Khalifa Abdulrahman, Meystre Stéphane
Department of Biomedical Informatics, University of Utah, Salt Lake City, UT, United States.
J Biomed Inform. 2015 Dec;58 Suppl(Suppl):S128-S132. doi: 10.1016/j.jbi.2015.08.002. Epub 2015 Aug 28.
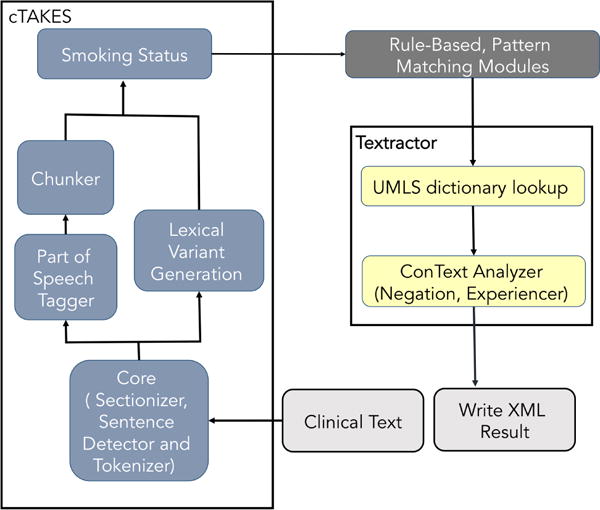
The 2014 i2b2 natural language processing shared task focused on identifying cardiovascular risk factors such as high blood pressure, high cholesterol levels, obesity and smoking status among other factors found in health records of diabetic patients. In addition, the task involved detecting medications, and time information associated with the extracted data. This paper presents the development and evaluation of a natural language processing (NLP) application conceived for this i2b2 shared task. For increased efficiency, the application main components were adapted from two existing NLP tools implemented in the Apache UIMA framework: Textractor (for dictionary-based lookup) and cTAKES (for preprocessing and smoking status detection). The application achieved a final (micro-averaged) F1-measure of 87.5% on the final evaluation test set. Our attempt was mostly based on existing tools adapted with minimal changes and allowed for satisfying performance with limited development efforts.
2014年i2b2自然语言处理共享任务聚焦于识别心血管危险因素,如糖尿病患者健康记录中发现的高血压、高胆固醇水平、肥胖及吸烟状况等其他因素。此外,该任务还涉及检测药物以及与提取数据相关的时间信息。本文介绍了为该i2b2共享任务构思的自然语言处理(NLP)应用程序的开发与评估。为提高效率,应用程序的主要组件改编自Apache UIMA框架中实现的两个现有NLP工具:Textractor(用于基于字典的查找)和cTAKES(用于预处理和吸烟状况检测)。该应用程序在最终评估测试集上的最终(微平均)F1值为87.5%。我们的尝试主要基于对现有工具进行最少更改的改编,并通过有限的开发工作实现了令人满意的性能。