Sontrop Herman M J, Reinders Marcel J T, Moerland Perry D
Molecular Diagnostics Department, Philips Research, High Tech Campus 11, Eindhoven, 5656 AE, The Netherlands.
Friss Fraud and Risk Solutions, Orteliuslaan 15, Utrecht, 3528 BA, The Netherlands.
BMC Med Genomics. 2016 Jun 3;9(1):26. doi: 10.1186/s12920-016-0185-6.
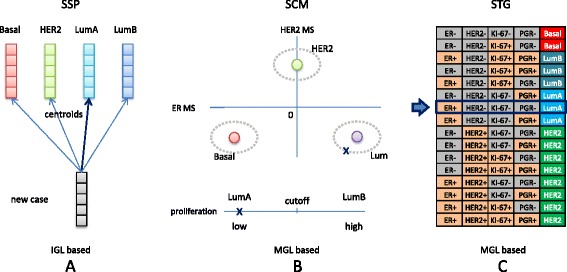
At the molecular level breast cancer comprises a heterogeneous set of subtypes associated with clear differences in gene expression and clinical outcomes. Single sample predictors (SSPs) are built via a two-stage approach consisting of clustering and subtype predictor construction based on the cluster labels of individual cases. SSPs have been criticized because their subtype assignments for the same samples were only moderately concordant (Cohen's κ<0.6).
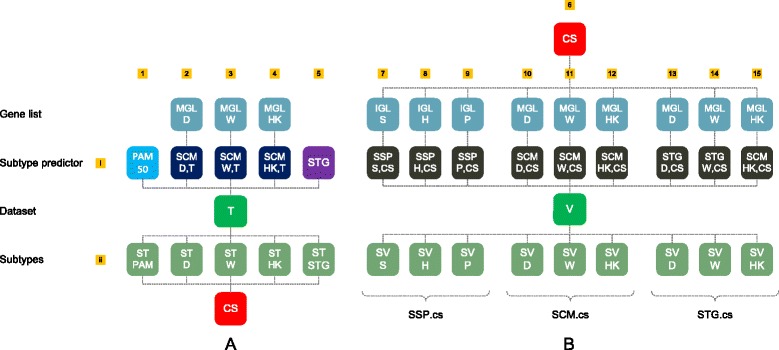
We propose a semi-supervised approach where for five datasets, consensus sets were constructed consisting of those samples that were concordantly subtyped by a number of different predictors. Next, nine subtype predictors - three SSPs, three subtype classification models (SCMs) and three novel rule-based predictors based on the St. Gallen surrogate intrinsic subtype definitions (STGs) - were constructed on the five consensus sets and their associated consensus subtype labels. The predictors were validated on a compendium of over 4,000 uniformly preprocessed Affymetrix microarrays. Concordance between subtype predictors was assessed using Cohen's kappa statistic.
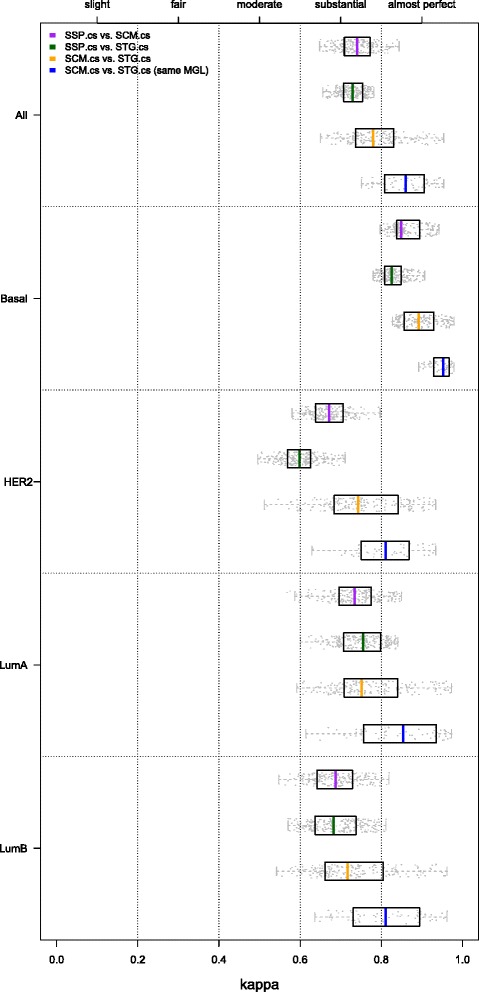
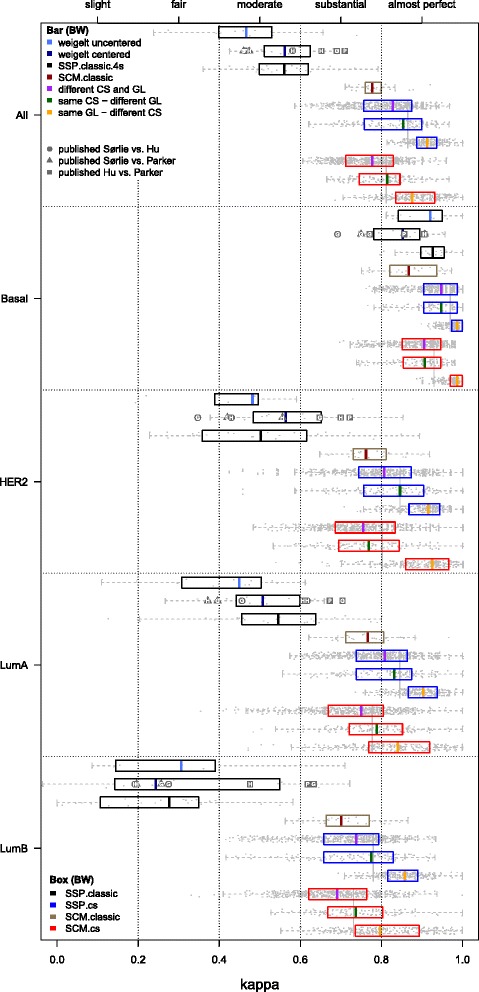
In this standardized setup, subtype predictors of the same type (either SCM, SSP, or STG) but with a different gene list and/or consensus training set were associated with almost perfect levels of agreement (median κ>0.8). Interestingly, for a given predictor type a change in consensus set led to higher concordance than a change to another gene list. The more challenging scenario where the predictor type, gene list and training set were all different resulted in predictors with only substantial levels of concordance (median κ=0.74) on independent validation data.
Our results demonstrate that for a given subtype predictor type stringent standardization of the preprocessing stage, combined with carefully devised consensus training sets, leads to predictors that show almost perfect levels of concordance. However, predictors of a different type are only substantially concordant, despite reaching almost perfect levels of concordance on training data.
在分子水平上,乳腺癌由一组异质性亚型组成,这些亚型在基因表达和临床结果上存在明显差异。单样本预测器(SSP)通过两阶段方法构建,包括聚类以及基于个体病例的聚类标签构建亚型预测器。SSP受到了批评,因为它们对相同样本的亚型分配仅具有中等程度的一致性(科恩kappa系数<0.6)。
我们提出了一种半监督方法,对于五个数据集,构建了由许多不同预测器一致分类的样本组成的共识集。接下来,在五个共识集及其相关的共识亚型标签上构建了九个亚型预测器——三个SSP、三个亚型分类模型(SCM)和三个基于圣加仑替代内在亚型定义(STG)的新型基于规则的预测器。这些预测器在超过4000个经过统一预处理的Affymetrix微阵列的汇编数据集上进行了验证。使用科恩kappa统计量评估亚型预测器之间的一致性。
在这种标准化设置中,相同类型(SCM、SSP或STG)但具有不同基因列表和/或共识训练集的亚型预测器具有几乎完美的一致性水平(中位数kappa>0.8)。有趣的是,对于给定的预测器类型,共识集的变化导致的一致性高于基因列表的变化。预测器类型、基因列表和训练集都不同的更具挑战性的情况导致预测器在独立验证数据上仅具有较高水平的一致性(中位数kappa = 0.74)。
我们的结果表明,对于给定的亚型预测器类型,预处理阶段的严格标准化,结合精心设计的共识训练集,会产生显示几乎完美一致性水平的预测器。然而,不同类型的预测器仅具有较高的一致性,尽管在训练数据上达到了几乎完美的一致性水平。