Corey Kathleen E, Kartoun Uri, Zheng Hui, Shaw Stanley Y
Gastrointestinal Unit, Massachusetts General Hospital, 55 Fruit Street, Blake 4, Boston, MA, 02114, USA.
Harvard Medical School, Boston, MA, USA.
Dig Dis Sci. 2016 Mar;61(3):913-9. doi: 10.1007/s10620-015-3952-x. Epub 2015 Nov 4.
Nonalcoholic fatty liver disease (NAFLD) is the most common cause of chronic liver disease worldwide. Risk factors for NAFLD disease progression and liver-related outcomes remain incompletely understood due to the lack of computational identification methods. The present study sought to design a classification algorithm for NAFLD within the electronic medical record (EMR) for the development of large-scale longitudinal cohorts.
We implemented feature selection using logistic regression with adaptive LASSO. A training set of 620 patients was randomly selected from the Research Patient Data Registry at Partners Healthcare. To assess a true diagnosis for NAFLD we performed chart reviews and considered either a documentation of a biopsy or a clinical diagnosis of NAFLD. We included in our model variables laboratory measurements, diagnosis codes, and concepts extracted from medical notes. Variables with P < 0.05 were included in the multivariable analysis.
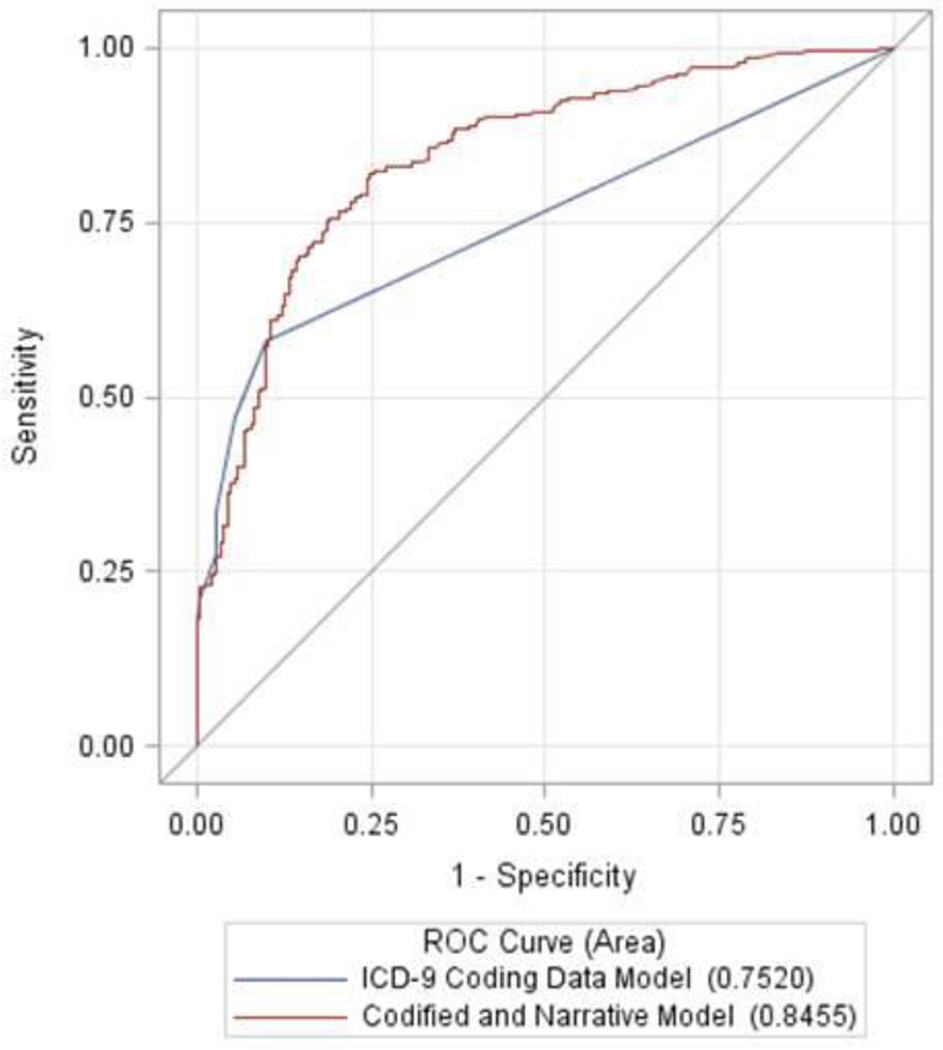
The NAFLD classification algorithm included number of natural language mentions of NAFLD in the EMR, lifetime number of ICD-9 codes for NAFLD, and triglyceride level. This classification algorithm was superior to an algorithm using ICD-9 data alone with AUC of 0.85 versus 0.75 (P < 0.0001) and leads to the creation of a new independent cohort of 8458 individuals with a high probability for NAFLD.
The NAFLD classification algorithm is superior to ICD-9 billing data alone. This approach is simple to develop, deploy, and can be applied across different institutions to create EMR-based cohorts of individuals with NAFLD.
非酒精性脂肪性肝病(NAFLD)是全球慢性肝病最常见的病因。由于缺乏计算识别方法,NAFLD疾病进展及肝脏相关结局的危险因素仍未完全明确。本研究旨在设计一种用于电子病历(EMR)中NAFLD的分类算法,以建立大规模纵向队列。
我们使用具有自适应LASSO的逻辑回归进行特征选择。从合作伙伴医疗保健公司的研究患者数据登记处随机选取620例患者作为训练集。为评估NAFLD的真实诊断,我们进行了病历审查,并将活检记录或NAFLD临床诊断纳入考虑。我们在模型中纳入了实验室测量值、诊断代码以及从医疗记录中提取的概念。P<0.05的变量纳入多变量分析。
NAFLD分类算法包括EMR中NAFLD自然语言提及次数、NAFLD的ICD-9代码终生数量以及甘油三酯水平。该分类算法优于仅使用ICD-9数据的算法,AUC分别为0.85和0.75(P<0.0001),并导致创建了一个由8458名个体组成的新的独立队列,这些个体患NAFLD的可能性很高。
NAFLD分类算法优于单独的ICD-9计费数据。这种方法易于开发、部署,可应用于不同机构,以创建基于EMR的NAFLD个体队列。