Xia Junfeng, Yue Zhenyu, Di Yunqiang, Zhu Xiaolei, Zheng Chun-Hou
Key Laboratory of Intelligent Computing and Signal Processing of Ministry of Education, Institute of Health Sciences, Anhui University, Hefei, Anhui 230601, China.
Co-Innovation Center for Information Supply and Assurance Technology, School of Computer Science and Technology, Anhui University, Hefei, Anhui 230601, China.
Oncotarget. 2016 Apr 5;7(14):18065-75. doi: 10.18632/oncotarget.7695.
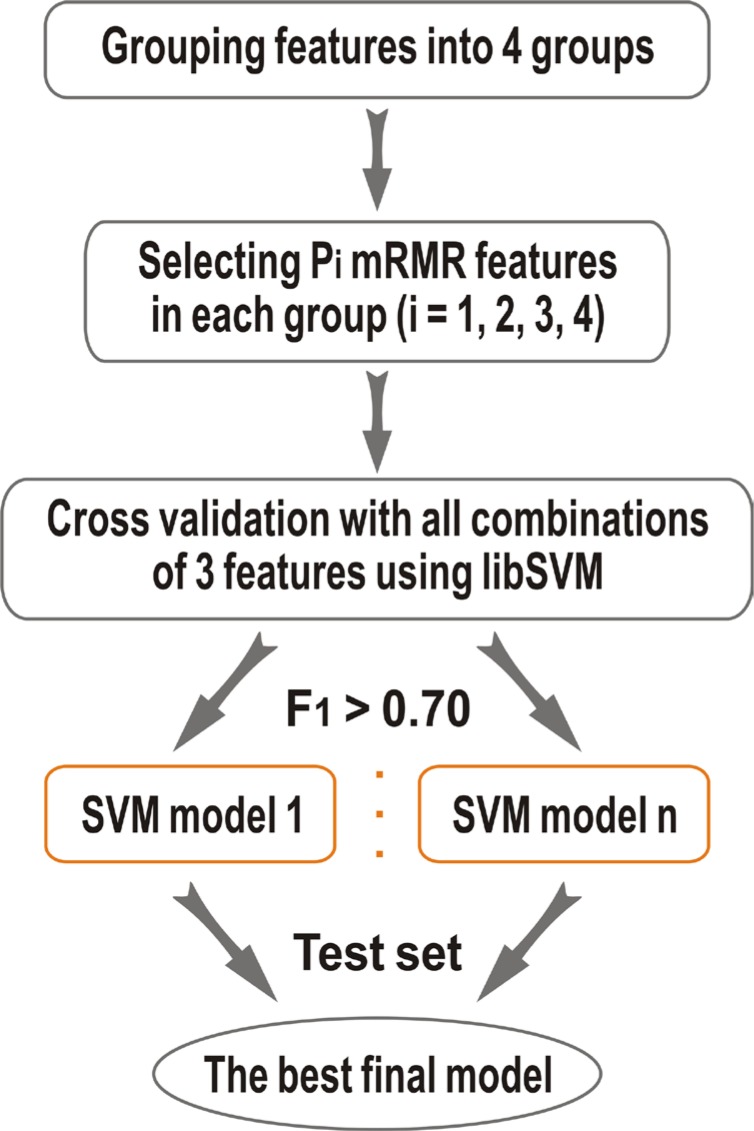
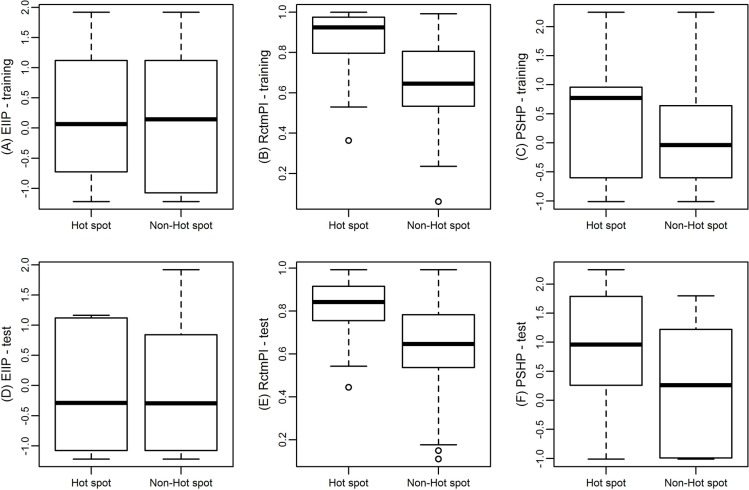
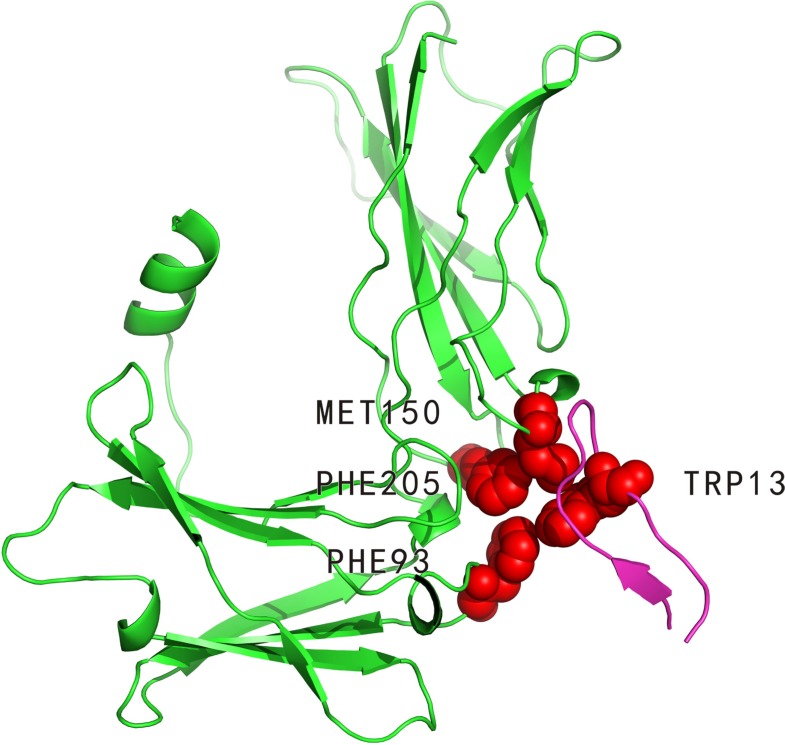
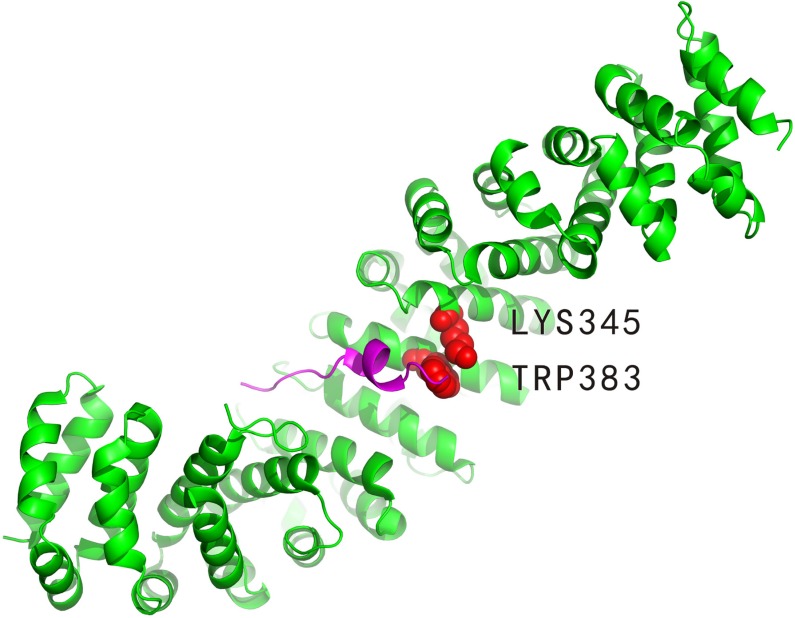
The identification of hot spots, a small subset of protein interfaces that accounts for the majority of binding free energy, is becoming more important for the research of drug design and cancer development. Based on our previous methods (APIS and KFC2), here we proposed a novel hot spot prediction method. For each hot spot residue, we firstly constructed a wide variety of 108 sequence, structural, and neighborhood features to characterize potential hot spot residues, including conventional ones and new one (pseudo hydrophobicity) exploited in this study. We then selected 3 top-ranking features that contribute the most in the classification by a two-step feature selection process consisting of minimal-redundancy-maximal-relevance algorithm and an exhaustive search method. We used support vector machines to build our final prediction model. When testing our model on an independent test set, our method showed the highest F1-score of 0.70 and MCC of 0.46 comparing with the existing state-of-the-art hot spot prediction methods. Our results indicate that these features are more effective than the conventional features considered previously, and that the combination of our and traditional features may support the creation of a discriminative feature set for efficient prediction of hot spots in protein interfaces.
热点是蛋白质界面的一个小子集,占结合自由能的大部分,其识别对于药物设计和癌症发展的研究变得越来越重要。基于我们之前的方法(APIS和KFC2),我们在此提出了一种新颖的热点预测方法。对于每个热点残基,我们首先构建了108种广泛的序列、结构和邻域特征来表征潜在的热点残基,包括本研究中利用的传统特征和新特征(伪疏水性)。然后,我们通过一个由最小冗余最大相关性算法和穷举搜索方法组成的两步特征选择过程,选择了在分类中贡献最大的3个顶级特征。我们使用支持向量机构建最终的预测模型。当在独立测试集上测试我们的模型时,与现有的最先进热点预测方法相比,我们的方法显示出最高的F1分数0.70和MCC 0.46。我们的结果表明,这些特征比之前考虑的传统特征更有效,并且我们的特征与传统特征的组合可能有助于创建一个有判别力的特征集,以有效地预测蛋白质界面中的热点。