Obulkasim Askar, Fornerod Maarten, Zwaan Michel C, Reinhardt Dirk, van den Heuvel-Eibrink Marry M
Department of Pediatric Oncology/Hematology, Erasmus-MC Sophia Childrens Hospital, Rotterdam, The Netherlands.
Dutch Children's Oncology Group, Erasmus-MC Sophia Children's Hospital, Rotterdam, The Netherlands.
BMC Bioinformatics. 2015 Sep 23;16:305. doi: 10.1186/s12859-015-0737-3.
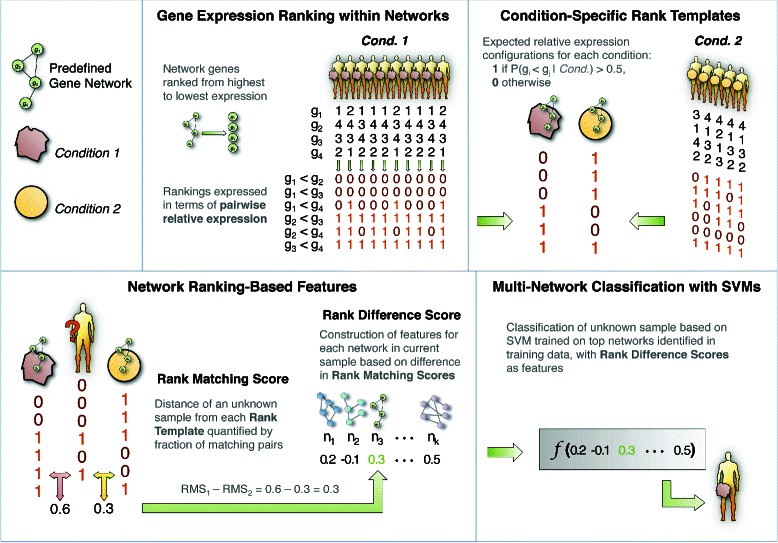
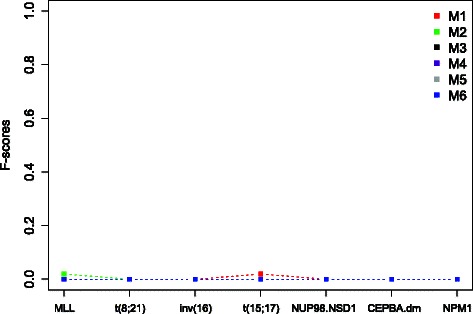
One of the most important application spectrums of transcriptomic data is cancer phenotype classification. Many characteristics of transcriptomic data, such as redundant features and technical artifacts, make over-fitting commonplace. Promising classification results often fail to generalize across datasets with different sources, platforms, or preprocessing. Recently a novel differential network rank conservation (DIRAC) algorithm to characterize cancer phenotypes using transcriptomic data. DIRAC is a member of a family of algorithms that have shown useful for disease classification based on the relative expression of genes. Combining the robustness of this family's simple decision rules with known biological relationships, this systems approach identifies interpretable, yet highly discriminate networks. While DIRAC has been briefly employed for several classification problems in the original paper, the potentials of DIRAC in cancer phenotype classification, and especially robustness against artifacts in transcriptomic data have not been fully characterized yet.
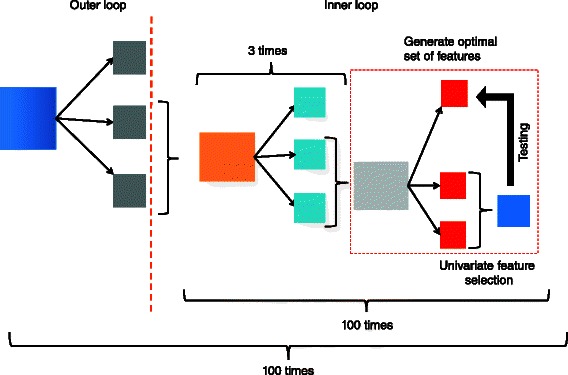
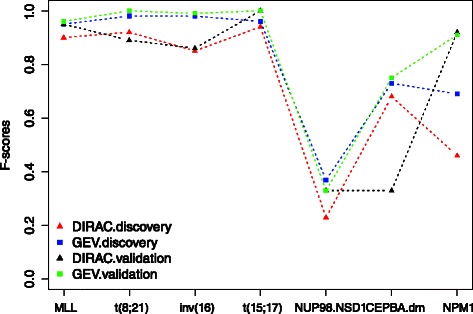
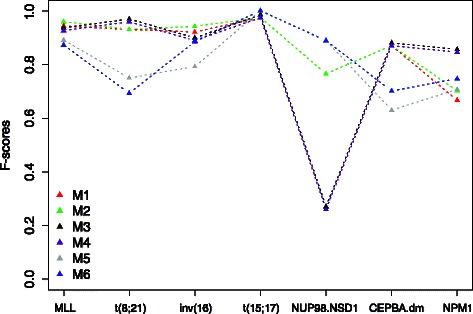
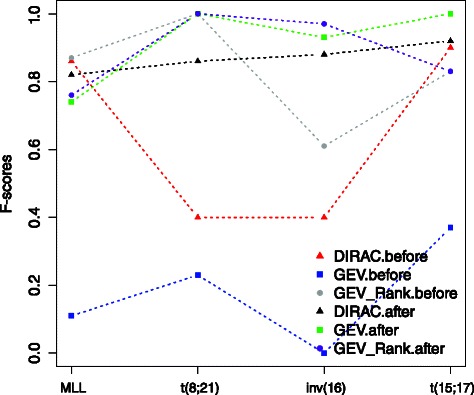
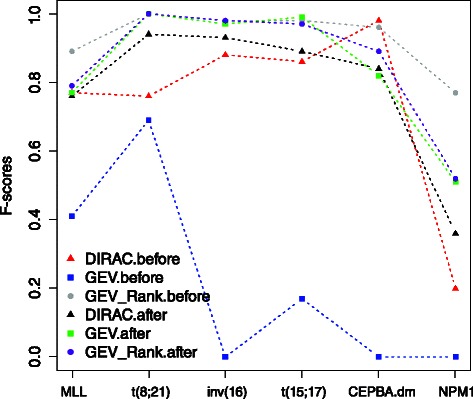
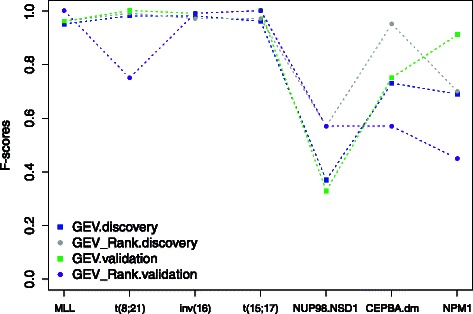
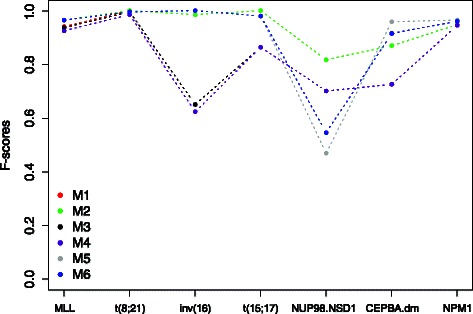
In this study we thoroughly investigate the potentials of DIRAC by applying it to multiple datasets, and examine the variations in classification performances when datasets are (i) treated and untreated for batch effect; (ii) preprocessed with different techniques. We also propose the first DIRAC-based classifier to integrate multiple networks. We show that the DIRAC-based classifier is very robust in the examined scenarios. To our surprise, the trained DIRAC-based classifier even translated well to a dataset with different biological characteristics in the presence of substantial batch effects that, as shown here, plagued the standard expression value based classifier. In addition, the DIRAC-based classifier, because of the integrated biological information, also suggests pathways to target in specific subtypes, which may enhance the establishment of personalized therapy in diseases such as pediatric AML. In order to better comprehend the prediction power of the DIRAC-based classifier in general, we also performed classifications using publicly available datasets from breast and lung cancer. Furthermore, multiple well-known classification algorithms were utilized to create an ideal test bed for comparing the DIRAC-based classifier with the standard gene expression value based classifier. We observed that the DIRAC-based classifier greatly outperforms its rival.
Based on our experiments with multiple datasets, we propose that DIRAC is a promising solution to the lack of generalizability in classification efforts that uses transcriptomic data. We believe that superior performances presented in this study may motivate other to initiate a new aline of research to explore the untapped power of DIRAC in a broad range of cancer types.
转录组数据最重要的应用领域之一是癌症表型分类。转录组数据的许多特征,如冗余特征和技术假象,使得过拟合现象很常见。有前景的分类结果往往无法在不同来源、平台或预处理的数据集之间进行泛化。最近,一种新的基于差异网络秩守恒(DIRAC)的算法被用于利用转录组数据表征癌症表型。DIRAC是一类算法中的一员,这类算法已被证明在基于基因相对表达的疾病分类中很有用。该系统方法将这类算法简单决策规则的稳健性与已知的生物学关系相结合,识别出可解释但具有高度区分性的网络。虽然在原始论文中DIRAC已被简要应用于几个分类问题,但DIRAC在癌症表型分类中的潜力,尤其是对转录组数据中假象的稳健性,尚未得到充分表征。
在本研究中,我们通过将DIRAC应用于多个数据集,全面研究了其潜力,并考察了在以下情况下分类性能的变化:(i)对数据集进行批效应处理和未处理;(ii)用不同技术进行预处理。我们还提出了第一个基于DIRAC的集成多个网络的分类器。我们表明,基于DIRAC的分类器在考察的场景中非常稳健。令我们惊讶的是,经过训练的基于DIRAC的分类器甚至能很好地迁移到具有不同生物学特征的数据集,即使存在严重的批效应,而正如这里所示,批效应困扰着基于标准表达值的分类器。此外,基于DIRAC的分类器由于整合了生物学信息,还能指出特定亚型中可靶向的通路,这可能有助于在小儿急性髓系白血病等疾病中建立个性化治疗方案。为了更全面地理解基于DIRAC的分类器的预测能力,我们还使用乳腺癌和肺癌的公开可用数据集进行了分类。此外,利用多种知名分类算法创建了一个理想的测试平台,用于将基于DIRAC的分类器与基于标准基因表达值的分类器进行比较。我们观察到基于DIRAC的分类器大大优于其对手。
基于我们对多个数据集的实验,我们提出DIRAC是解决使用转录组数据进行分类时缺乏泛化性问题的一个有前景的解决方案。我们相信本研究中展示的卓越性能可能会促使其他人开展新的研究方向,以探索DIRAC在广泛癌症类型中尚未开发的潜力。