Basile Anna O, Verma Anurag, Tang Leigh Anne, Serper Marina, Scanga Andrew, Farrell Ava, Destin Brittney, Carr Rotonya M, Anyanwu-Ofili Anuli, Rajagopal Gunaretnam, Krikhely Abraham, Bessler Marc, Reilly Muredach P, Ritchie Marylyn D, Tatonetti Nicholas P, Wattacheril Julia
Department of Biomedical Informatics, Columbia University, New York, New York, USA.
Department of Computational Biology, New York Genome Center, New York, New York, USA.
Clin Transl Sci. 2025 Jan;18(1):e70105. doi: 10.1111/cts.70105.
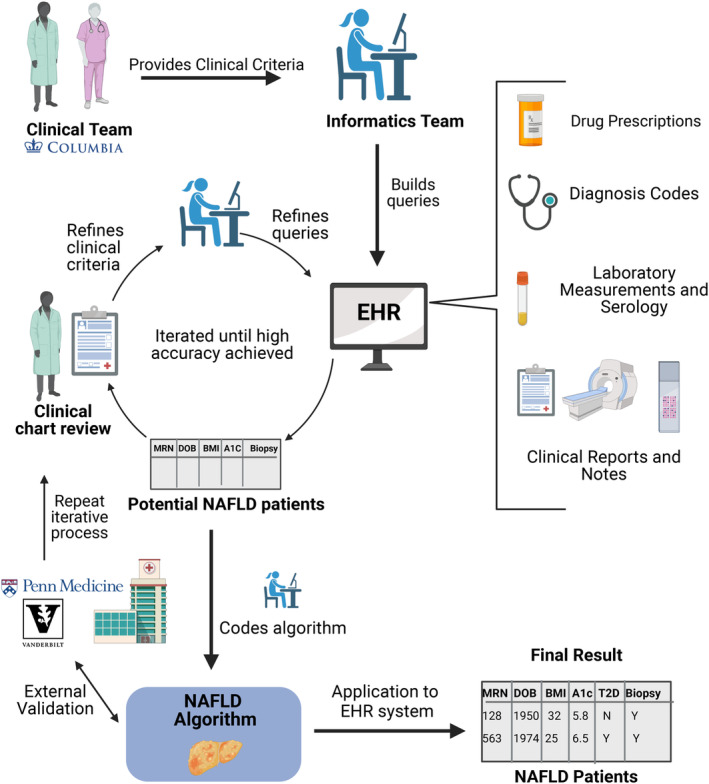
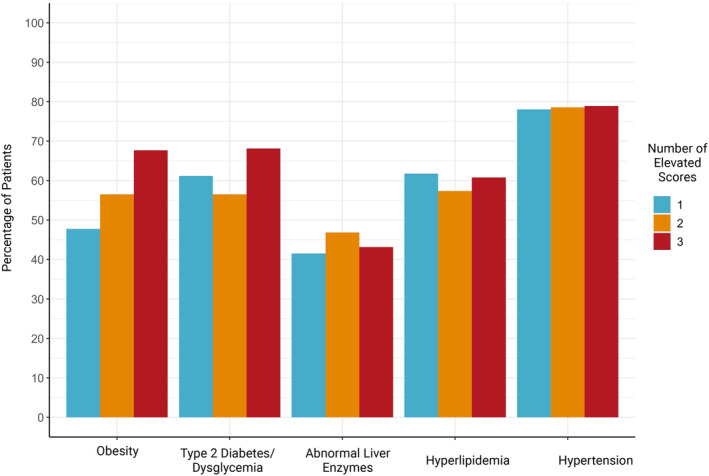
Nonalcoholic fatty liver disease (NAFLD) is the most common global cause of chronic liver disease and remains under-recognized within healthcare systems. Therapeutic interventions are rapidly advancing for its inflammatory phenotype, nonalcoholic steatohepatitis (NASH) at all stages of disease. Diagnosis codes alone fail to recognize and stratify at-risk patients accurately. Our work aims to rapidly identify NAFLD patients within large electronic health record (EHR) databases for automated stratification and targeted intervention based on clinically relevant phenotypes. We present a rule-based phenotyping algorithm for efficient identification of NAFLD patients developed using EHRs from 6.4 million patients at Columbia University Irving Medical Center (CUIMC) and validated at two independent healthcare centers. The algorithm uses the Observational Medical Outcomes Partnership (OMOP) Common Data Model and queries structured and unstructured data elements, including diagnosis codes, laboratory measurements, and radiology and pathology modalities. Our approach identified 16,006 CUIMC NAFLD patients, 10,753 (67%) previously unidentifiable by NAFLD diagnosis codes. Fibrosis scoring on patients without histology identified 943 subjects with scores indicative of advanced fibrosis (FIB-4, APRI, NAFLD-FS). The algorithm was validated at two independent healthcare systems, University of Pennsylvania Health System (UPHS) and Vanderbilt Medical Center (VUMC), where 20,779 and 19,575 NAFLD patients were identified, respectively. Clinical chart review identified a high positive predictive value (PPV) across all healthcare systems: 91% at CUIMC, 75% at UPHS, and 85% at VUMC, and a sensitivity of 79.6%. Our rule-based algorithm provides an accurate, automated approach for rapidly identifying, stratifying, and sub-phenotyping NAFLD patients within a large EHR system.
非酒精性脂肪性肝病(NAFLD)是全球慢性肝病最常见的病因,在医疗保健系统中仍未得到充分认识。针对其炎症表型,即疾病各阶段的非酒精性脂肪性肝炎(NASH),治疗干预措施正在迅速发展。仅靠诊断编码无法准确识别和分层高危患者。我们的工作旨在快速在大型电子健康记录(EHR)数据库中识别NAFLD患者,以便基于临床相关表型进行自动分层和靶向干预。我们提出了一种基于规则的表型分析算法,用于高效识别NAFLD患者,该算法是使用哥伦比亚大学欧文医学中心(CUIMC)640万患者的EHR开发的,并在两个独立的医疗中心进行了验证。该算法使用观察性医疗结果合作组织(OMOP)通用数据模型,并查询结构化和非结构化数据元素,包括诊断编码、实验室测量值以及放射学和病理学检查结果。我们的方法识别出16006例CUIMC的NAFLD患者,其中10753例(67%)此前无法通过NAFLD诊断编码识别。对没有组织学检查的患者进行纤维化评分,识别出943例纤维化评分表明存在晚期纤维化的患者(FIB-4、APRI、NAFLD-FS)。该算法在两个独立的医疗系统——宾夕法尼亚大学医疗系统(UPHS)和范德比尔特医疗中心(VUMC)进行了验证,分别识别出20779例和19575例NAFLD患者。临床病历审查显示,在所有医疗系统中该算法具有较高的阳性预测值(PPV):CUIMC为91%,UPHS为75%,VUMC为85%,敏感性为79.6%。我们基于规则的算法为在大型EHR系统中快速识别、分层和对NAFLD患者进行亚表型分析提供了一种准确的自动化方法。