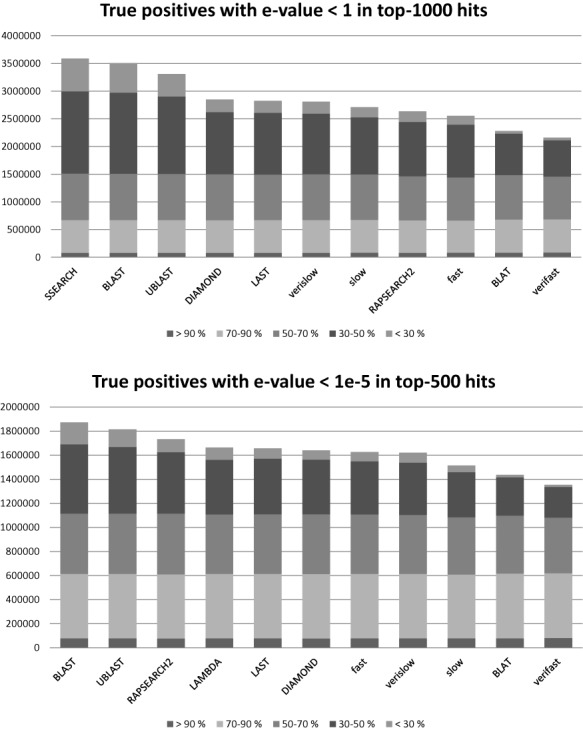
Proteins evolve by mutations and natural selection. The network of sequence similarities is a rich source for mining homologous relationships that inform on protein structure and function. There are many servers available to browse the network of homology relationships but one has to wait up to a minute for results. The SANSparallel webserver provides protein sequence database searches with immediate response and professional alignment visualization by third-party software. The output is a list, pairwise alignment or stacked alignment of sequence-similar proteins from Uniprot, UniRef90/50, Swissprot or Protein Data Bank. The stacked alignments are viewed in Jalview or as sequence logos. The database search uses the suffix array neighborhood search (SANS) method, which has been re-implemented as a client-server, improved and parallelized. The method is extremely fast and as sensitive as BLAST above 50% sequence identity. Benchmarks show that the method is highly competitive compared to previously published fast database search programs: UBLAST, DIAMOND, LAST, LAMBDA, RAPSEARCH2 and BLAT. The web server can be accessed interactively or programmatically at http://ekhidna2.biocenter.helsinki.fi/cgi-bin/sans/sans.cgi. It can be used to make protein functional annotation pipelines more efficient, and it is useful in interactive exploration of the detailed evidence supporting the annotation of particular proteins of interest.
蛋白质通过突变和自然选择进化。序列相似性网络是挖掘同源关系的丰富资源,这些同源关系可为蛋白质结构和功能提供信息。有许多服务器可用于浏览同源关系网络,但获取结果可能需要等待长达一分钟。SANSparallel网络服务器提供蛋白质序列数据库搜索,并能通过第三方软件立即给出响应并进行专业的比对可视化。输出结果是来自UniProt、UniRef90/50、SwissProt或蛋白质数据库的序列相似蛋白质的列表、两两比对或堆叠比对。堆叠比对可以在Jalview中查看,也可以显示为序列标识。数据库搜索使用后缀数组邻域搜索(SANS)方法,该方法已重新实现为客户端-服务器模式,经过改进并实现了并行化。该方法极其快速,在序列同一性高于50%时与BLAST一样灵敏。基准测试表明,与之前发布的快速数据库搜索程序:UBLAST、DIAMOND、LAST、LAMBDA、RAPSEARCH2和BLAT相比,该方法具有很强的竞争力。可以通过http://ekhidna2.biocenter.helsinki.fi/cgi-bin/sans/sans.cgi以交互方式或编程方式访问该网络服务器。它可用于提高蛋白质功能注释管道的效率,并且在交互式探索支持特定感兴趣蛋白质注释的详细证据方面很有用。