Rumshisky A, Ghassemi M, Naumann T, Szolovits P, Castro V M, McCoy T H, Perlis R H
MIT Computer Science and Artificial Intelligence Laboratory, Cambridge, MA, USA.
Department of Computer Science, University of Massachusetts Lowell, Lowell, MA, USA.
Transl Psychiatry. 2016 Oct 18;6(10):e921. doi: 10.1038/tp.2015.182.
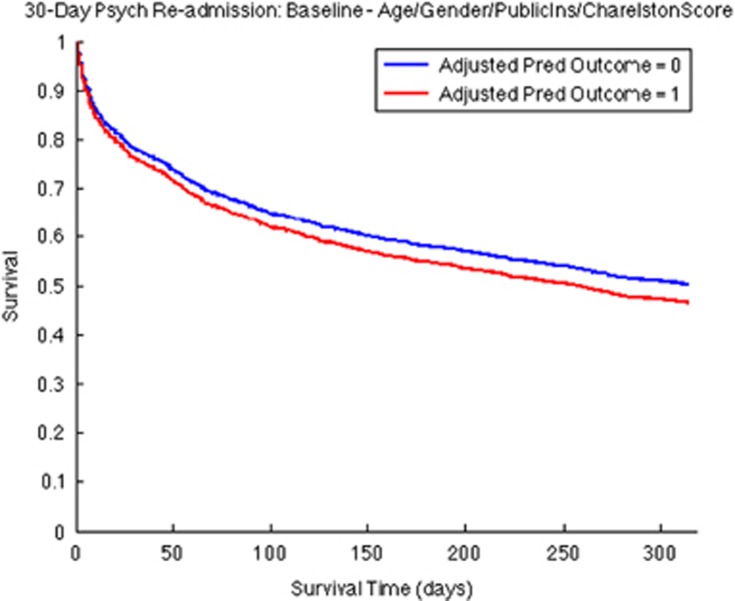
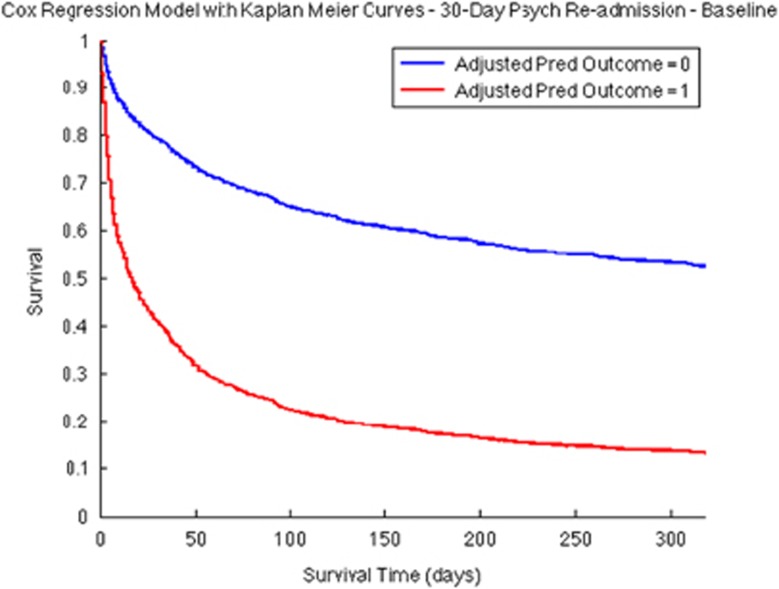
The ability to predict psychiatric readmission would facilitate the development of interventions to reduce this risk, a major driver of psychiatric health-care costs. The symptoms or characteristics of illness course necessary to develop reliable predictors are not available in coded billing data, but may be present in narrative electronic health record (EHR) discharge summaries. We identified a cohort of individuals admitted to a psychiatric inpatient unit between 1994 and 2012 with a principal diagnosis of major depressive disorder, and extracted inpatient psychiatric discharge narrative notes. Using these data, we trained a 75-topic Latent Dirichlet Allocation (LDA) model, a form of natural language processing, which identifies groups of words associated with topics discussed in a document collection. The cohort was randomly split to derive a training (70%) and testing (30%) data set, and we trained separate support vector machine models for baseline clinical features alone, baseline features plus common individual words and the above plus topics identified from the 75-topic LDA model. Of 4687 patients with inpatient discharge summaries, 470 were readmitted within 30 days. The 75-topic LDA model included topics linked to psychiatric symptoms (suicide, severe depression, anxiety, trauma, eating/weight and panic) and major depressive disorder comorbidities (infection, postpartum, brain tumor, diarrhea and pulmonary disease). By including LDA topics, prediction of readmission, as measured by area under receiver-operating characteristic curves in the testing data set, was improved from baseline (area under the curve 0.618) to baseline+1000 words (0.682) to baseline+75 topics (0.784). Inclusion of topics derived from narrative notes allows more accurate discrimination of individuals at high risk for psychiatric readmission in this cohort. Topic modeling and related approaches offer the potential to improve prediction using EHRs, if generalizability can be established in other clinical cohorts.
预测精神科再入院的能力将有助于开发降低这种风险的干预措施,而这种风险是精神科医疗成本的主要驱动因素。开发可靠预测指标所需的疾病过程的症状或特征在编码计费数据中不可用,但可能存在于叙述性电子健康记录(EHR)出院小结中。我们确定了一组在1994年至2012年间入住精神科住院单元且主要诊断为重度抑郁症的个体,并提取了住院精神科出院叙述性记录。利用这些数据,我们训练了一个75主题的潜在狄利克雷分配(LDA)模型,这是一种自然语言处理形式,可识别与文档集中讨论的主题相关的词群。该队列被随机分为训练(70%)和测试(30%)数据集,我们分别训练了单独的支持向量机模型,分别用于仅基于基线临床特征、基线特征加常见个体词以及上述特征加从75主题LDA模型中识别出的主题。在4687例有住院出院小结的患者中,470例在30天内再次入院。75主题LDA模型包括与精神症状(自杀、重度抑郁、焦虑、创伤、饮食/体重和恐慌)以及重度抑郁症合并症(感染、产后、脑肿瘤、腹泻和肺部疾病)相关的主题。通过纳入LDA主题,在测试数据集中,用受试者操作特征曲线下面积衡量的再入院预测从基线(曲线下面积0.618)提高到基线+1000个词(0.682),再到基线+75个主题(0.784)。纳入从叙述性记录中得出的主题能够更准确地区分该队列中精神科再入院高风险个体。如果能在其他临床队列中建立可推广性,主题建模及相关方法有望利用电子健康记录改善预测。