Vaser Robert, Sović Ivan, Nagarajan Niranjan, Šikić Mile
Department of Electronic Systems and Information Processing, University of Zagreb, Faculty of Electrical Engineering and Computing, 10000 Zagreb, Croatia.
Centre for Informatics and Computing, Ruđer Bošković Institute, 10000 Zagreb, Croatia.
Genome Res. 2017 May;27(5):737-746. doi: 10.1101/gr.214270.116. Epub 2017 Jan 18.
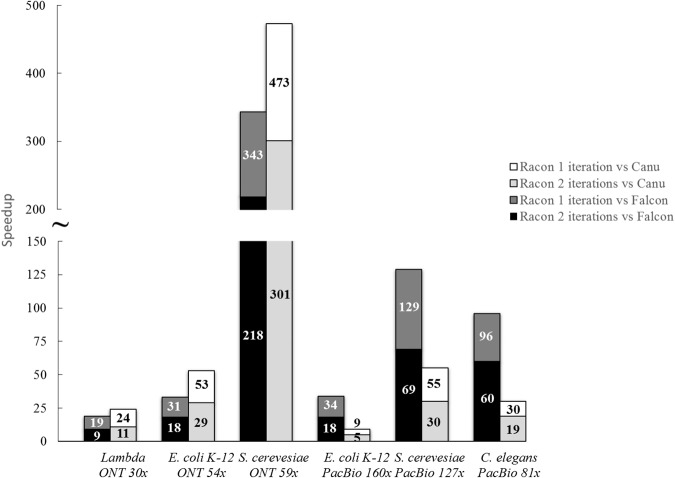
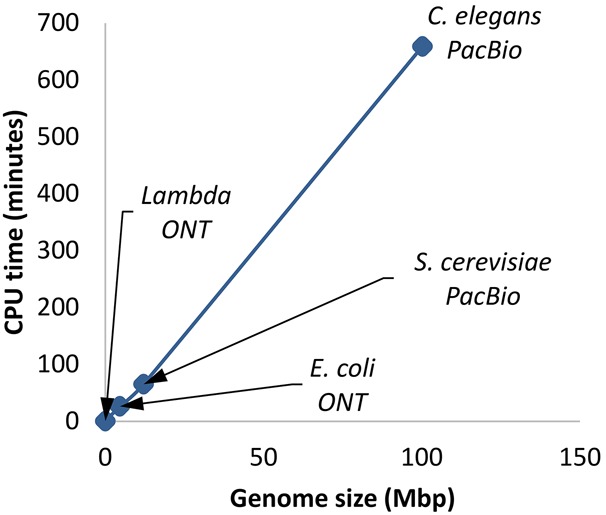
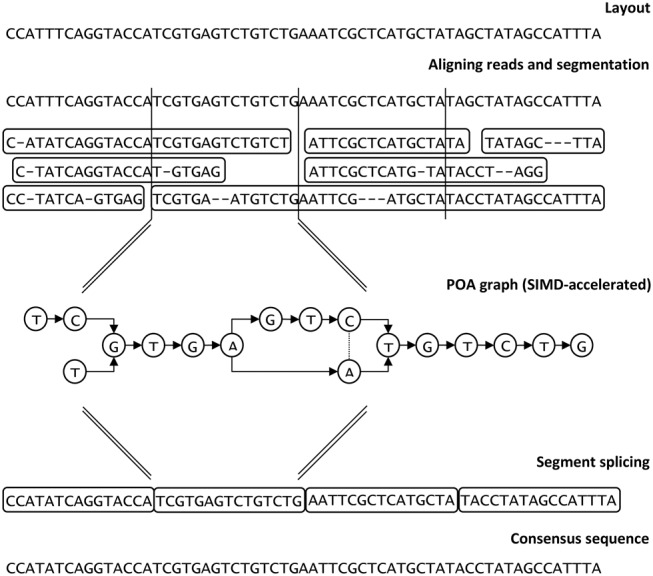
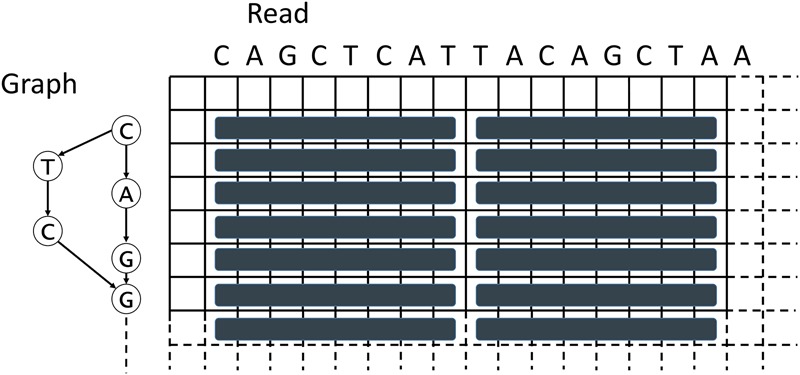
The assembly of long reads from Pacific Biosciences and Oxford Nanopore Technologies typically requires resource-intensive error-correction and consensus-generation steps to obtain high-quality assemblies. We show that the error-correction step can be omitted and that high-quality consensus sequences can be generated efficiently with a SIMD-accelerated, partial-order alignment-based, stand-alone consensus module called Racon. Based on tests with PacBio and Oxford Nanopore data sets, we show that Racon coupled with miniasm enables consensus genomes with similar or better quality than state-of-the-art methods while being an order of magnitude faster.
来自太平洋生物科学公司(Pacific Biosciences)和牛津纳米孔技术公司(Oxford Nanopore Technologies)的长读长序列组装通常需要资源密集型的纠错和生成一致序列步骤,以获得高质量的组装结果。我们表明,可以省略纠错步骤,并且使用一个名为Racon的基于单指令多数据(SIMD)加速、基于偏序比对的独立一致序列模块,能够高效地生成高质量的一致序列。基于对PacBio和牛津纳米孔数据集的测试,我们表明,Racon与miniasm相结合,能够生成质量与现有最先进方法相似或更好的一致基因组,同时速度快一个数量级。