Hassani-Pak Keywan, Castellote Martin, Esch Maria, Hindle Matthew, Lysenko Artem, Taubert Jan, Rawlings Christopher
Rothamsted Research, Department of Computational and Systems Biology, UK.
Rothamsted Research, Department of Computational and Systems Biology, UK; INTA EEA-Balcarce, Laboratory of Agrobiotechnology, Argentina.
Appl Transl Genom. 2016 Nov 2;11:18-26. doi: 10.1016/j.atg.2016.10.003. eCollection 2016 Dec.
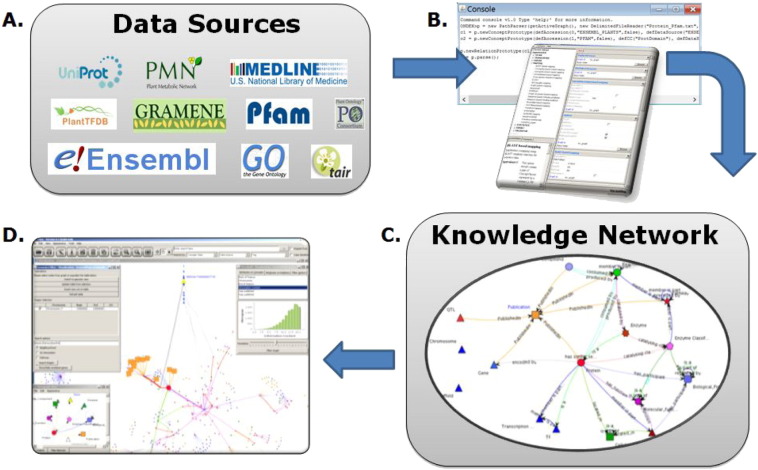
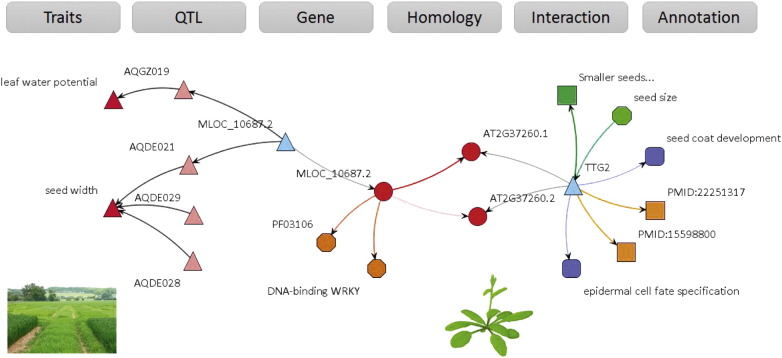
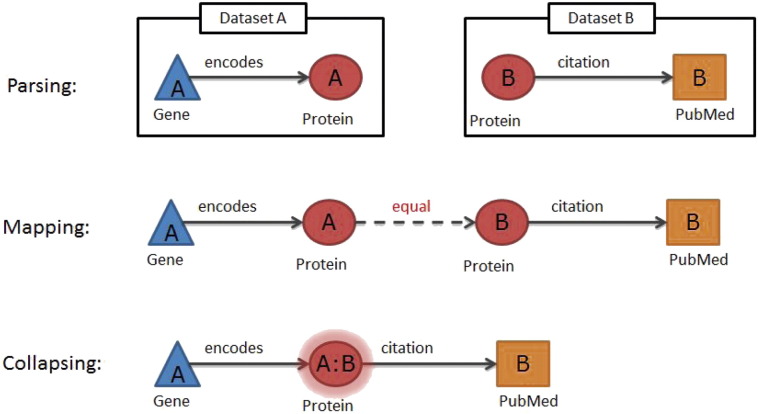
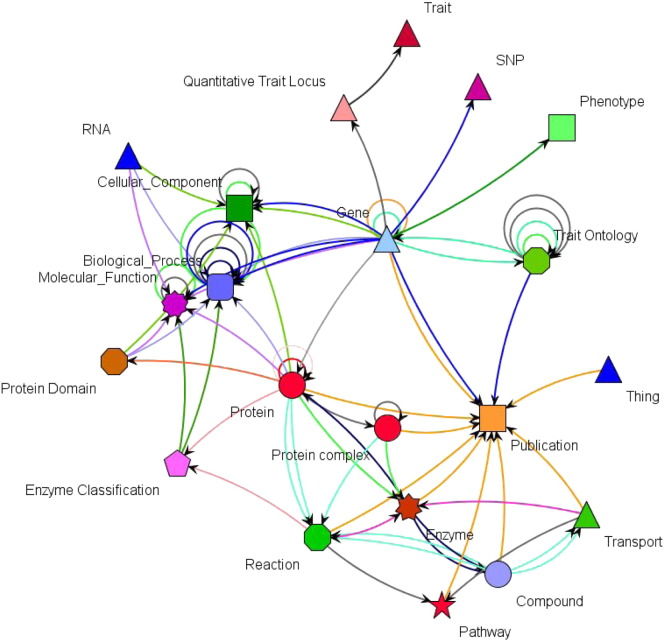
The chances of raising crop productivity to enhance global food security would be greatly improved if we had a complete understanding of all the biological mechanisms that underpinned traits such as crop yield, disease resistance or nutrient and water use efficiency. With more crop genomes emerging all the time, we are nearer having the basic information, at the gene-level, to begin assembling crop gene catalogues and using data from other plant species to understand how the genes function and how their interactions govern crop development and physiology. Unfortunately, the task of creating such a complete knowledge base of gene functions, interaction networks and trait biology is technically challenging because the relevant data are dispersed in myriad databases in a variety of data formats with variable quality and coverage. In this paper we present a general approach for building genome-scale knowledge networks that provide a unified representation of heterogeneous but interconnected datasets to enable effective knowledge mining and gene discovery. We describe the datasets and outline the methods, workflows and tools that we have developed for creating and visualising these networks for the major crop species, wheat and barley. We present the global characteristics of such knowledge networks and with an example linking a seed size phenotype to a barley WRKY transcription factor orthologous to TTG2 from Arabidopsis, we illustrate the value of integrated data in biological knowledge discovery. The software we have developed (www.ondex.org) and the knowledge resources (http://knetminer.rothamsted.ac.uk) we have created are all open-source and provide a first step towards systematic and evidence-based gene discovery in order to facilitate crop improvement.
如果我们能够全面了解支撑作物产量、抗病性或养分及水分利用效率等性状的所有生物学机制,提高作物生产力以增强全球粮食安全的可能性将大大增加。随着越来越多的作物基因组不断涌现,我们在基因层面上越来越接近拥有基础信息,从而开始构建作物基因目录,并利用来自其他植物物种的数据来了解基因的功能以及它们的相互作用如何控制作物的发育和生理过程。不幸的是,创建这样一个关于基因功能、相互作用网络和性状生物学的完整知识库在技术上具有挑战性,因为相关数据分散在众多数据库中,数据格式多样,质量和覆盖范围也各不相同。在本文中,我们提出了一种构建基因组规模知识网络的通用方法,该方法能够统一表示异构但相互关联的数据集,以实现有效的知识挖掘和基因发现。我们描述了数据集,并概述了我们为主要作物小麦和大麦创建和可视化这些网络所开发的方法、工作流程和工具。我们展示了此类知识网络的全局特征,并通过一个将种子大小表型与拟南芥TTG2直系同源的大麦WRKY转录因子相联系的例子,说明了整合数据在生物知识发现中的价值。我们开发的软件(www.ondex.org)和创建的知识资源(http://knetminer.rothamsted.ac.uk)都是开源的,为基于系统和证据的基因发现迈出了第一步,以促进作物改良。