Percha Bethany, Altman Russ B
Biomedical Informatics Training Program, Stanford University, Stanford, California, United States of America.
Departments of Medicine, Genetics and Bioengineering, Stanford University, Stanford, California, United States of America.
PLoS Comput Biol. 2015 Jul 28;11(7):e1004216. doi: 10.1371/journal.pcbi.1004216. eCollection 2015 Jul.
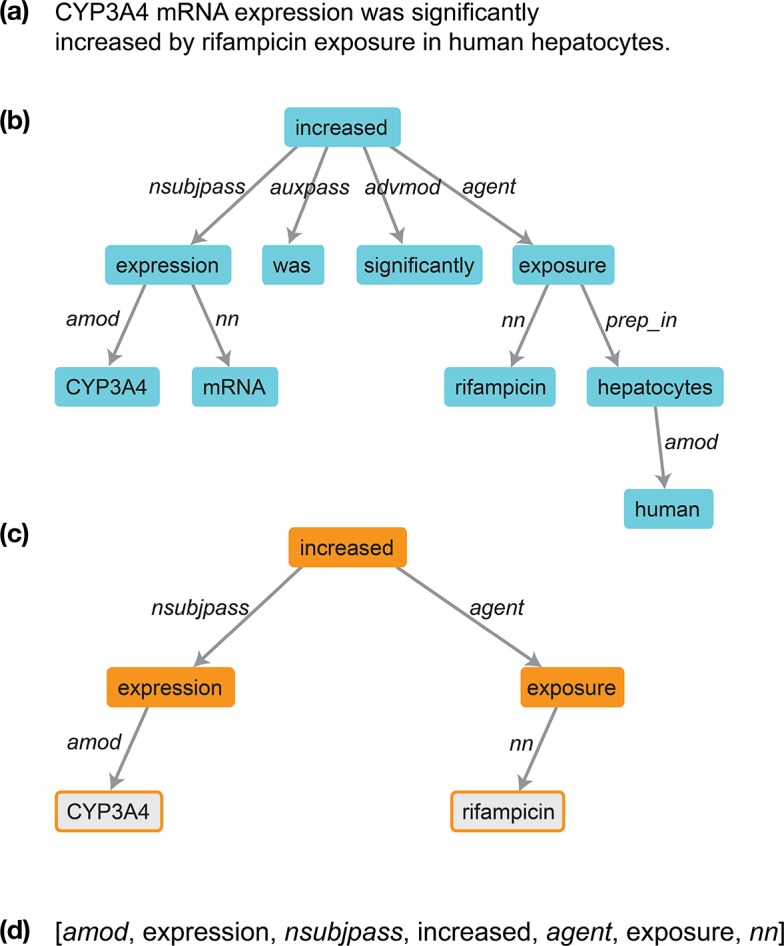
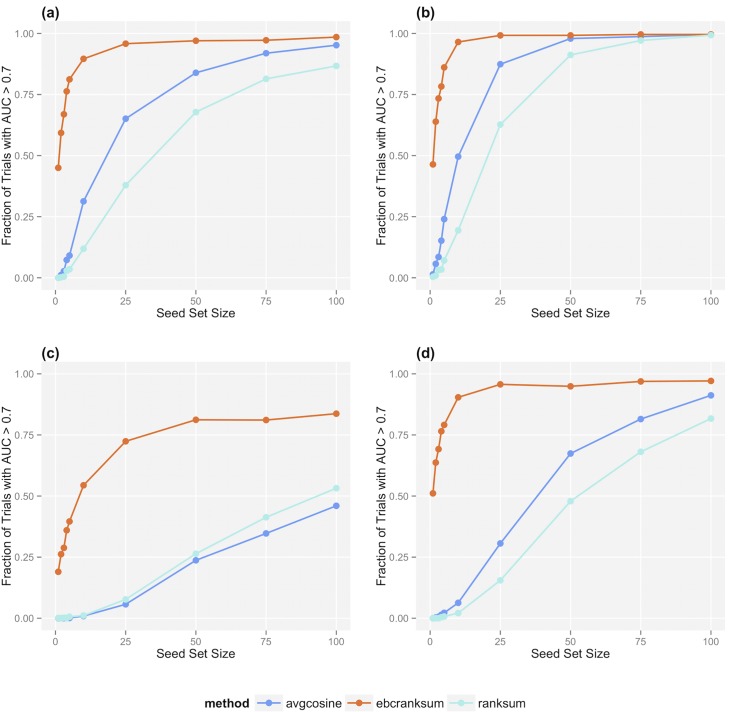
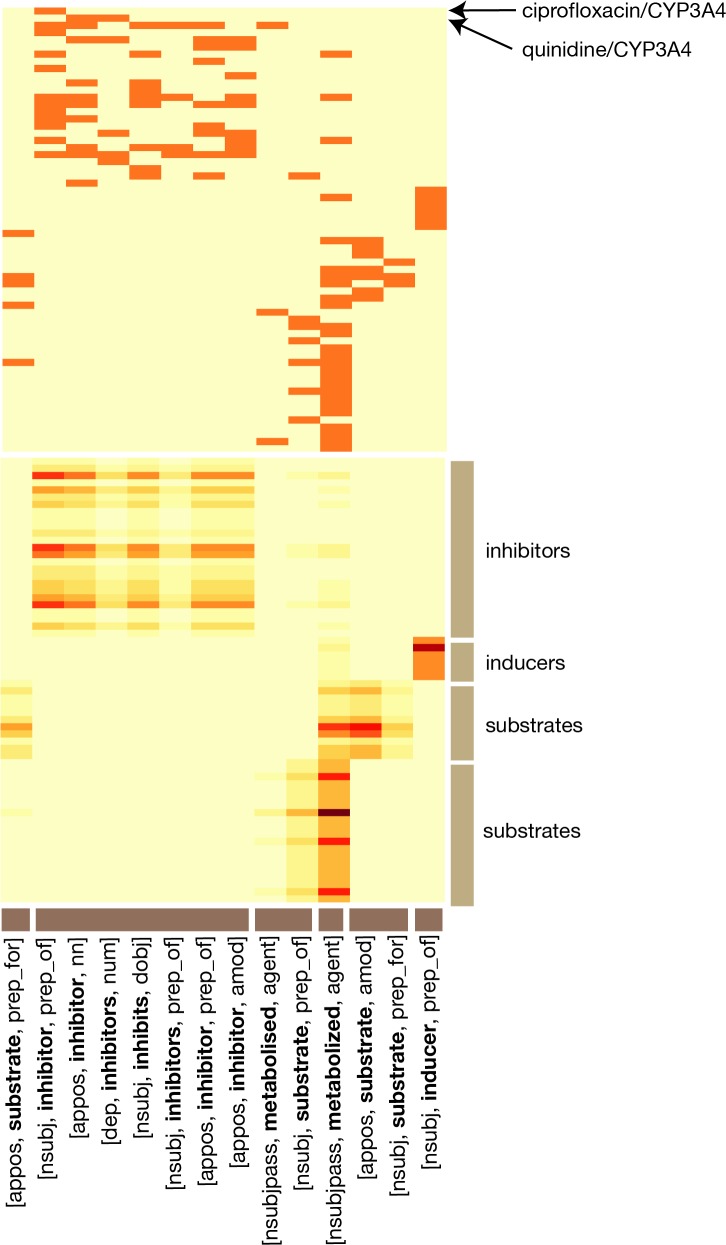
The published biomedical research literature encompasses most of our understanding of how drugs interact with gene products to produce physiological responses (phenotypes). Unfortunately, this information is distributed throughout the unstructured text of over 23 million articles. The creation of structured resources that catalog the relationships between drugs and genes would accelerate the translation of basic molecular knowledge into discoveries of genomic biomarkers for drug response and prediction of unexpected drug-drug interactions. Extracting these relationships from natural language sentences on such a large scale, however, requires text mining algorithms that can recognize when different-looking statements are expressing similar ideas. Here we describe a novel algorithm, Ensemble Biclustering for Classification (EBC), that learns the structure of biomedical relationships automatically from text, overcoming differences in word choice and sentence structure. We validate EBC's performance against manually-curated sets of (1) pharmacogenomic relationships from PharmGKB and (2) drug-target relationships from DrugBank, and use it to discover new drug-gene relationships for both knowledge bases. We then apply EBC to map the complete universe of drug-gene relationships based on their descriptions in Medline, revealing unexpected structure that challenges current notions about how these relationships are expressed in text. For instance, we learn that newer experimental findings are described in consistently different ways than established knowledge, and that seemingly pure classes of relationships can exhibit interesting chimeric structure. The EBC algorithm is flexible and adaptable to a wide range of problems in biomedical text mining.
已发表的生物医学研究文献涵盖了我们对药物如何与基因产物相互作用以产生生理反应(表型)的大部分理解。不幸的是,这些信息分布在超过2300万篇文章的非结构化文本中。创建编目药物与基因之间关系的结构化资源将加速将基础分子知识转化为药物反应基因组生物标志物的发现以及预测意外的药物 - 药物相互作用。然而,要从如此大规模的自然语言句子中提取这些关系,需要能够识别不同表述何时表达相似想法的文本挖掘算法。在这里,我们描述了一种新颖的算法,即分类集成双聚类算法(EBC),它能从文本中自动学习生物医学关系的结构,克服了词汇选择和句子结构的差异。我们对照(1)来自PharmGKB的药物基因组学关系和(2)来自DrugBank的药物 - 靶点关系的人工整理集验证了EBC的性能,并使用它为两个知识库发现新的药物 - 基因关系。然后,我们应用EBC根据Medline中的描述绘制药物 - 基因关系的完整图谱,揭示了意想不到的结构,这些结构挑战了当前关于这些关系在文本中如何表达的观念。例如,我们了解到新的实验发现与既定知识的描述方式始终不同,而且看似纯粹的关系类别可能呈现出有趣的嵌合结构。EBC算法灵活且适用于生物医学文本挖掘中的广泛问题。