Tcheng David K, Nayak Ashwin K, Fowlkes Charless C, Punyasena Surangi W
Illinois Informatics Institute, University of Illinois, Urbana, Illinois, United States of America.
School of Integrative Biology, University of Illinois, Urbana, Illinois, United States of America.
PLoS One. 2016 Feb 11;11(2):e0148879. doi: 10.1371/journal.pone.0148879. eCollection 2016.
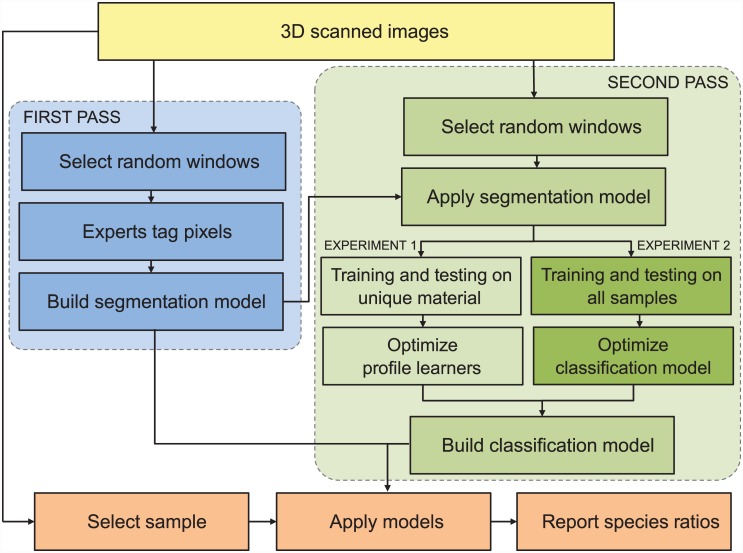
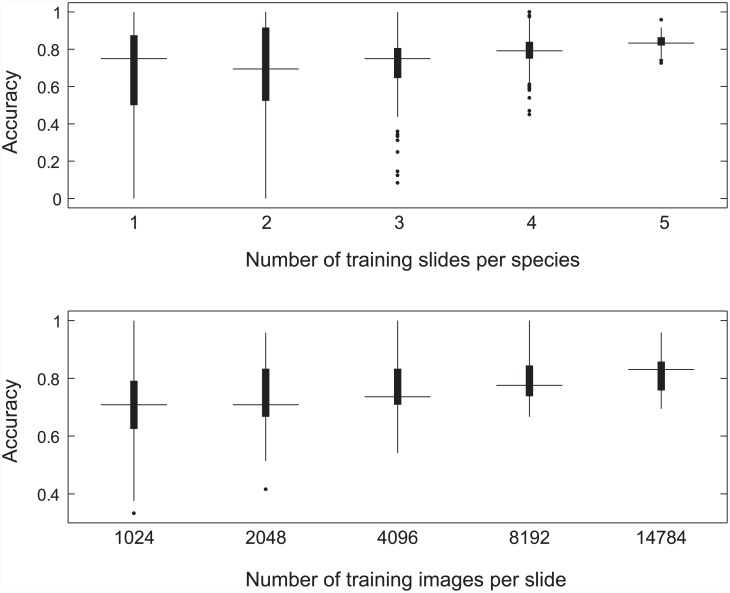
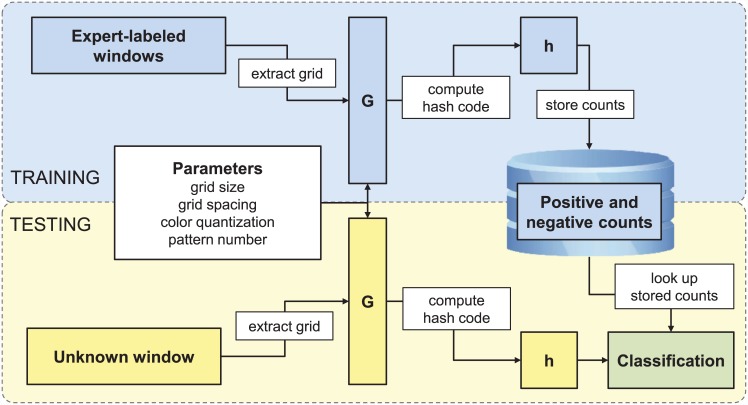
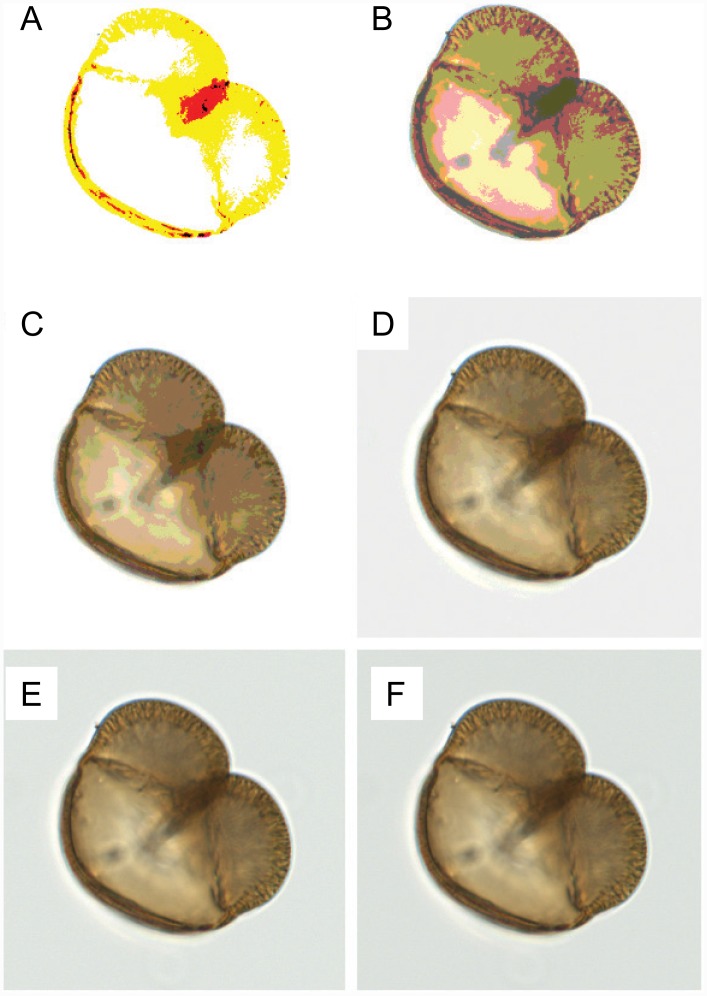
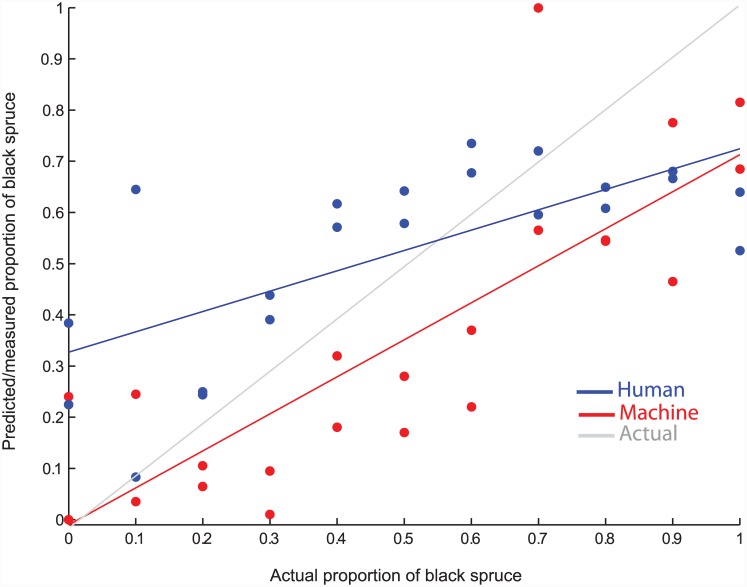
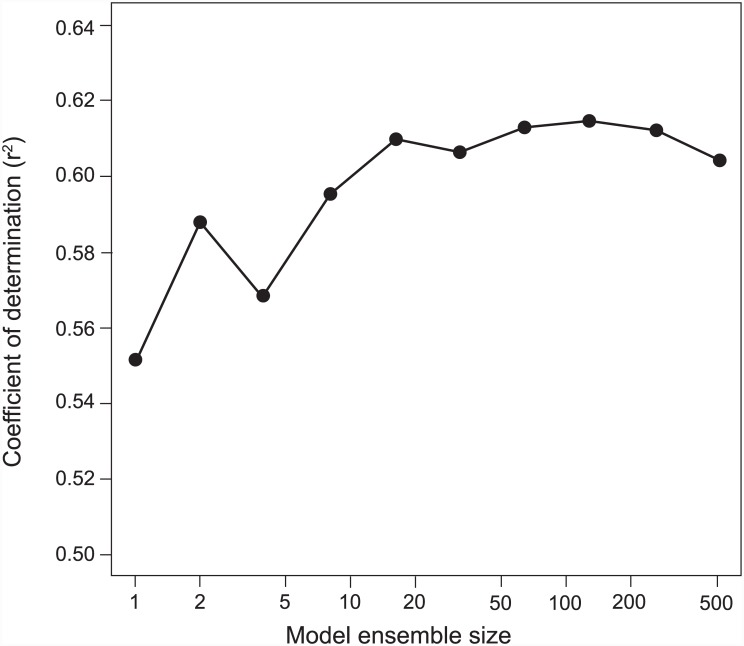
Discriminating between black and white spruce (Picea mariana and Picea glauca) is a difficult palynological classification problem that, if solved, would provide valuable data for paleoclimate reconstructions. We developed an open-source visual recognition software (ARLO, Automated Recognition with Layered Optimization) capable of differentiating between these two species at an accuracy on par with human experts. The system applies pattern recognition and machine learning to the analysis of pollen images and discovers general-purpose image features, defined by simple features of lines and grids of pixels taken at different dimensions, size, spacing, and resolution. It adapts to a given problem by searching for the most effective combination of both feature representation and learning strategy. This results in a powerful and flexible framework for image classification. We worked with images acquired using an automated slide scanner. We first applied a hash-based "pollen spotting" model to segment pollen grains from the slide background. We next tested ARLO's ability to reconstruct black to white spruce pollen ratios using artificially constructed slides of known ratios. We then developed a more scalable hash-based method of image analysis that was able to distinguish between the pollen of black and white spruce with an estimated accuracy of 83.61%, comparable to human expert performance. Our results demonstrate the capability of machine learning systems to automate challenging taxonomic classifications in pollen analysis, and our success with simple image representations suggests that our approach is generalizable to many other object recognition problems.
区分黑云杉和白云杉(黑云杉和白云杉)是一个困难的孢粉学分类问题,如果解决,将为古气候重建提供有价值的数据。我们开发了一种开源视觉识别软件(ARLO,分层优化自动识别),能够以与人类专家相当的准确率区分这两个物种。该系统将模式识别和机器学习应用于花粉图像分析,并发现通用图像特征,这些特征由在不同维度、大小、间距和分辨率下拍摄的像素线和网格的简单特征定义。它通过搜索特征表示和学习策略的最有效组合来适应给定问题。这产生了一个强大而灵活的图像分类框架。我们使用自动幻灯片扫描仪获取的图像进行工作。我们首先应用基于哈希的“花粉识别”模型从幻灯片背景中分割出花粉粒。接下来,我们测试了ARLO使用已知比例的人工构建幻灯片重建黑云杉与白云杉花粉比例的能力。然后,我们开发了一种更具可扩展性的基于哈希的图像分析方法,能够以估计83.61%的准确率区分黑云杉和白云杉的花粉,与人类专家的表现相当。我们的结果证明了机器学习系统在花粉分析中实现具有挑战性的分类学分类自动化的能力,并且我们在简单图像表示方面的成功表明我们的方法可以推广到许多其他物体识别问题。