McGarvey Kelly M, Goldfarb Tamara, Cox Eric, Farrell Catherine M, Gupta Tripti, Joardar Vinita S, Kodali Vamsi K, Murphy Michael R, O'Leary Nuala A, Pujar Shashikant, Rajput Bhanu, Rangwala Sanjida H, Riddick Lillian D, Webb David, Wright Mathew W, Murphy Terence D, Pruitt Kim D
National Center for Biotechnology Information, National Library of Medicine, National Institutes of Health, Building 38A, 8600 Rockville Pike, Bethesda, MD, 20894, USA.
Mamm Genome. 2015 Oct;26(9-10):379-90. doi: 10.1007/s00335-015-9585-8. Epub 2015 Jul 28.
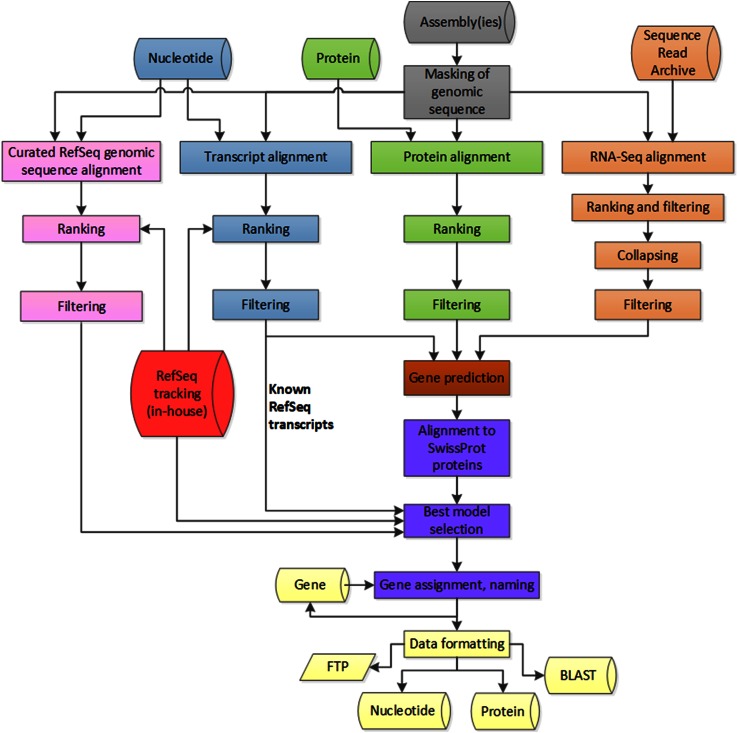
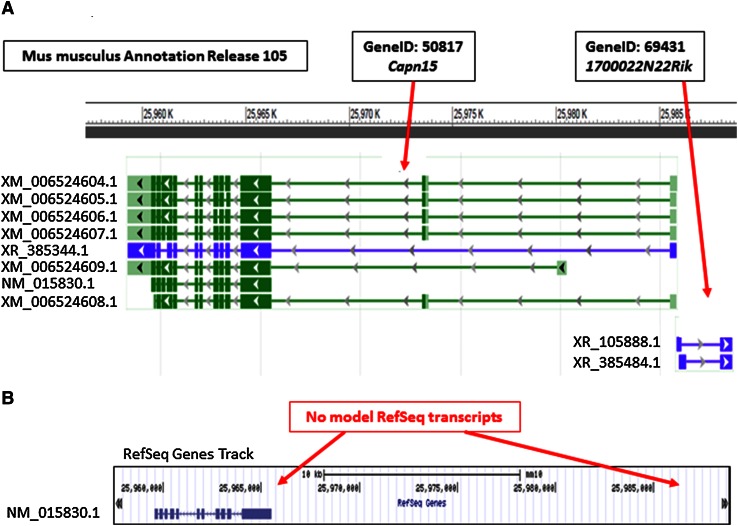
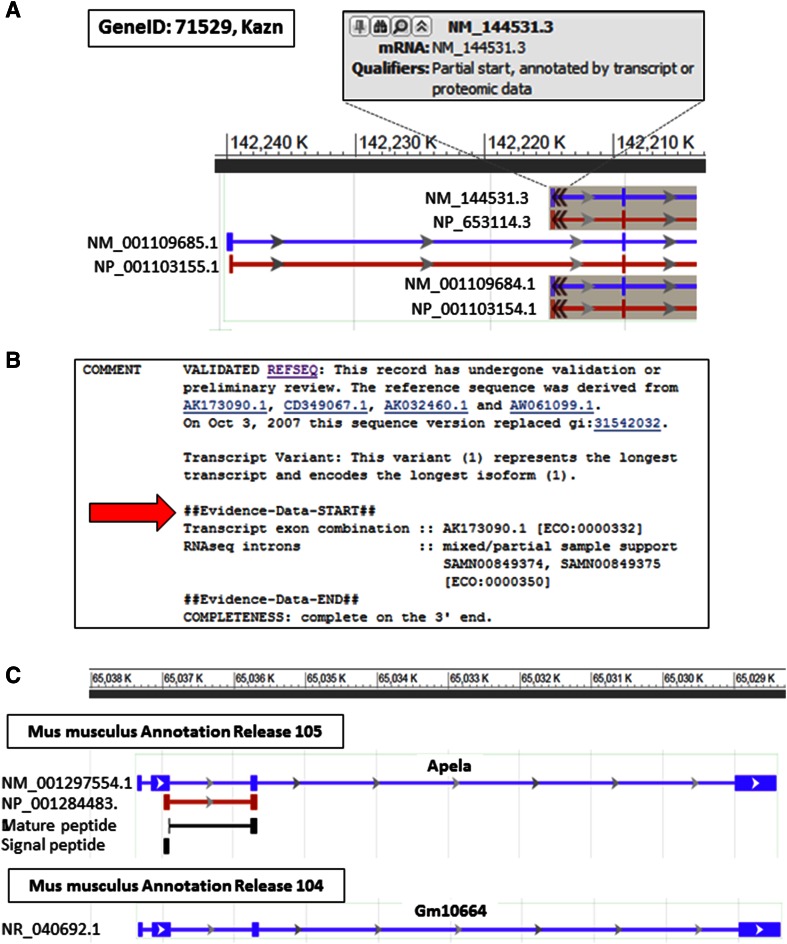
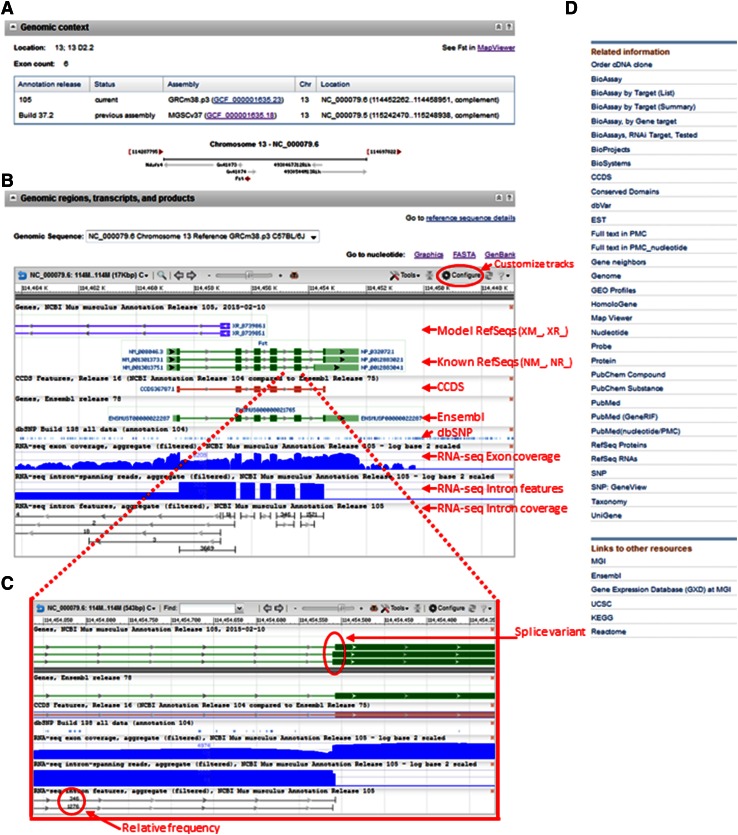
Complete and accurate annotation of the mouse genome is critical to the advancement of research conducted on this important model organism. The National Center for Biotechnology Information (NCBI) develops and maintains many useful resources to assist the mouse research community. In particular, the reference sequence (RefSeq) database provides high-quality annotation of multiple mouse genome assemblies using a combinatorial approach that leverages computation, manual curation, and collaboration. Implementation of this conservative and rigorous approach, which focuses on representation of only full-length and non-redundant data, produces high-quality annotation products. RefSeq records explicitly link sequences to current knowledge in a timely manner, updating public records regularly and rapidly in response to nomenclature updates, addition of new relevant publications, collaborator discussion, and user feedback. Whole genome re-annotation is also conducted at least every 12-18 months, and often more frequently in response to assembly updates or availability of informative data. This article highlights key features and advantages of RefSeq genome annotation products and presents an overview of NCBI processes to generate these data. Further discussion of NCBI's resources highlights useful features and the best methods for accessing our data.
对小鼠基因组进行完整准确的注释对于利用这一重要模式生物开展的研究进展至关重要。美国国家生物技术信息中心(NCBI)开发并维护了许多有用的资源来协助小鼠研究群体。特别是,参考序列(RefSeq)数据库采用了一种结合计算、人工整理和合作的组合方法,为多个小鼠基因组组装提供高质量注释。这种保守且严谨的方法注重仅呈现全长和非冗余数据,从而产生高质量的注释产物。RefSeq记录及时将序列与当前知识明确关联,根据命名法更新、新相关出版物的添加、合作者讨论及用户反馈,定期且迅速地更新公共记录。全基因组重新注释至少每12 - 18个月进行一次,并且常常因应组装更新或信息性数据的可得性而更频繁地开展。本文重点介绍了RefSeq基因组注释产物的关键特征和优势,并概述了NCBI生成这些数据的流程。对NCBI资源的进一步讨论突出了有用的特征以及获取我们数据的最佳方法。