Spjuth Ola, Krestyaninova Maria, Hastings Janna, Shen Huei-Yi, Heikkinen Jani, Waldenberger Melanie, Langhammer Arnulf, Ladenvall Claes, Esko Tõnu, Persson Mats-Åke, Heggland Jon, Dietrich Joern, Ose Sandra, Gieger Christian, Ried Janina S, Peters Annette, Fortier Isabel, de Geus Eco J C, Klovins Janis, Zaharenko Linda, Willemsen Gonneke, Hottenga Jouke-Jan, Litton Jan-Eric, Karvanen Juha, Boomsma Dorret I, Groop Leif, Rung Johan, Palmgren Juni, Pedersen Nancy L, McCarthy Mark I, van Duijn Cornelia M, Hveem Kristian, Metspalu Andres, Ripatti Samuli, Prokopenko Inga, Harris Jennifer R
Department of Medical Epidemiology and Biostatistics, Swedish e-Science Research Centre, Karolinska Institutet, Stockholm, Sweden.
Department of Pharmaceutical Biosciences and Science for Life Laboratory, Uppsala University, Uppsala, Sweden.
Eur J Hum Genet. 2016 Apr;24(4):521-8. doi: 10.1038/ejhg.2015.165. Epub 2015 Aug 26.
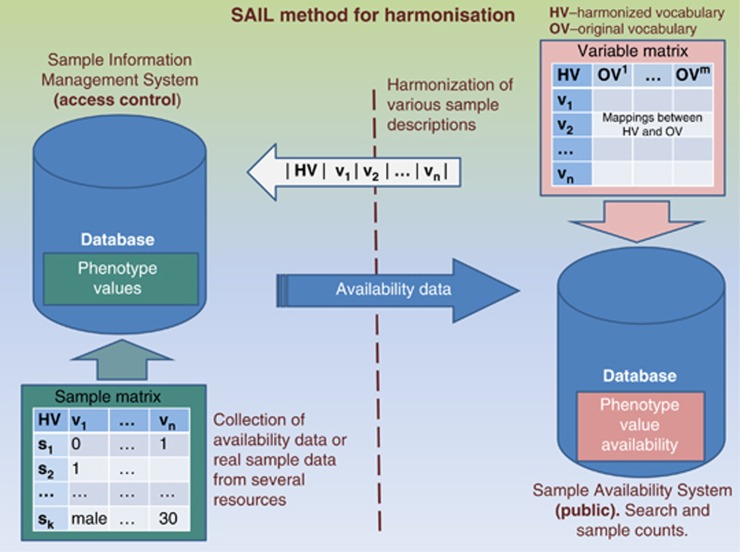
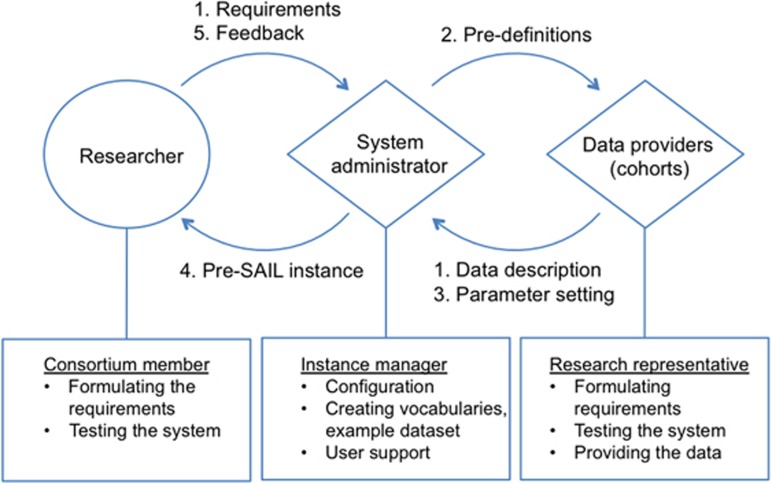
A wealth of biospecimen samples are stored in modern globally distributed biobanks. Biomedical researchers worldwide need to be able to combine the available resources to improve the power of large-scale studies. A prerequisite for this effort is to be able to search and access phenotypic, clinical and other information about samples that are currently stored at biobanks in an integrated manner. However, privacy issues together with heterogeneous information systems and the lack of agreed-upon vocabularies have made specimen searching across multiple biobanks extremely challenging. We describe three case studies where we have linked samples and sample descriptions in order to facilitate global searching of available samples for research. The use cases include the ENGAGE (European Network for Genetic and Genomic Epidemiology) consortium comprising at least 39 cohorts, the SUMMIT (surrogate markers for micro- and macro-vascular hard endpoints for innovative diabetes tools) consortium and a pilot for data integration between a Swedish clinical health registry and a biobank. We used the Sample avAILability (SAIL) method for data linking: first, created harmonised variables and then annotated and made searchable information on the number of specimens available in individual biobanks for various phenotypic categories. By operating on this categorised availability data we sidestep many obstacles related to privacy that arise when handling real values and show that harmonised and annotated records about data availability across disparate biomedical archives provide a key methodological advance in pre-analysis exchange of information between biobanks, that is, during the project planning phase.
现代全球分布的生物样本库中存储着大量的生物样本。世界各地的生物医学研究人员需要能够整合现有资源,以提高大规模研究的效能。这项工作的一个前提是能够以综合方式搜索和获取目前存储在生物样本库中的样本的表型、临床和其他信息。然而,隐私问题、异构信息系统以及缺乏统一认可的词汇,使得跨多个生物样本库进行样本搜索极具挑战性。我们描述了三个案例研究,在这些研究中我们将样本与样本描述相链接,以便于对可供研究的现有样本进行全球搜索。这些用例包括由至少39个队列组成的ENGAGE(欧洲遗传与基因组流行病学网络)联盟、SUMMIT(创新糖尿病工具的微血管和大血管硬终点替代标志物)联盟以及瑞典临床健康登记处与一个生物样本库之间的数据整合试点。我们使用样本可用性(SAIL)方法进行数据链接:首先,创建统一的变量,然后对各个生物样本库中各种表型类别的可用样本数量进行注释并使其可搜索。通过处理这种分类的可用性数据,我们避开了在处理实际值时出现的许多与隐私相关的障碍,并表明跨不同生物医学档案的数据可用性的统一和注释记录为生物样本库之间信息的分析前交换,即在项目规划阶段,提供了关键的方法学进展。