Evotec (UK) Ltd., in silico Research and Development, Milton Park, Abingdon, Oxfordshire, United Kingdom.
PLoS One. 2023 Sep 8;18(9):e0291142. doi: 10.1371/journal.pone.0291142. eCollection 2023.
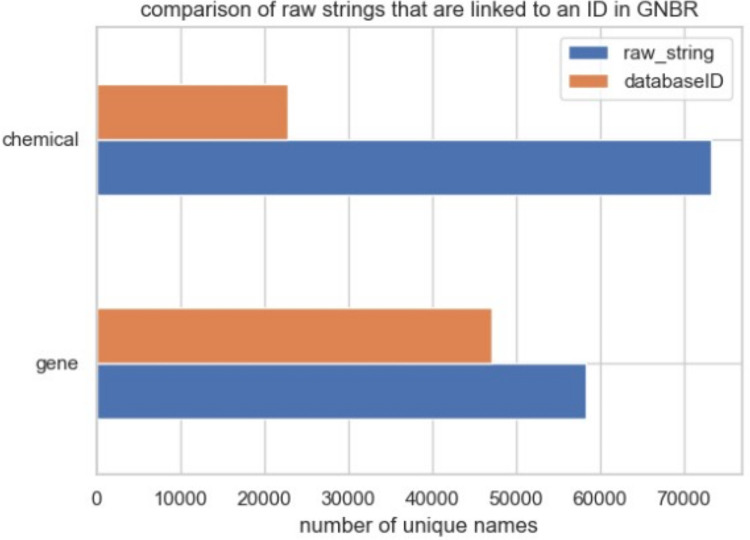
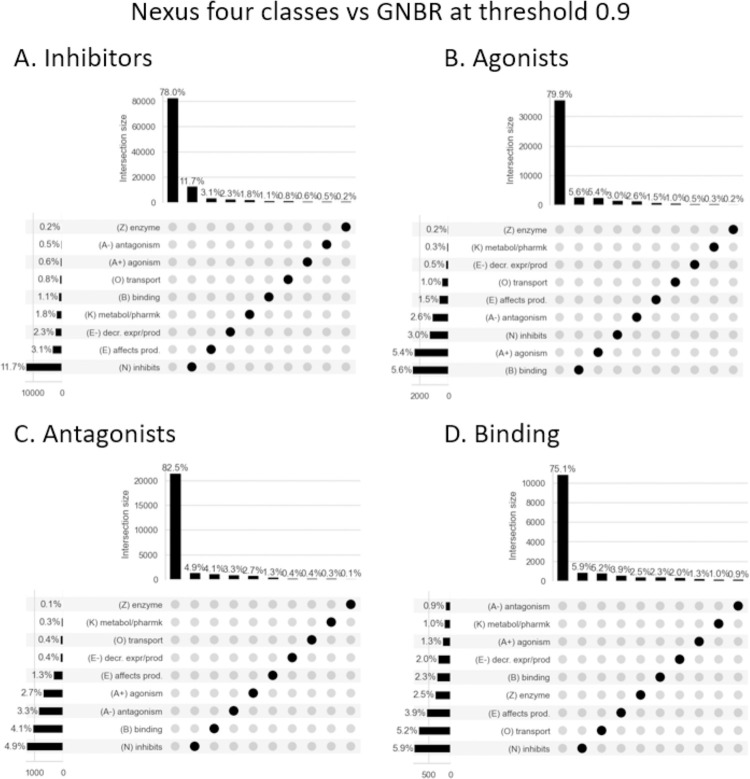
One area of active research is the use of natural language processing (NLP) to mine biomedical texts for sets of triples (subject-predicate-object) for knowledge graph (KG) construction. While statistical methods to mine co-occurrences of entities within sentences are relatively robust, accurate relationship extraction is more challenging. Herein, we evaluate the Global Network of Biomedical Relationships (GNBR), a dataset that uses distributional semantics to model relationships between biomedical entities. The focus of our paper is an evaluation of a subset of the GNBR data; the relationships between chemicals and genes/proteins. We use Evotec's structured 'Nexus' database of >2.76M chemical-protein interactions as a ground truth to compare with GNBRs relationships and find a micro-averaged precision-recall area under the curve (AUC) of 0.50 and a micro-averaged receiver operating characteristic (ROC) curve AUC of 0.71 across the relationship classes 'inhibits', 'binding', 'agonism' and 'antagonism', when a comparison is made on a sentence-by-sentence basis. We conclude that, even though these micro-average scores are modest, using a high threshold on certain relationship classes like 'inhibits' could yield high fidelity triples that are not reported in structured datasets. We discuss how different methods of processing GNBR data, and the factuality of triples could affect the accuracy of NLP data incorporated into knowledge graphs. We provide a GNBR-Nexus(ChEMBL-subset) merged datafile that contains over 20,000 sentences where a protein/gene-chemical co-occur and includes both the GNBR relationship scores as well as the ChEMBL (manually curated) relationships (e.g., 'agonist', 'inhibitor') -this can be accessed at https://doi.org/10.5281/zenodo.8136752. We envisage this being used to aid curation efforts by the drug discovery community.
一个活跃的研究领域是使用自然语言处理 (NLP) 从生物医学文本中挖掘用于知识图谱 (KG) 构建的三元组集(主语-谓语-宾语)。虽然用于挖掘句子中实体共现的统计方法相对稳健,但准确的关系提取更具挑战性。在此,我们评估了全球生物医学关系网络 (GNBR),这是一个使用分布式语义模型来模拟生物医学实体之间关系的数据集。我们论文的重点是评估 GNBR 数据的一个子集;化学物质和基因/蛋白质之间的关系。我们使用 Evotec 的结构化'Nexus'数据库 (>2760 万种化学-蛋白质相互作用) 作为基准来与 GNBR 关系进行比较,并发现“抑制”、“结合”、“激动剂”和“拮抗剂”这四个关系类别的微平均精度-召回曲线下面积 (AUC) 为 0.50,微平均接收器操作特征 (ROC) 曲线 AUC 为 0.71,当在句子对句子的基础上进行比较时。我们得出结论,即使这些微平均分数适中,在某些关系类(如“抑制”)上使用较高的阈值也可以生成未在结构化数据集中报告的高保真三元组。我们讨论了处理 GNBR 数据的不同方法以及三元组的真实性如何影响纳入知识图谱的 NLP 数据的准确性。我们提供了一个 GNBR-Nexus(ChEMBL 子集)合并数据集,其中包含超过 20000 个句子,其中蛋白质/基因-化学物质同时出现,并包含 GNBR 关系分数以及 ChEMBL(人工 curated)关系(例如“激动剂”、“抑制剂”)-可在 https://doi.org/10.5281/zenodo.8136752 访问。我们设想这将有助于药物发现社区的策展工作。