Université de Lorraine, CNRS, Inria, LORIA, Nancy, France.
Sorbonne Université, INSERM, Université Paris 13, LIMICS, Paris, France.
Sci Data. 2020 Jan 2;7(1):3. doi: 10.1038/s41597-019-0342-9.
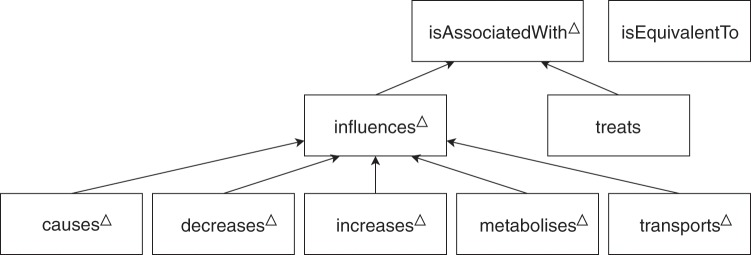
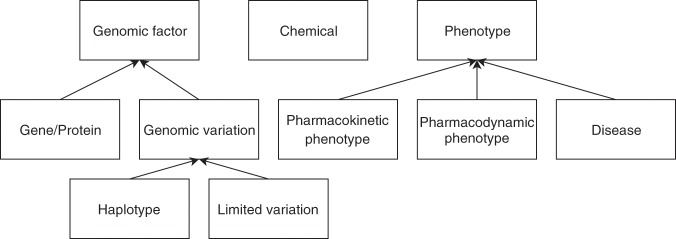
Pharmacogenomics (PGx) studies how individual gene variations impact drug response phenotypes, which makes PGx-related knowledge a key component towards precision medicine. A significant part of the state-of-the-art knowledge in PGx is accumulated in scientific publications, where it is hardly reusable by humans or software. Natural language processing techniques have been developed to guide experts who curate this amount of knowledge. But existing works are limited by the absence of a high quality annotated corpus focusing on PGx domain. In particular, this absence restricts the use of supervised machine learning. This article introduces PGxCorpus, a manually annotated corpus, designed to fill this gap and to enable the automatic extraction of PGx relationships from text. It comprises 945 sentences from 911 PubMed abstracts, annotated with PGx entities of interest (mainly gene variations, genes, drugs and phenotypes), and relationships between those. In this article, we present the corpus itself, its construction and a baseline experiment that illustrates how it may be leveraged to synthesize and summarize PGx knowledge.
药物基因组学(PGx)研究个体基因变异如何影响药物反应表型,这使得 PGx 相关知识成为精准医学的关键组成部分。PGx 领域的最新知识很大一部分都积累在科学出版物中,人类或软件很难从中重复利用。已经开发了自然语言处理技术来指导整理这些知识的专家。但是,现有的工作受到缺乏专注于 PGx 领域的高质量标注语料库的限制。特别是,这种缺乏限制了监督机器学习的使用。本文介绍了 PGxCorpus,这是一个手动标注的语料库,旨在填补这一空白,并能够从文本中自动提取 PGx 关系。它包含 911 篇 PubMed 摘要中的 945 个句子,标注了感兴趣的 PGx 实体(主要是基因变异、基因、药物和表型)以及它们之间的关系。在本文中,我们介绍了语料库本身、它的构建以及一个基线实验,该实验说明了如何利用它来综合和总结 PGx 知识。