Andrade G, Ferreira R, Teodoro George, Rocha Leonardo, Saltz Joel H, Kurc Tahsin
Federal University of Minas Gerais.
University of Brasília.
Proc Symp Comput Archit High Perform Comput. 2014 Oct;2014:89-96. doi: 10.1109/SBAC-PAD.2014.15.
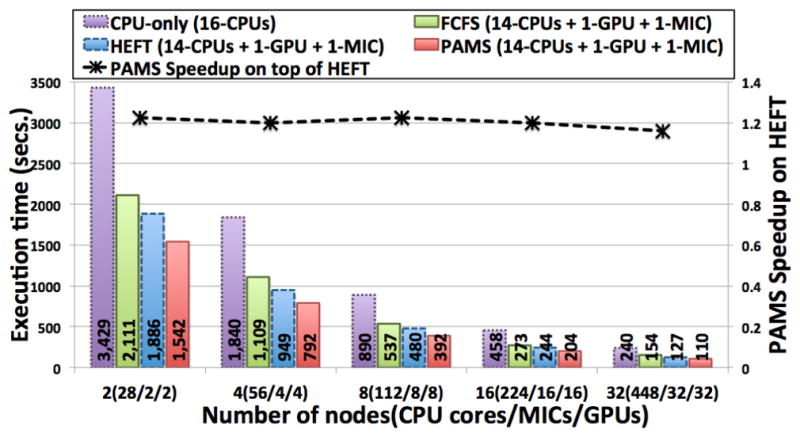
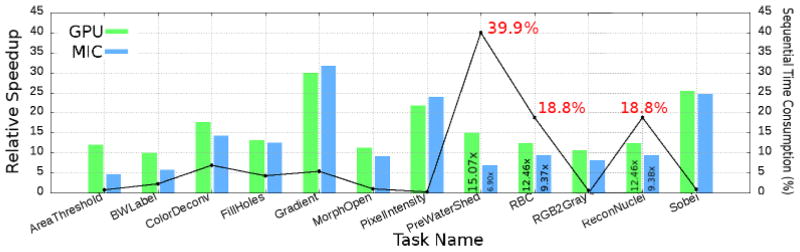
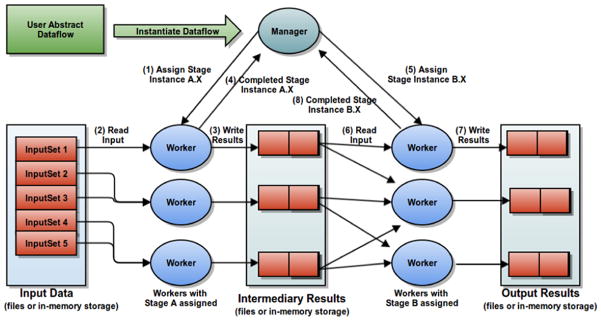
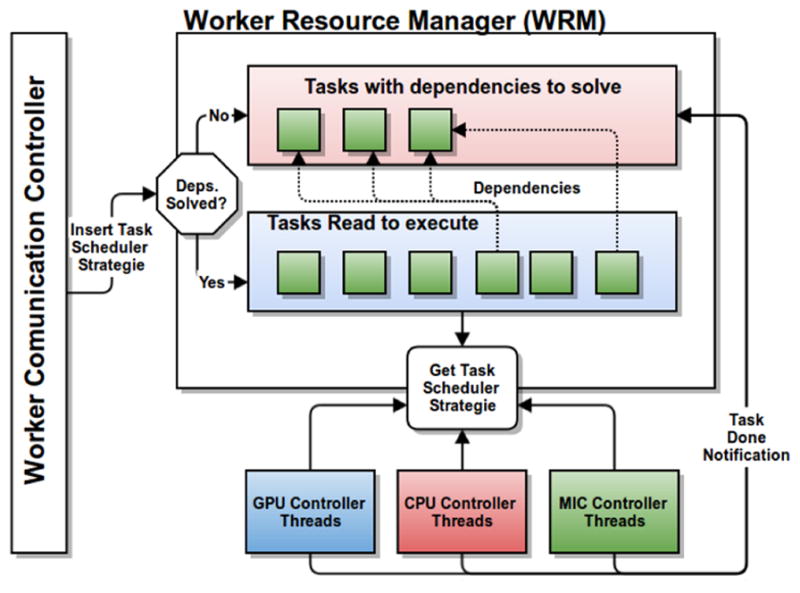
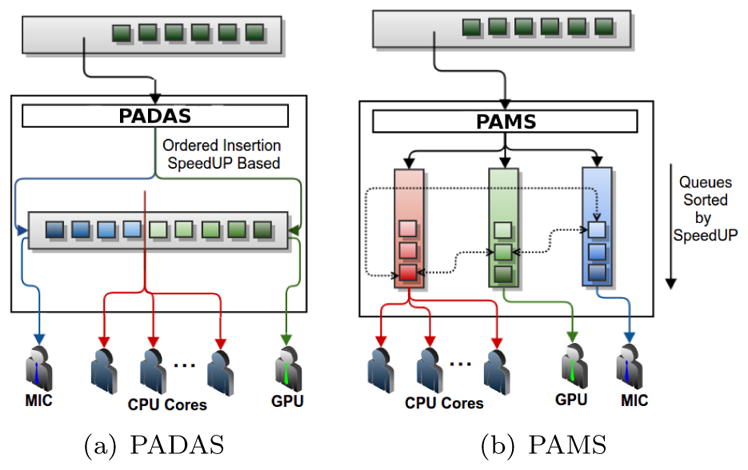
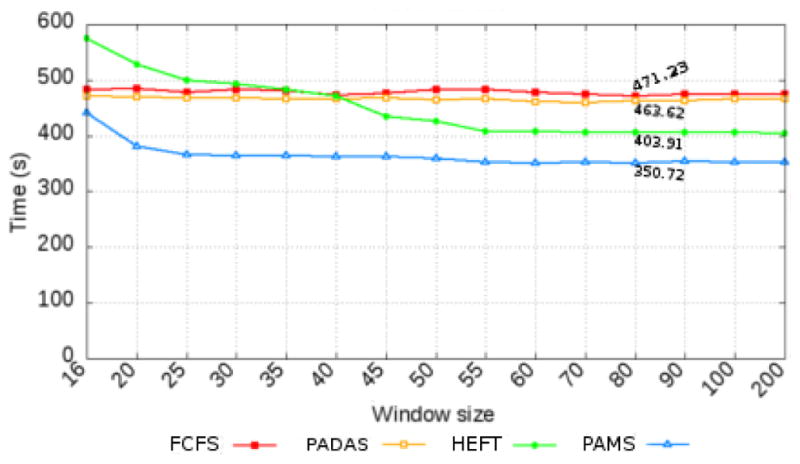
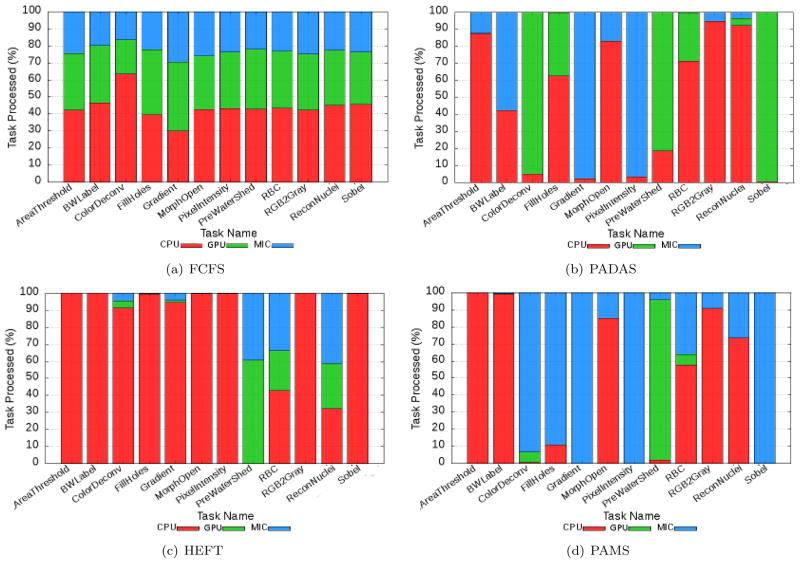
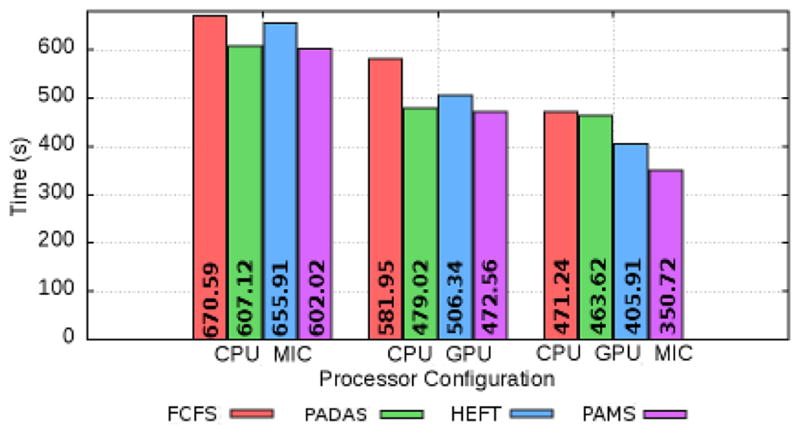
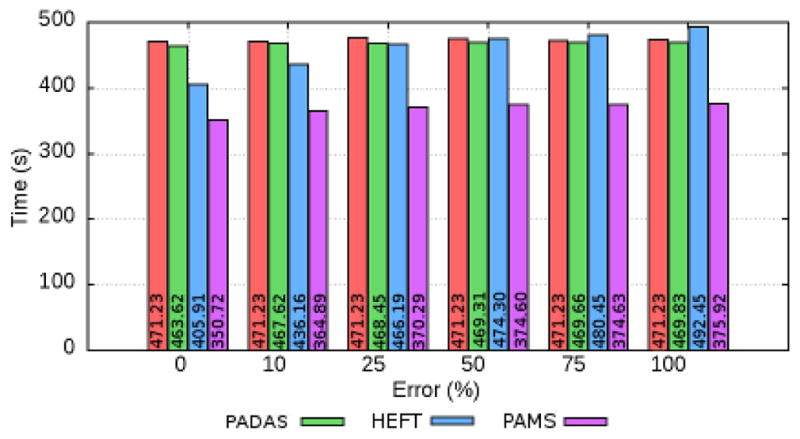
High performance computing is experiencing a major paradigm shift with the introduction of accelerators, such as graphics processing units (GPUs) and Intel Xeon Phi (MIC). These processors have made available a tremendous computing power at low cost, and are transforming machines into hybrid systems equipped with CPUs and accelerators. Although these systems can deliver a very high peak performance, making full use of its resources in real-world applications is a complex problem. Most current applications deployed to these machines are still being executed in a single processor, leaving other devices underutilized. In this paper we explore a scenario in which applications are composed of hierarchical data flow tasks which are allocated to nodes of a distributed memory machine in coarse-grain, but each of them may be composed of several finer-grain tasks which can be allocated to different devices within the node. We propose and implement novel performance aware scheduling techniques that can be used to allocate tasks to devices. We evaluate our techniques using a pathology image analysis application used to investigate brain cancer morphology, and our experimental evaluation shows that the proposed scheduling strategies significantly outperforms other efficient scheduling techniques, such as Heterogeneous Earliest Finish Time - HEFT, in cooperative executions using CPUs, GPUs, and MICs. We also experimentally show that our strategies are less sensitive to inaccuracy in the scheduling input data and that the performance gains are maintained as the application scales.
随着图形处理单元(GPU)和英特尔至强融核(MIC)等加速器的引入,高性能计算正在经历重大的范式转变。这些处理器以低成本提供了巨大的计算能力,并正在将机器转变为配备CPU和加速器的混合系统。尽管这些系统可以提供非常高的峰值性能,但在实际应用中充分利用其资源是一个复杂的问题。当前部署到这些机器上的大多数应用程序仍在单个处理器上执行,导致其他设备未得到充分利用。在本文中,我们探讨了一种场景,即应用程序由分层数据流任务组成,这些任务以粗粒度分配到分布式内存机器的节点,但每个任务可能由几个更细粒度的任务组成,这些细粒度任务可以分配到节点内的不同设备。我们提出并实现了新颖的性能感知调度技术,可用于将任务分配到设备。我们使用用于研究脑癌形态的病理图像分析应用程序评估我们的技术,我们的实验评估表明,在使用CPU、GPU和MIC的协同执行中,所提出的调度策略明显优于其他高效调度技术,如异构最早完成时间(HEFT)。我们还通过实验表明,我们的策略对调度输入数据中的不准确性不太敏感,并且随着应用程序规模的扩大,性能提升得以保持。