Pechenick Eitan Adam, Danforth Christopher M, Dodds Peter Sheridan
Department of Mathematics and Statistics, University of Vermont, Burlington, Vermont, United States of America; Center for Complex Systems, University of Vermont, Burlington, Vermont, United States of America; Computational Story Lab, University of Vermont, Burlington, Vermont, United States of America; Vermont Advanced Computing Core, University of Vermont, Burlington, Vermont, United States of America.
PLoS One. 2015 Oct 7;10(10):e0137041. doi: 10.1371/journal.pone.0137041. eCollection 2015.
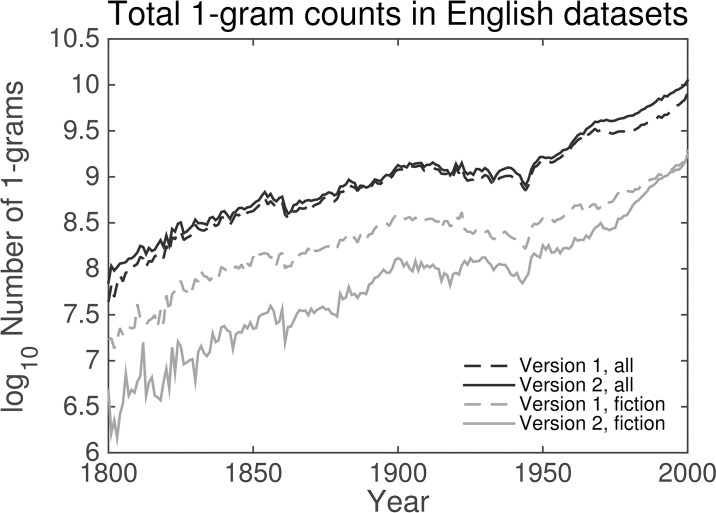
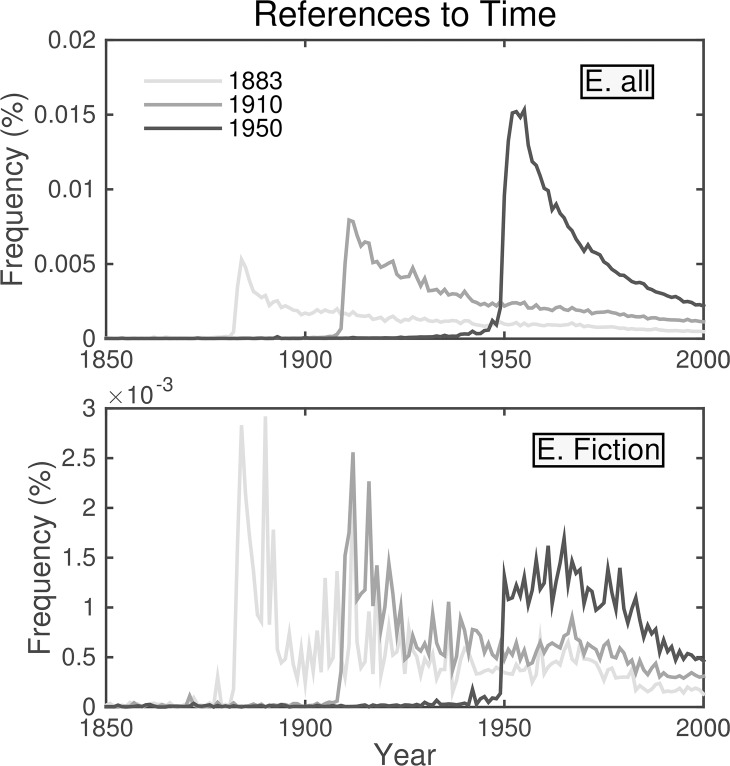
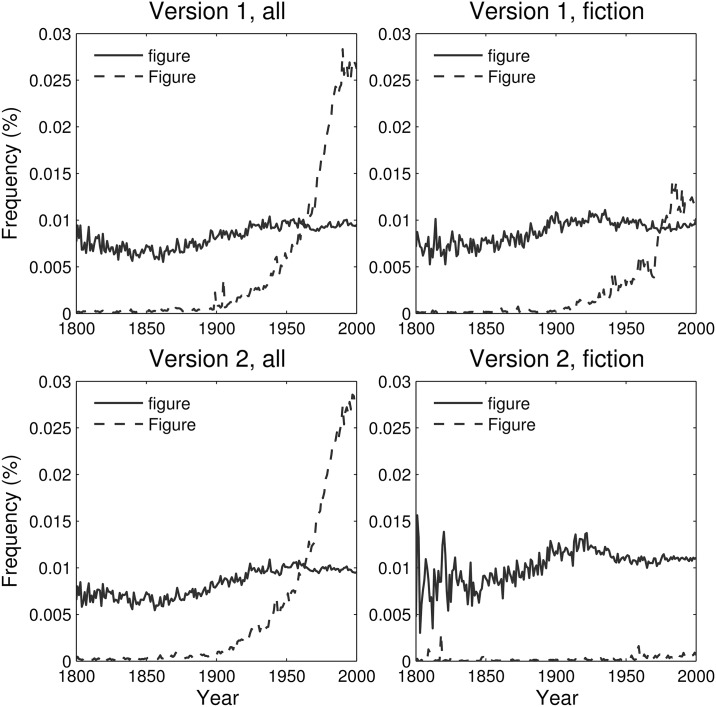
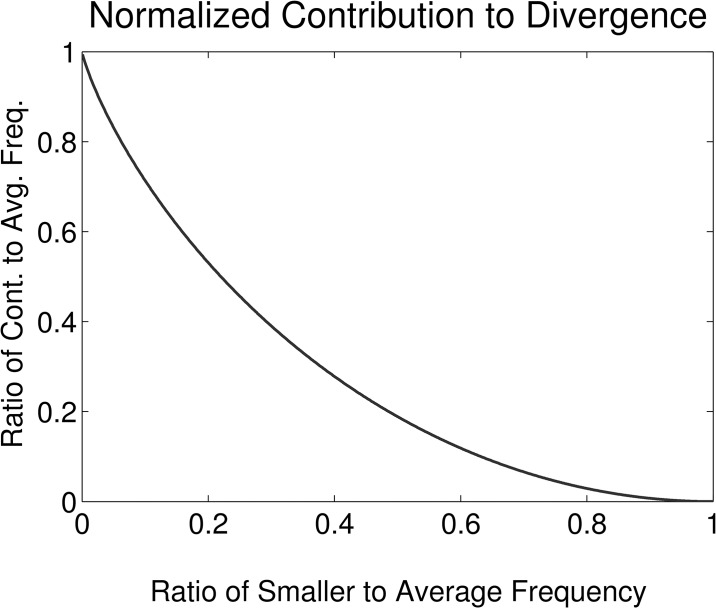
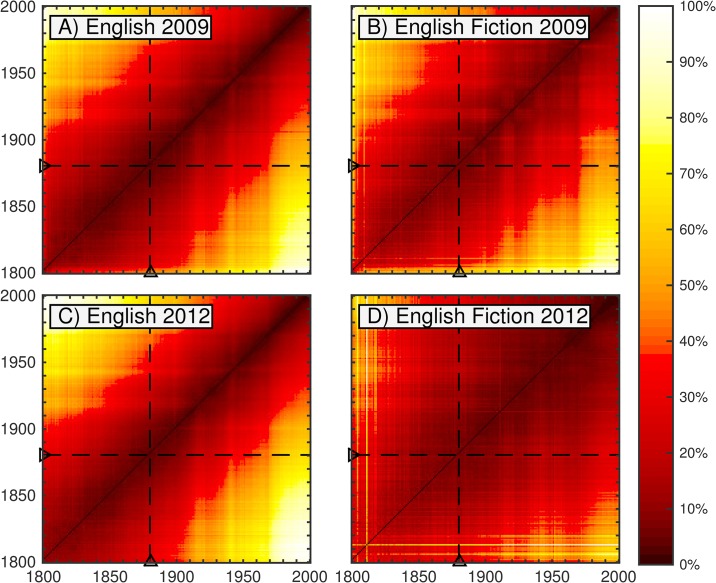
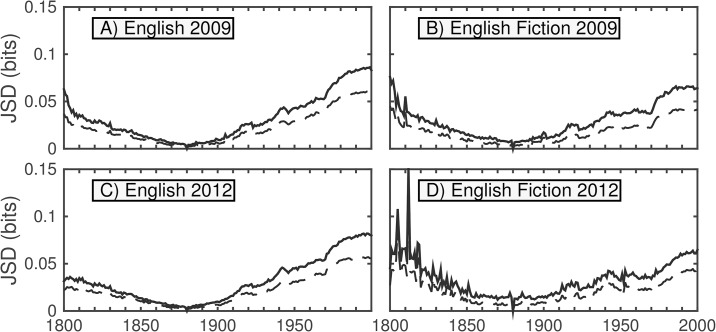
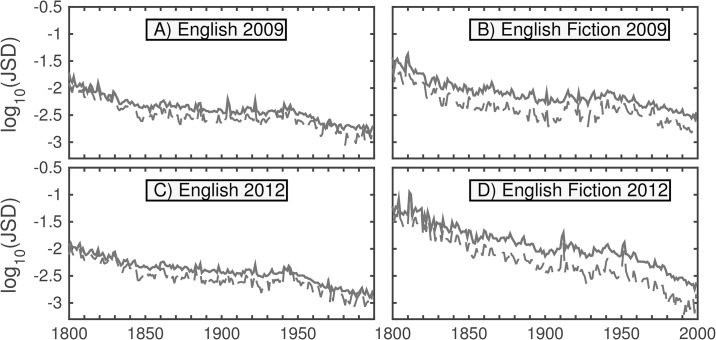
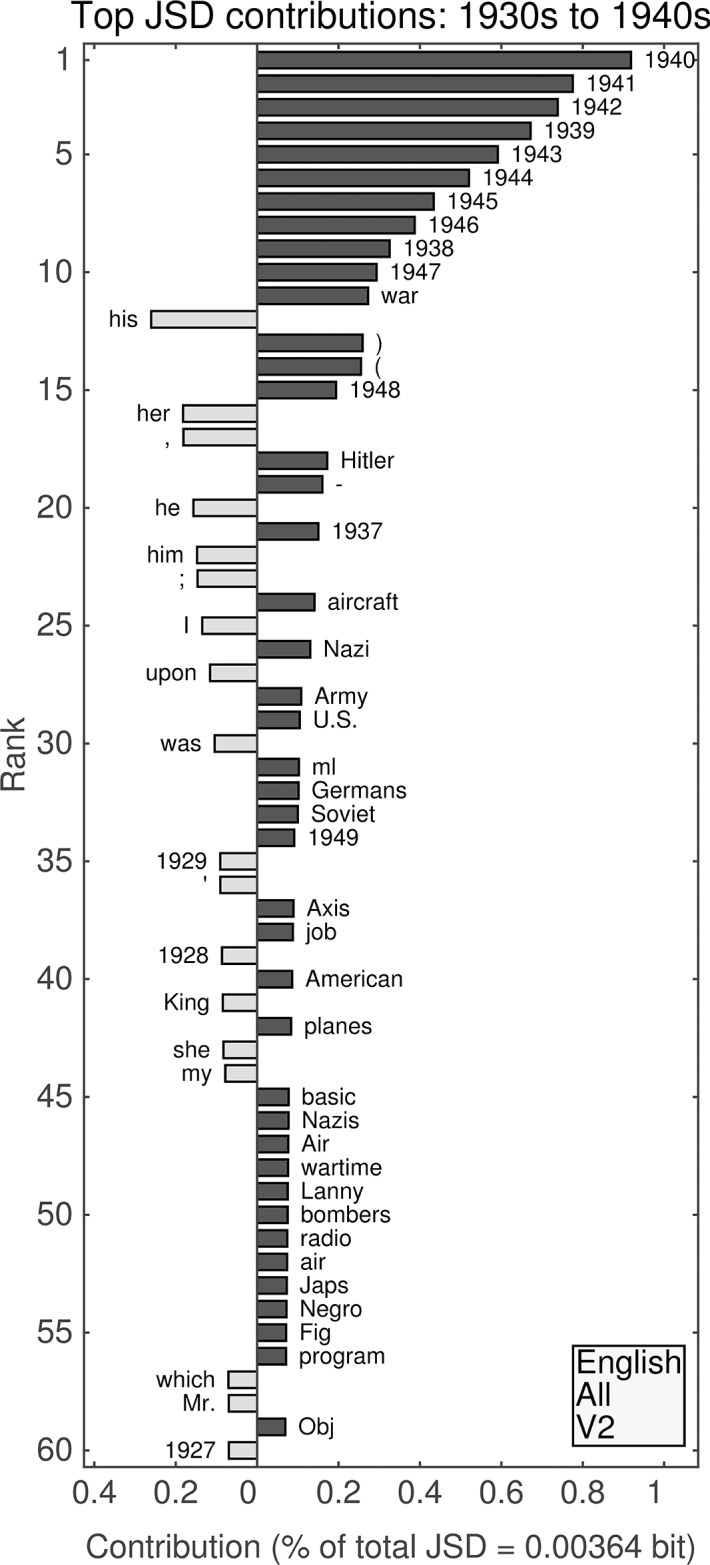
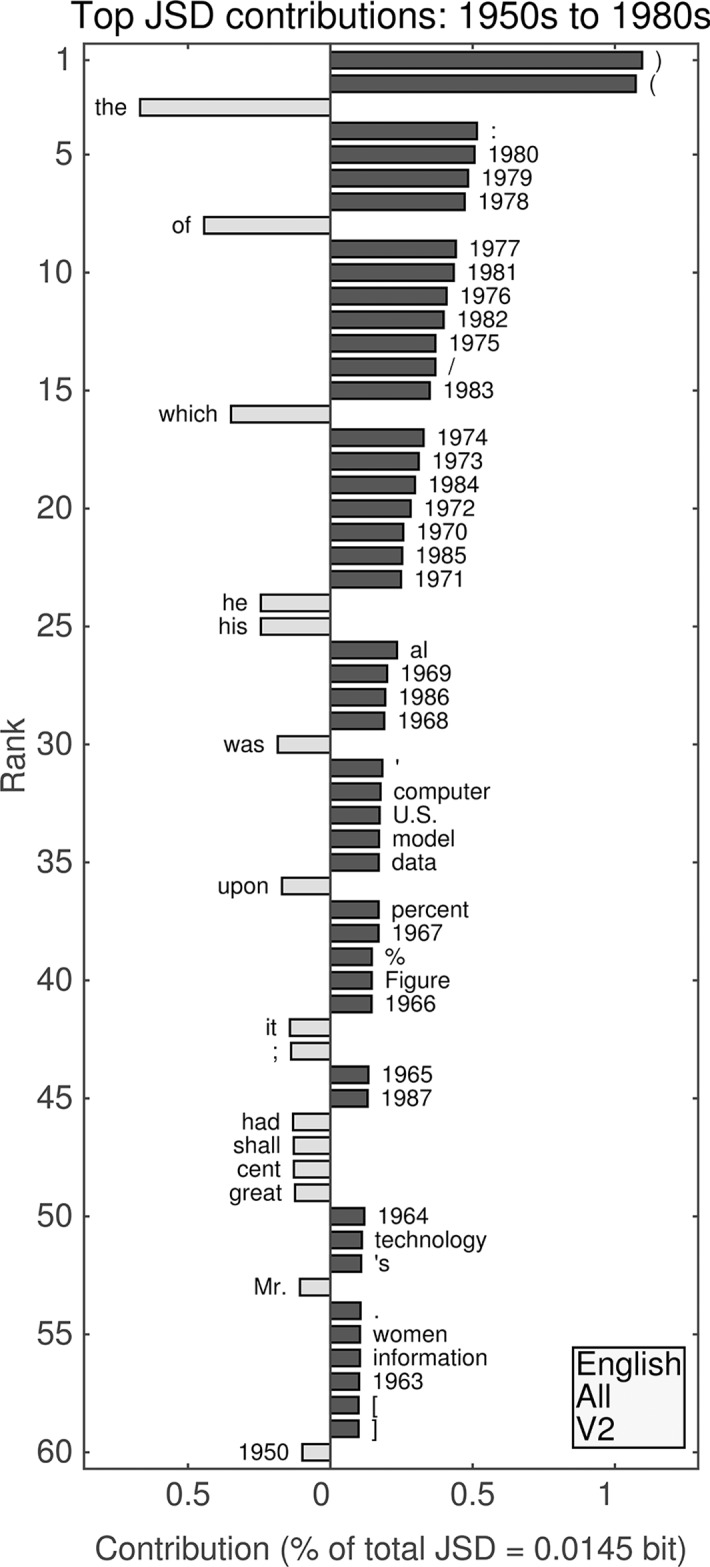
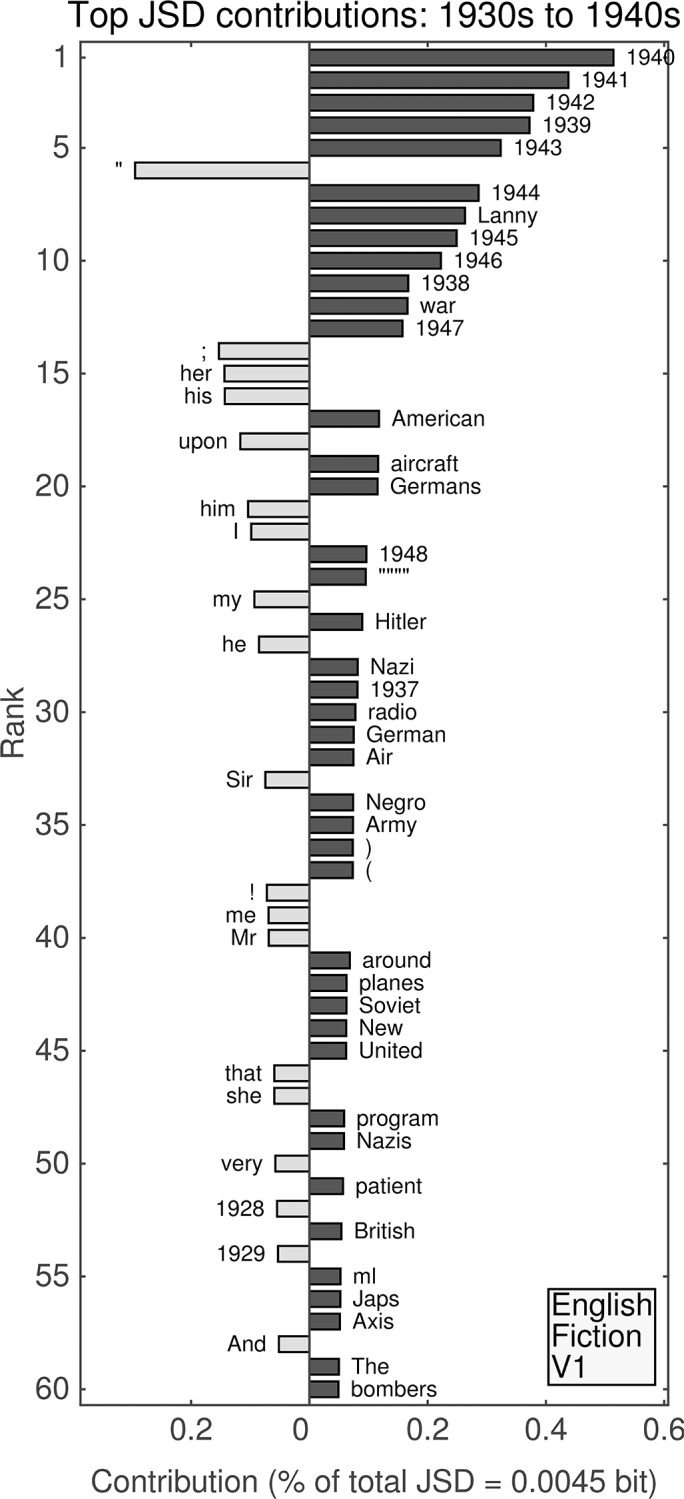
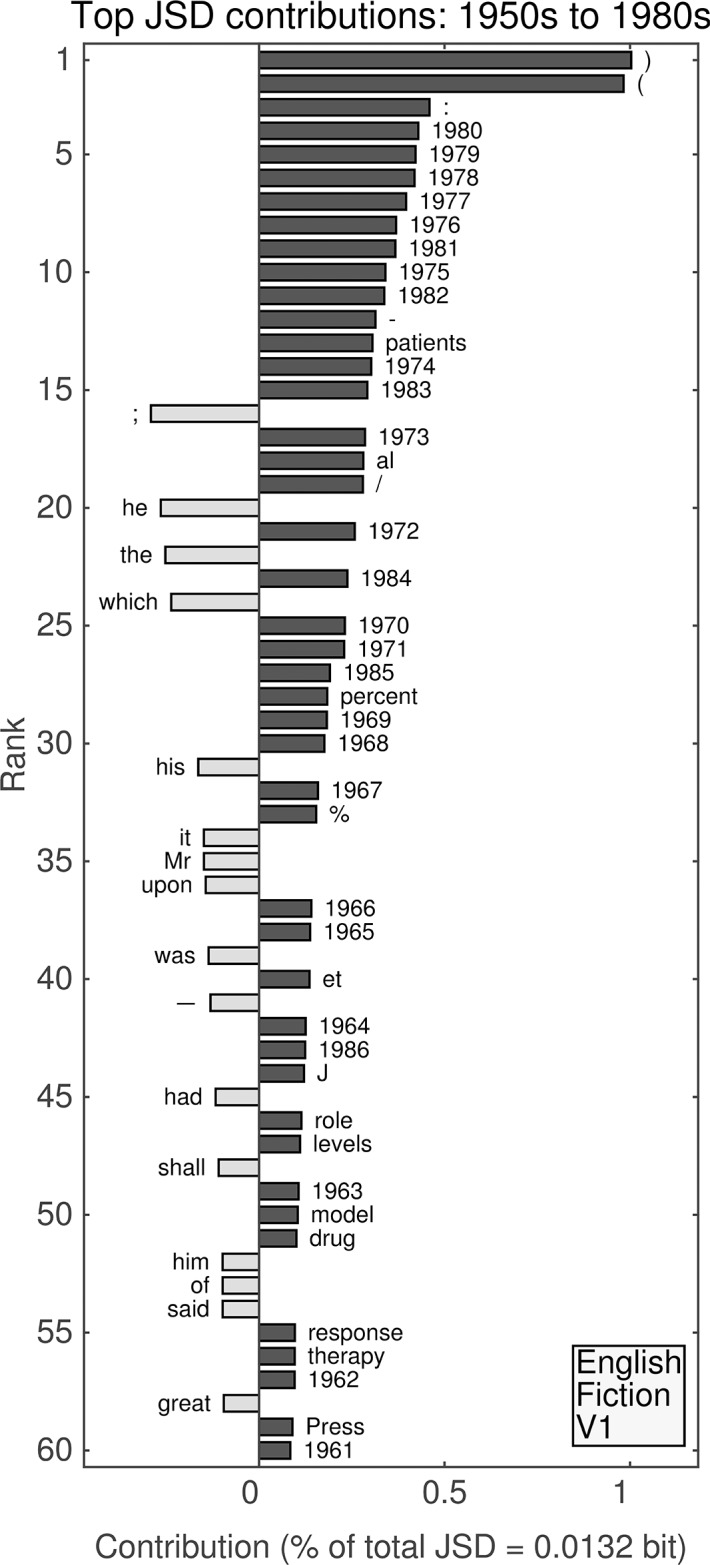
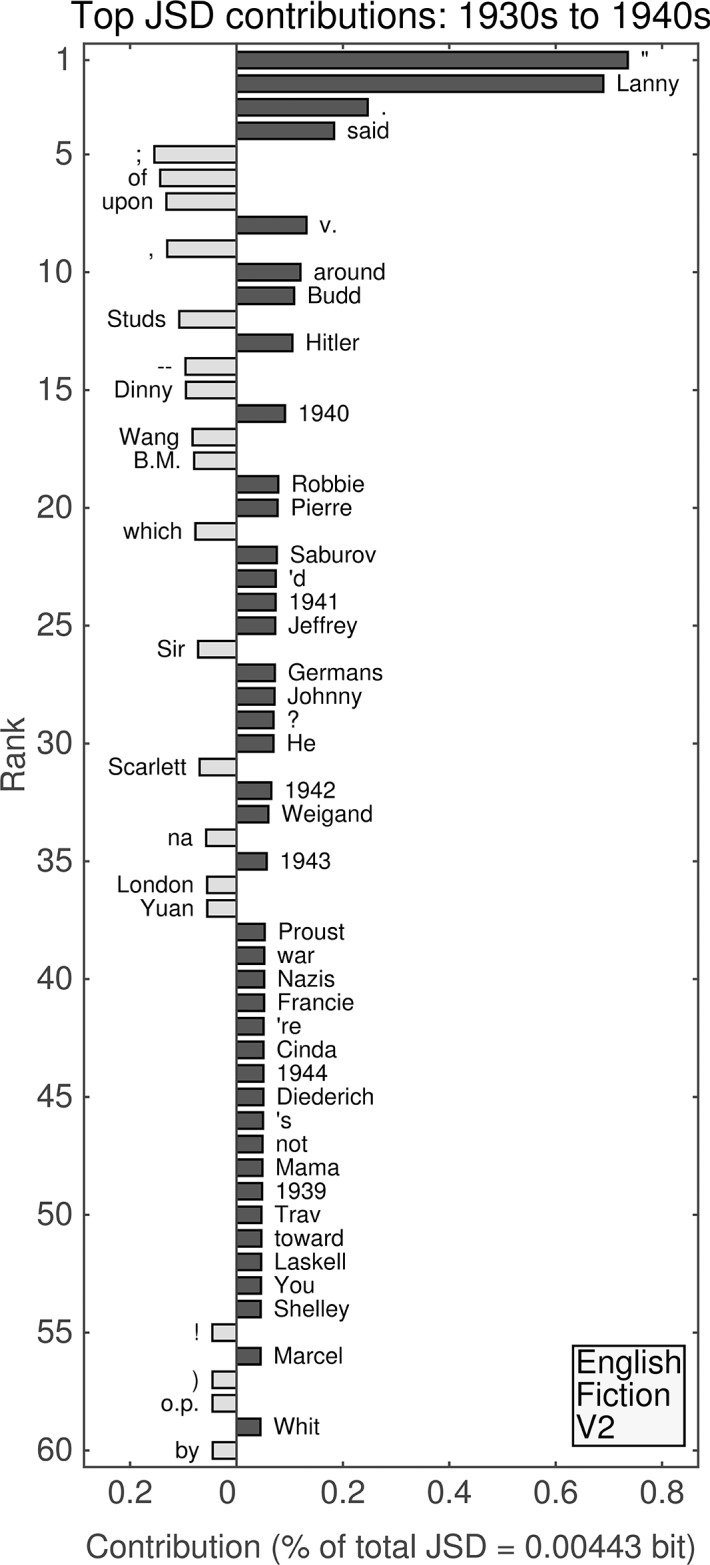
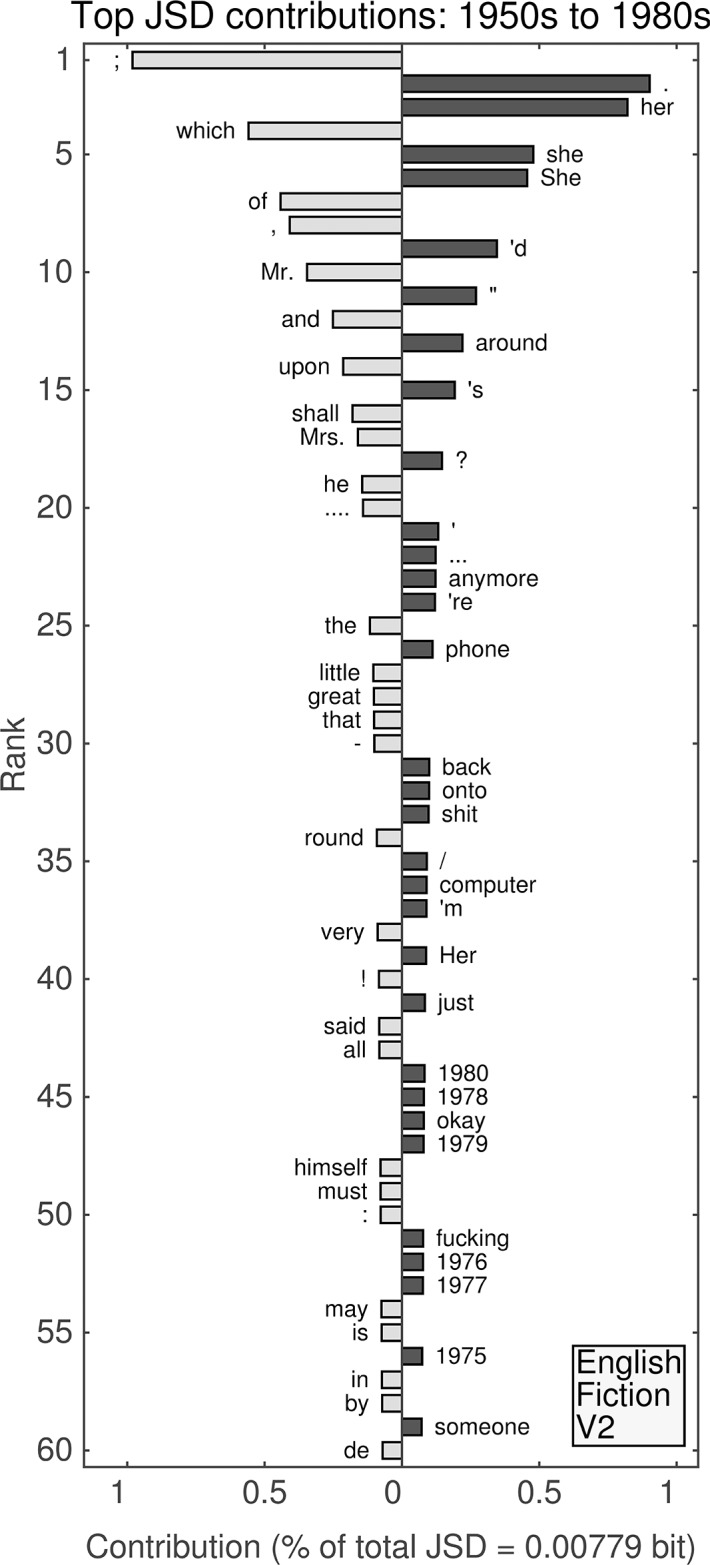
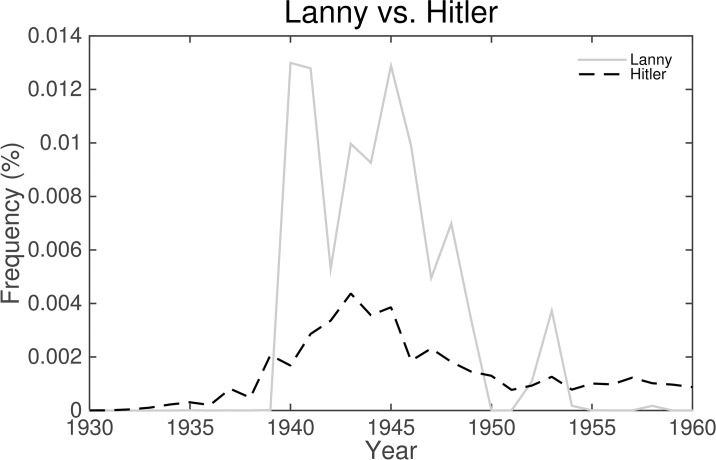
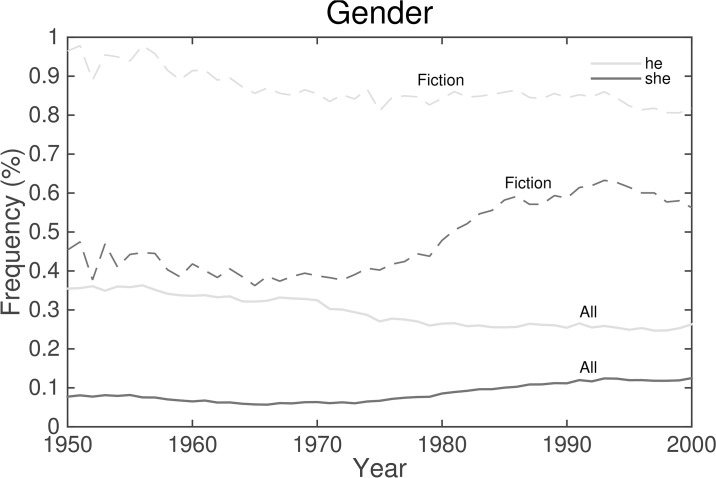
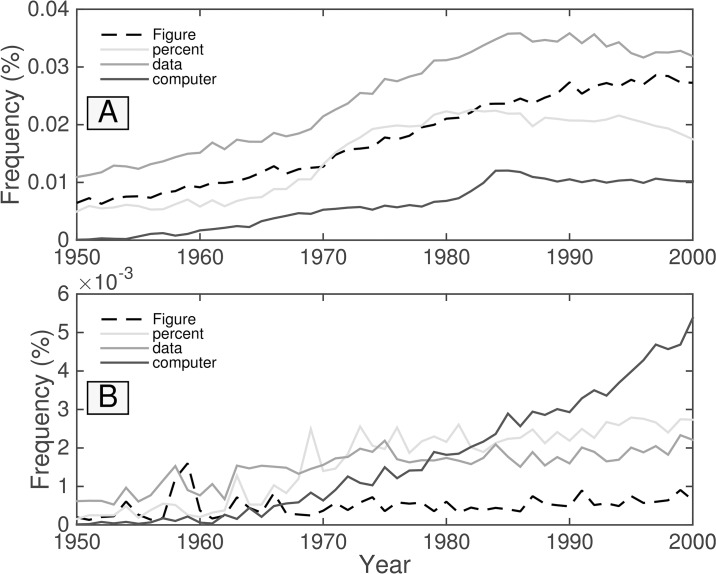
It is tempting to treat frequency trends from the Google Books data sets as indicators of the "true" popularity of various words and phrases. Doing so allows us to draw quantitatively strong conclusions about the evolution of cultural perception of a given topic, such as time or gender. However, the Google Books corpus suffers from a number of limitations which make it an obscure mask of cultural popularity. A primary issue is that the corpus is in effect a library, containing one of each book. A single, prolific author is thereby able to noticeably insert new phrases into the Google Books lexicon, whether the author is widely read or not. With this understood, the Google Books corpus remains an important data set to be considered more lexicon-like than text-like. Here, we show that a distinct problematic feature arises from the inclusion of scientific texts, which have become an increasingly substantive portion of the corpus throughout the 1900 s. The result is a surge of phrases typical to academic articles but less common in general, such as references to time in the form of citations. We use information theoretic methods to highlight these dynamics by examining and comparing major contributions via a divergence measure of English data sets between decades in the period 1800-2000. We find that only the English Fiction data set from the second version of the corpus is not heavily affected by professional texts. Overall, our findings call into question the vast majority of existing claims drawn from the Google Books corpus, and point to the need to fully characterize the dynamics of the corpus before using these data sets to draw broad conclusions about cultural and linguistic evolution.
人们很容易将谷歌图书数据集中的词频趋势视为各种词汇和短语“真正”流行程度的指标。这样做能让我们就特定主题(如时间或性别)的文化认知演变得出在数量上颇具说服力的结论。然而,谷歌图书语料库存在一些局限性,这使其成为文化流行程度的一个模糊表象。一个主要问题是,该语料库实际上是一个图书馆,每本书只包含一本。因此,一位多产的作者就能显著地将新短语插入谷歌图书词汇表中,无论这位作者是否广为人知。明白了这一点后,谷歌图书语料库仍是一个重要的数据集,应被视为更像词汇表而非文本。在此,我们表明,科学文本的纳入产生了一个明显的问题特征,在整个20世纪,科学文本在语料库中所占比例越来越大。结果是学术文章中常见但在一般情况下较少出现的短语大量增加,比如以引用形式提及时间的表述。我们运用信息论方法,通过考察和比较1800 - 2000年期间几十年间英语数据集的差异测度来突出这些动态变化。我们发现,只有语料库第二版中的英语小说数据集受专业文本的影响不大。总体而言,我们的研究结果对从谷歌图书语料库得出的绝大多数现有论断提出了质疑,并指出在使用这些数据集就文化和语言演变得出广泛结论之前,有必要全面描述该语料库的动态变化。