Ivamoto Suzana Tiemi, Reis Osvaldo, Domingues Douglas Silva, Dos Santos Tiago Benedito, de Oliveira Fernanda Freitas, Pot David, Leroy Thierry, Vieira Luiz Gonzaga Esteves, Carazzolle Marcelo Falsarella, Pereira Gonçalo Amarante Guimarães, Pereira Luiz Filipe Protasio
Programa de Pós-Graduação em Genética e Biologia Molecular, Centro de Ciências Biológicas, Universidade Estadual de Londrina (UEL), Londrina, Brazil.
Laboratório de Biotecnologia Vegetal, Instituto Agronômico do Paraná (IAPAR), Londrina, Brazil.
PLoS One. 2017 Jan 9;12(1):e0169595. doi: 10.1371/journal.pone.0169595. eCollection 2017.
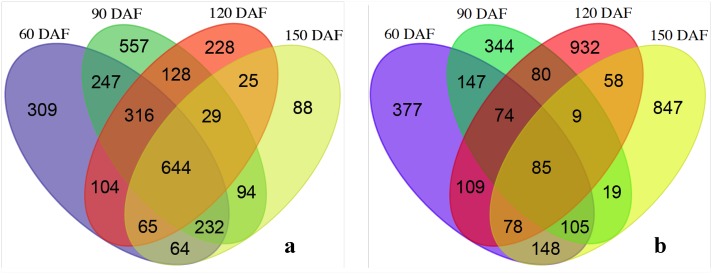
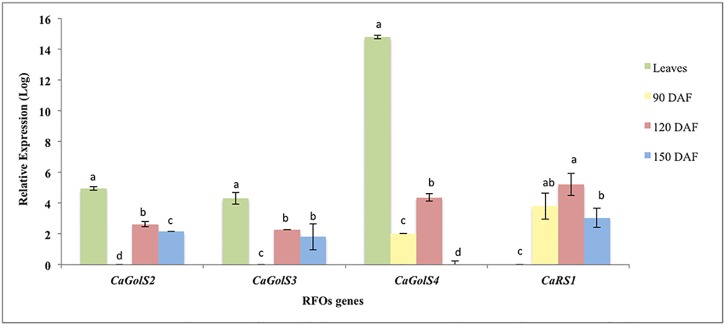
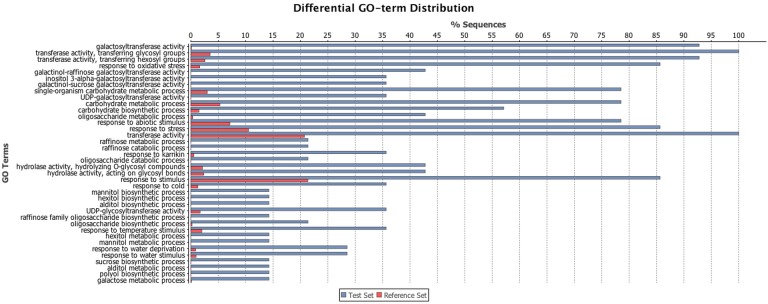
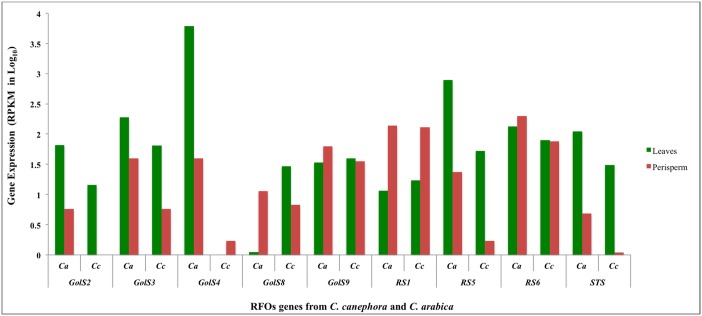
Coffea arabica L. is an important crop in several developing countries. Despite its economic importance, minimal transcriptome data are available for fruit tissues, especially during fruit development where several compounds related to coffee quality are produced. To understand the molecular aspects related to coffee fruit and grain development, we report a large-scale transcriptome analysis of leaf, flower and perisperm fruit tissue development. Illumina sequencing yielded 41,881,572 high-quality filtered reads. De novo assembly generated 65,364 unigenes with an average length of 1,264 bp. A total of 24,548 unigenes were annotated as protein coding genes, including 12,560 full-length sequences. In the annotation process, we identified nine candidate genes related to the biosynthesis of raffinose family oligossacarides (RFOs). These sugars confer osmoprotection and are accumulated during initial fruit development. Four genes from this pathway had their transcriptional pattern validated by quantitative reverse transcription polymerase chain reaction (qRT-PCR). Furthermore, we identified ~24,000 putative target sites for microRNAs (miRNAs) and 134 putative transcriptionally active transposable elements (TE) sequences in our dataset. This C. arabica transcriptomic atlas provides an important step for identifying candidate genes related to several coffee metabolic pathways, especially those related to fruit chemical composition and therefore beverage quality. Our results are the starting point for enhancing our knowledge about the coffee genes that are transcribed during the flowering and initial fruit development stages.
阿拉伯咖啡是几个发展中国家的重要作物。尽管其具有经济重要性,但关于果实组织的转录组数据却极少,尤其是在果实发育期间,此时会产生几种与咖啡品质相关的化合物。为了了解与咖啡果实和种子发育相关的分子层面,我们报告了对叶片、花朵和胚乳果实组织发育的大规模转录组分析。Illumina测序产生了41,881,572条高质量过滤后的 reads。从头组装生成了65,364个单基因,平均长度为1,264 bp。共有24,548个单基因被注释为蛋白质编码基因,其中包括12,560个全长序列。在注释过程中,我们鉴定出9个与棉子糖家族寡糖(RFOs)生物合成相关的候选基因。这些糖类具有渗透保护作用,并在果实发育初期积累。该途径中的4个基因通过定量逆转录聚合酶链反应(qRT-PCR)验证了其转录模式。此外,我们在数据集中鉴定出约24,000个假定的微小RNA(miRNA)靶位点和134个假定的转录活性转座元件(TE)序列。这个阿拉伯咖啡转录组图谱为鉴定与几种咖啡代谢途径相关的候选基因迈出了重要一步,尤其是那些与果实化学成分以及因此与饮品质量相关的基因。我们的结果是增强我们对在开花和果实发育初期转录的咖啡基因知识的起点。