König Caroline, Cárdenas Martha I, Giraldo Jesús, Alquézar René, Vellido Alfredo
Dept. of Computer Science, Univ. Politècnica de Catalunya, C. Jordi Girona, 1-3, Barcelona, 08034, Spain.
Institut de Neurociències, Unitat de Bioestadística, Univ. Autònoma de Barcelona, Cerdanyola del Vallès, Barcelona, 08193, Spain.
BMC Bioinformatics. 2015 Sep 29;16:314. doi: 10.1186/s12859-015-0731-9.
The characterization of proteins in families and subfamilies, at different levels, entails the definition and use of class labels. When the adscription of a protein to a family is uncertain, or even wrong, this becomes an instance of what has come to be known as a label noise problem. Label noise has a potentially negative effect on any quantitative analysis of proteins that depends on label information. This study investigates class C of G protein-coupled receptors, which are cell membrane proteins of relevance both to biology in general and pharmacology in particular. Their supervised classification into different known subtypes, based on primary sequence data, is hampered by label noise. The latter may stem from a combination of expert knowledge limitations and the lack of a clear correspondence between labels that mostly reflect GPCR functionality and the different representations of the protein primary sequences.
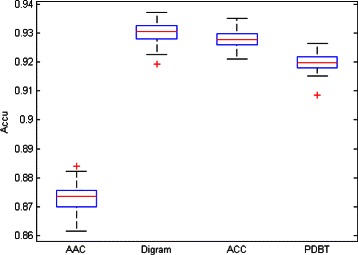
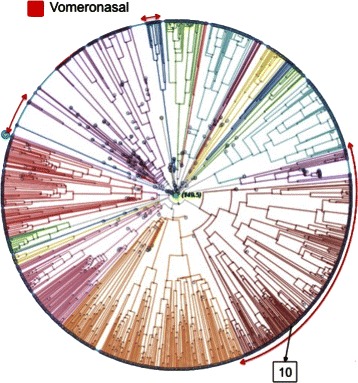
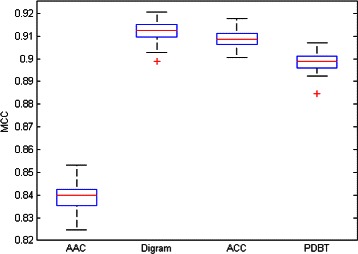
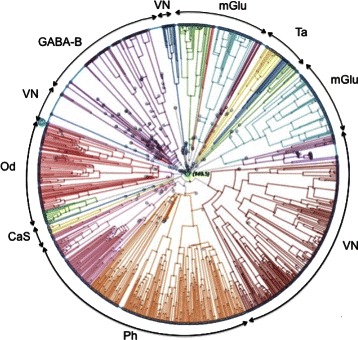
In this study, we describe a systematic approach, using Support Vector Machine classifiers, to the analysis of G protein-coupled receptor misclassifications. As a proof of concept, this approach is used to assist the discovery of labeling quality problems in a curated, publicly accessible database of this type of proteins. We also investigate the extent to which physico-chemical transformations of the protein sequences reflect G protein-coupled receptor subtype labeling. The candidate mislabeled cases detected with this approach are externally validated with phylogenetic trees and against further trusted sources such as the National Center for Biotechnology Information, Universal Protein Resource, European Bioinformatics Institute and Ensembl Genome Browser information repositories.
In quantitative classification problems, class labels are often by default assumed to be correct. Label noise, though, is bound to be a pervasive problem in bioinformatics, where labels may be obtained indirectly through complex, many-step similarity modelling processes. In the case of G protein-coupled receptors, methods capable of singling out and characterizing those sequences with consistent misclassification behaviour are required to minimize this problem. A systematic, Support Vector Machine-based method has been proposed in this study for such purpose. The proposed method enables a filtering approach to the label noise problem and might become a support tool for database curators in proteomics.
在不同层面上对蛋白质家族和亚家族中的蛋白质进行特征描述,需要定义和使用类别标签。当蛋白质归属于某个家族存在不确定性甚至错误时,这就成为了所谓的标签噪声问题的一个实例。标签噪声对任何依赖标签信息的蛋白质定量分析都可能产生负面影响。本研究调查了G蛋白偶联受体的C类,这类受体是对一般生物学尤其是药理学都具有重要意义的细胞膜蛋白。基于一级序列数据将它们监督分类为不同的已知亚型时,会受到标签噪声的阻碍。标签噪声可能源于专家知识的局限性,以及主要反映GPCR功能的标签与蛋白质一级序列的不同表示形式之间缺乏明确对应关系。
在本研究中,我们描述了一种使用支持向量机分类器来分析G蛋白偶联受体错误分类的系统方法。作为概念验证,该方法用于协助在一个经过整理的、可公开访问的此类蛋白质数据库中发现标签质量问题。我们还研究了蛋白质序列的物理化学转换在多大程度上反映G蛋白偶联受体亚型标签。用这种方法检测到的候选错误标记案例通过系统发育树并对照诸如美国国立生物技术信息中心、通用蛋白质资源库、欧洲生物信息学研究所和Ensembl基因组浏览器信息库等更多可靠来源进行外部验证。
在定量分类问题中,类别标签通常默认被认为是正确的。然而,标签噪声在生物信息学中必然是一个普遍存在的问题,在生物信息学中,标签可能通过复杂的多步相似性建模过程间接获得。就G蛋白偶联受体而言,需要能够挑选出并表征那些具有一致错误分类行为的序列的方法,以尽量减少这个问题。本研究为此目的提出了一种基于支持向量机的系统方法。所提出的方法能够对标签噪声问题采用过滤方法,并且可能成为蛋白质组学中数据库管理员的一个支持工具。